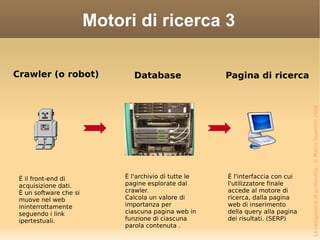
Il documento esplora la navigazione nel web profondo, sottolineando che il deep web è significativamente più vasto del web superficiale. Esamina l'evoluzione dei motori di ricerca e delle strategie di ricerca, enfatizzando l'importanza dell'uso corretto delle parole chiave e della conoscenza degli strumenti disponibili. Viene anche trattata la questione della privacy online e dell'importanza del controllo delle informazioni personali.