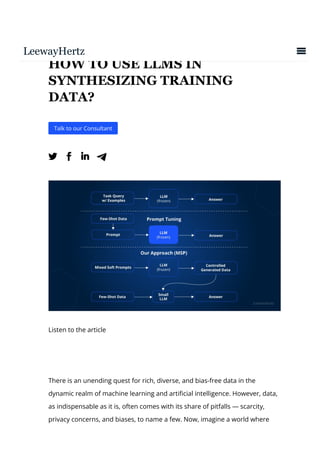
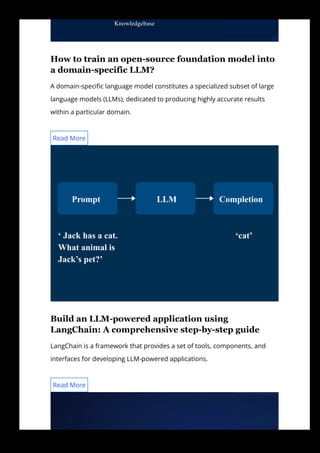
The document provides a step-by-step guide for using large language models (LLMs) to synthesize training data. It begins by explaining the importance of training data and benefits of synthetic data. It then outlines the process, which includes: 1) Choosing the right LLM based on task requirements, data availability, and other factors. 2) Training the chosen LLM model with the synthesized data to generate additional data. 3) Evaluating the quality of the synthesized data based on fidelity, utility and privacy. The guide uses generating synthetic sales data for a coffee shop sales prediction app as an example.











![{"product_id": 3, "product": "Croissant", "calories": 300, "price"
# add more products as needed...
]
payment_types = ["cash", "credit", "debit", "gift card"]
start_date = datetime.strptime("1/1/2022", "%m/%d/%Y")
end_date = datetime.strptime("12/31/2022", "%m/%d/%Y")
def random_date(start, end):
return start + timedelta(seconds=random.randint(0, int((end star
def random_time():
return "{:02d}:{:02d}".format(randrange(6, 21), randrange(0, 60))
with open('sales_data.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(["id", "date", "time", "product_id", "product", "c
for i in range(1, 101):
product = random.choice(products)
quantity = randrange(1, 4)
writer.writerow([
i,
random_date(start_date, end_date).strftime("%m/%d/%Y"),
random_time(),
product["product_id"],
product["product"],
product["calories"],
product["price"],
product["type"],
quantity,](https://image.slidesharecdn.com/www-leewayhertz-com-llms-in-synthesizing-training-data-230818061611-179d9e0d/85/How-to-use-LLMs-in-synthesizing-training-data-14-320.jpg)
![quantity * product["price"],
random.choice(payment_types)
])
ChatGPT was able to generate a full Python program to make synthetic sales
data with just one short prompt. However, because of ChatGPT’s response
size limit, we could only list six items on the co몭ee shop menu. If we asked
for more items, the output and the program would be cut o몭, which means
the program wouldn’t run.
You can provide additional prompts as below:
# Additional prompts:
# Create a function to return one random item from a list of dictionar
# containing 15 common drink items sold in a coffee shop including the
# Capitalize the first letter of each product name. Start product id a
# Create a function to return one random item from a list of dictionar
# containing 10 common food items sold in a coffee shop including the
# Capitalize the first letter of each product name. Start product id a
To install faker dependencies execute the below code:
pip install faker
The complete generated code will be like this:
import random
import csv
from datetime import datetime, timedelta, time](https://image.slidesharecdn.com/www-leewayhertz-com-llms-in-synthesizing-training-data-230818061611-179d9e0d/85/How-to-use-LLMs-in-synthesizing-training-data-15-320.jpg)
![from faker import Faker
# Function to generate random time
def random_time(start, end):
return start + timedelta(
seconds=random.randint(0, int((end start).total_seconds())),
)
# Generate drink items
def generate_drink_items():
drinks = [{'id': i+1, 'name': Faker().words(nb=1, unique=True)[0].
return random.choice(drinks)
# Generate food items
def generate_food_items():
foods = [{'id': i+16, 'name': Faker().words(nb=1, unique=True)[0].
return random.choice(foods)
# Generate payment types
def generate_payment_types():
return random.choice(['cash', 'credit', 'debit', 'gift card'])
# Open the CSV file
with open('coffee_shop_sales_chatgpt_data.csv', 'w', newline='') as fi
writer = csv.writer(file)
writer.writerow(["id", "date", "time", "product_id", "product", "c
# Generate sales records
for i in range(100):
item = generate_drink_items() if random.choice([True, False])
date = Faker().date_between_dates(date_start=datetime(2022, 1,
time = random_time(datetime.strptime('6:00 AM', '%I:%M %p'), d](https://image.slidesharecdn.com/www-leewayhertz-com-llms-in-synthesizing-training-data-230818061611-179d9e0d/85/How-to-use-LLMs-in-synthesizing-training-data-16-320.jpg)
![time = random_time(datetime.strptime('6:00 AM', '%I:%M %p'), d
quantity = random.randint(1,3)
amount = round(quantity * item['price'], 2)
writer.writerow([i+1, date, time, item['id'], item['name'], it
This code selects from 15 di몭erent drink items and 10 di몭erent food items,
all with unique names, and writes 100 sales records to a CSV 몭le named
“co몭ee_shop_sales_chatgpt_data.csv”.
You can 몭nd sample reference code in this Github location.
Copy and paste the code in VS code and run it.
