






























![Sitografia
[1] http://www.semantic-web.at/
[2] http://blog.semantic-web.at/
[3] http://www.victorgodot.com/blog/?p=113
[4] http://en.wikipedia.org/
[5] http://www.audiweb.it/
[6] http://punto-informatico.it/
[7] http://www.trueknowledge.com/
[8] http://www.youtube.com/watch?v=IONdWQwcmxA
[9] http://www.exalead.com/software/
[10] http://www.autonomy.com/
[11] http://www.polyspot.com/
[12] http://www-01.ibm.com/software/data/enterprise-search/omnifind-
enterprise/
[13] http://www.expertsystem.it/index.asp
[14]http://www.i-dome.com/flash-news/pagina.phtml?_id_articolo=11656-I-
vantaggi-della- Semantic-Intelligence-per-il-Semantic-Web.html
02/11/2010 43](https://image.slidesharecdn.com/presentazionetecnologiesemanticeperilknowledgemanagementnicolacerami131158-120901045649-phpapp01/85/Tecnologie-semantiche-per-il-knowledge-Management-43-320.jpg)



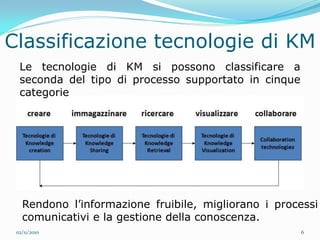
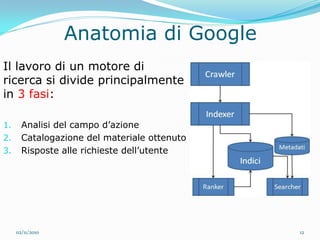
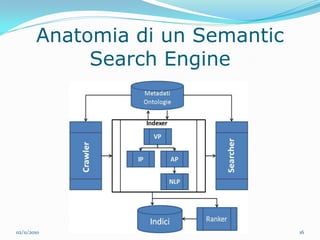
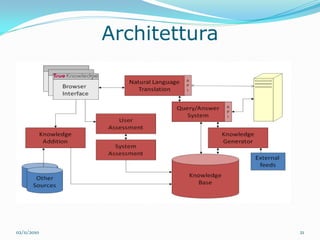
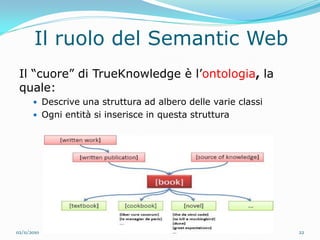
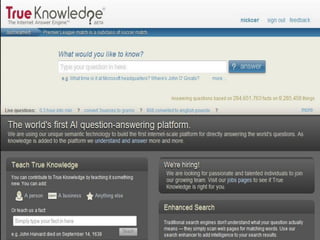
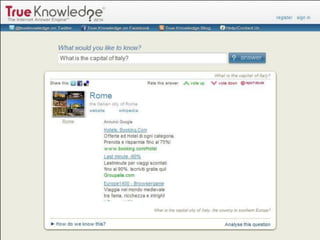
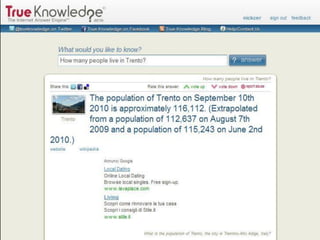
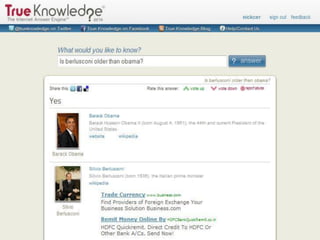
Il documento analizza le tecnologie web semantiche nel contesto del knowledge management e evidenzia l'importanza della conoscenza come asset strategico per le aziende. Viene effettuato un confronto tra motori di ricerca tradizionali e motori di ricerca semantici, sottolineando i vantaggi delle tecnologie semantiche nel migliorare l'accessibilità e l'efficacia delle informazioni. Inoltre, si presenta True Knowledge come esempio di tecnologia semantica avanzata che comprende un'interfaccia di ricerca in linguaggio naturale.




































