











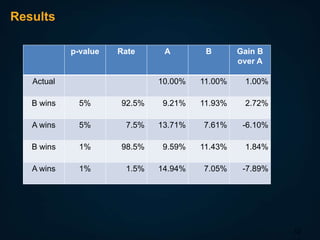




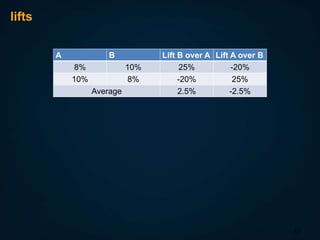
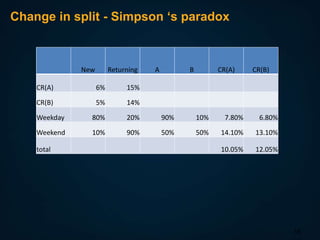



The document discusses A/B testing, specifically measuring the performance of multiple alternatives against a population to determine the best option, such as testing different web page layouts based on conversion rates. It highlights issues related to fairness, errors in test results, and the importance of maintaining independent observations. Additionally, it explores challenges in conducting tests, such as selection bias and how to control traffic allocation during tests.




























































![Apache Avro in LivePerson [Hebrew]](https://cdn.slidesharecdn.com/ss_thumbnails/apacheavroinliveperson2014-141027092641-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

