The generated synthetic data will be like this –
https://github.com/garysta몭ord/ten-ways-gen-ai-code-
gen/blob/main/data/output/co몭ee_shop_sales_data_chatgpt.csv
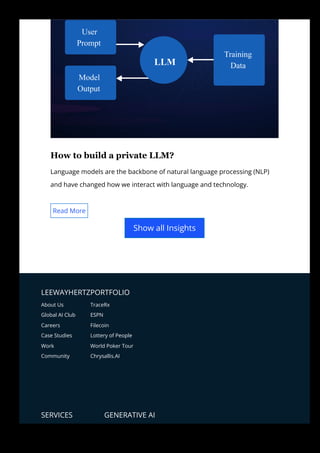
Step 2: Training the model with LLM-generated
synthetic data
We will train sales prediction model with generated synthesized data. This
involves several steps, such as-
Preprocessing the data
Splitting it into training and testing datasets
Selecting a model
Training the model
Evaluating its performance
Using it for prediction.
Below is a high-level description of these steps using Python and popular
libraries like pandas and scikit-learn:
Note: The exact code and approach would depend on the speci몭cs of your
application, data, and prediction task. The description below assumes a](https://image.slidesharecdn.com/www-leewayhertz-com-llms-in-synthesizing-training-data-230818061611-179d9e0d/85/How-to-use-LLMs-in-synthesizing-training-data-17-320.jpg)
![regression task, where you are trying to predict a continuous value like the
amount of sales.
Load the data: Start by loading your synthetic data into a pandas DataFrame:
import pandas as pd
data = pd.read_csv('coffee_shop_sales_chatgpt_data.csv')
Preprocess the data: Before training your model, you will need to preprocess
your data. This could include:
Converting categorical variables into numeric variables using techniques
like one-hot encoding.
Normalizing numeric variables so they’re on the same scale.
Here is an example using pandas and scikit-learn:
import numpy as np
from sklearn.preprocessing import OneHotEncoder, StandardScaler
# Onehot encoding for categorical features
encoder = OneHotEncoder()
categorical_features = ['product', 'type', 'payment type']
encoded_features = encoder.fit_transform(data[categorical_features]).t
# Normalizing numeric features
scaler = StandardScaler()
numeric_features = ['calories', 'price', 'quantity']
scaled_features = scaler.fit_transform(data[numeric_features])
# Combine the processed features back into a single array
X = np.concatenate([scaled_features, encoded_features], axis=1)](https://image.slidesharecdn.com/www-leewayhertz-com-llms-in-synthesizing-training-data-230818061611-179d9e0d/85/How-to-use-LLMs-in-synthesizing-training-data-18-320.jpg)
![y = data['amount']
Split the data: You should split your data into a training set and a testing set.
This allows you to evaluate your model’s performance on unseen data:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.
Train the model: Choose a suitable machine learning model for sales
prediction. For instance, a RandomForestRegressor or
GradientBoostingRegressor can be used:
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X_train, y_train)
Evaluate the model: Use the testing set to evaluate the model’s performance.
A common metric for regression tasks is the mean absolute error (MAE):
from sklearn.metrics import mean_absolute_error
y_pred = model.predict(X_test)
print('Mean Absolute Error:', mean_absolute_error(y_test, y_pred))
Predict sales: With the model trained, you can now use it to predict sales:
# Let's say `new_data` is your new sales data for prediction.](https://image.slidesharecdn.com/www-leewayhertz-com-llms-in-synthesizing-training-data-230818061611-179d9e0d/85/How-to-use-LLMs-in-synthesizing-training-data-19-320.jpg)
![# Let's say `new_data` is your new sales data for prediction.
new_data = pd.read_csv('sales_data.csv')
def preprocess(new_data):
# Perform the same preprocessing steps as before
encoded_features = encoder.transform(new_data[categorical_features
scaled_features = scaler.transform(new_data[numeric_features])
# Combine the processed features back into a single array
preprocessed_data = np.concatenate([scaled_features, encoded_featu
return preprocessed_data
# Preprocess the new data
preprocessed_data = preprocess(new_data)
# Use the preprocessed data to make predictions
predictions = model.predict(preprocessed_data)
Please note: The feature names should match those that were passed during
몭t.
This example provides a basic outline of the process. Each step has many
possible variations, and the best approach will depend on your speci몭c data,
problem, and requirements. For example, you might want to try di몭erent
preprocessing techniques, machine learning models, and evaluation metrics.
How to evaluate the quality of synthesized
training data?
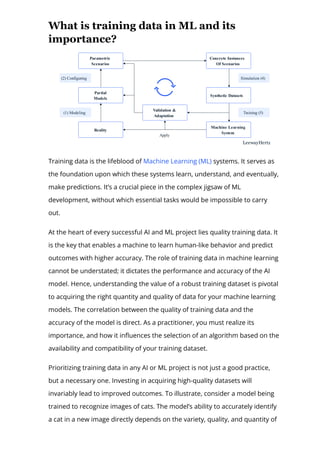
For the adoption of synthetic data in machine learning and analytics projects,
it’s not only essential to ensure the synthetic data serves its intended
purpose and meets application requirements, but it’s also crucial to measure](https://image.slidesharecdn.com/www-leewayhertz-com-llms-in-synthesizing-training-data-230818061611-179d9e0d/85/How-to-use-LLMs-in-synthesizing-training-data-20-320.jpg)















![[DSC DACH 25] Zrinka Puljiz - Importance of data at the time of LLMs.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/importanceofdataatthetimeofllms2-251024080620-db0b03b5-thumbnail.jpg?width=640&height=640&fit=bounds)














































