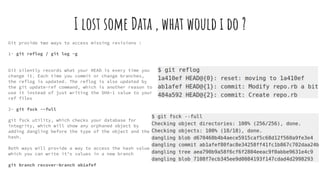
This document provides an overview of how Git works under the hood by explaining its core data structures and objects. It discusses how Git stores content and revisions as tree and blob objects linked together in a commit object graph. It describes how Git uses cryptographic hashes to store and retrieve content efficiently. It also covers how Git uses packfiles, references, and the smart protocol to transfer data between repositories remotely.



![Git Data Structure
Git is a content-addressable file system,but what
does that means well , it’s simply a key value
store Where is the key is a hash and the value is
a blob or a group of blob with hashes.
Git uses cryptographic hashes for keys which is
an algorithm which constructs a short digest from
a sequence of bytes of any length. Ex [sha 1=>160
bit, sha2 > 256, skein > 256]. * the bigger the
better
When you commit a file into Git , it calculates
and remembers the hash of the contents of the
file. So when you retrieve it, it can verify that
the hash of the data being retrieved exactly
matches the hash that was computed when it was
stored.](https://image.slidesharecdn.com/howgitworks-210528022555/85/How-git-works-3-320.jpg)






![but ,I want to Talk To My Friends outside !
Using remotes we can move changesets between multiple git repositories.
The remote uses format called refspec which is stored in config folder ,
you can view them using git remote -v
Refspec section example:
[remote "origin"]
url = https://github.com/schacon/simplegit-progit -> remote
url
fetch = +refs/heads/*:refs/remotes/origin/* -> +<src>:<dst>
We can filter by single branch
We have two main operations to be used with the refspec fetch and push :
Fetch:
fetch = +refs/heads/master:refs/remotes/origin/master
The + sign is optional , it tells git to update the remote refs even
it’s n’t using fast forward
You can use multiple fetch in the same section or you can the command
git fetch
You can use globe in the fetch to create a pattern , which can be used
to namespace and partition the code
Push :
push = refs/heads/master:refs/heads/qa/master
You can create a push section to push automatically or use the command](https://image.slidesharecdn.com/howgitworks-210528022555/85/How-git-works-10-320.jpg)