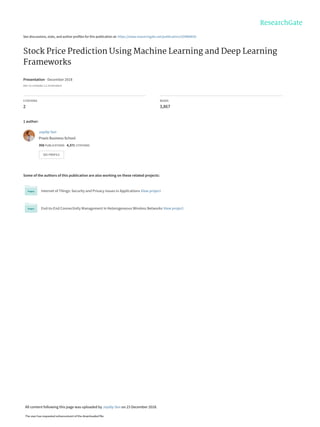
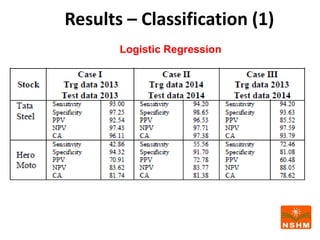
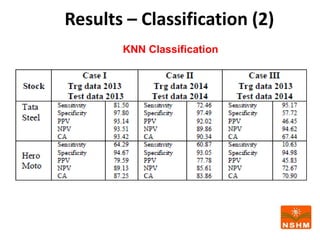
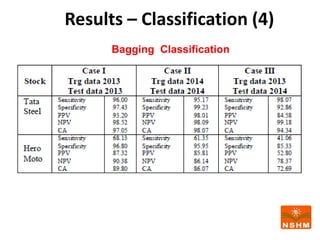
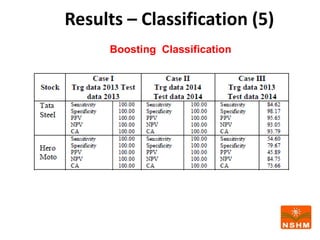
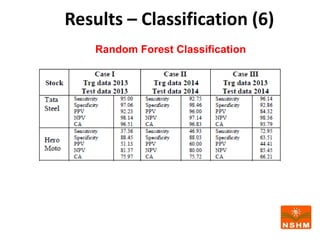
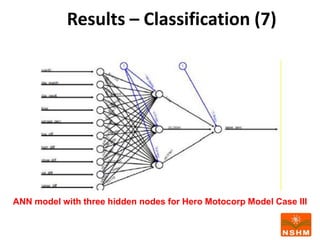
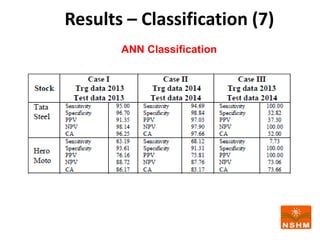
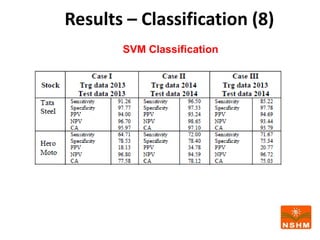
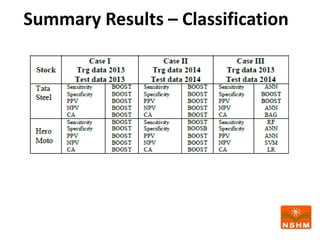
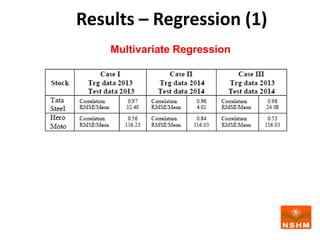
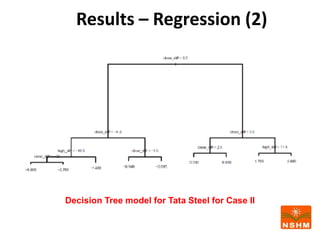
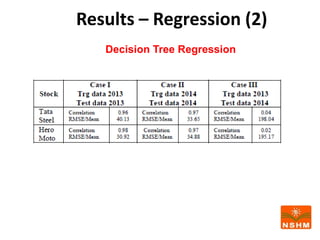
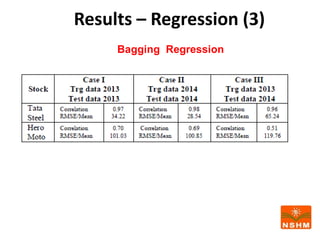
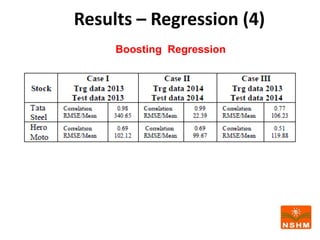
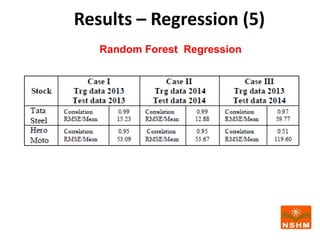
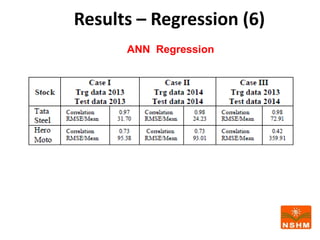
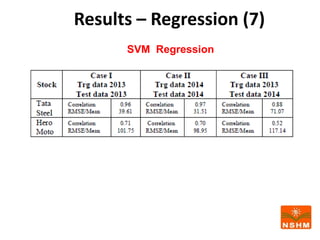
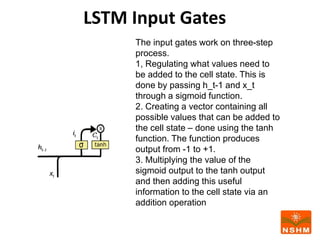
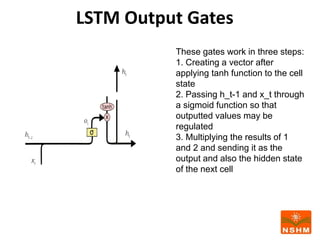
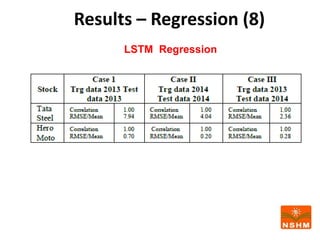
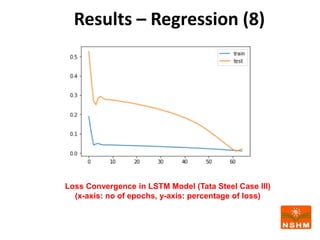
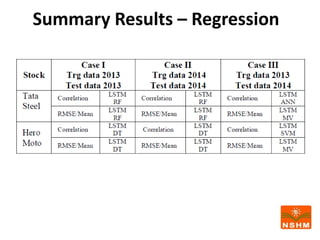
This document presents research on using machine learning and deep learning models to predict stock prices. The researcher collected stock price data for two companies, Tata Steel and Hero Motocorp, at 5-minute intervals over two years. Eight classification and eight regression models were tested on this data to predict opening stock prices. The results showed that deep learning models like LSTM outperformed other regression models, while ANN performed best among classification models on average. Identifying individual errors in the best-performing LSTM model is identified as a potential next step.