Download as PDF, PPTX




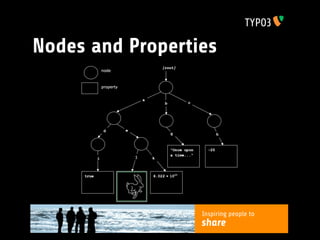














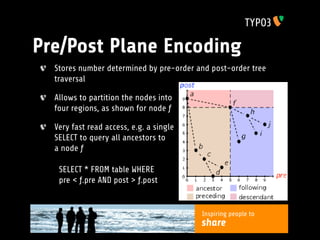












The document discusses the implementation of a JSR-283 content repository (CR) in PHP, highlighting the need for a PHP-based solution as there are currently no standalone implementations. It emphasizes the advantages of CRs, such as flexible data structures and security enforcement, while outlining the development goals for a TYPO3 content repository that prioritizes compatibility with the TYPO3 CMS. Additionally, it covers the planned API porting, data storage techniques, performance considerations, and future enhancements to align with JSR-283 specifications.
































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







