Downloaded 10 times




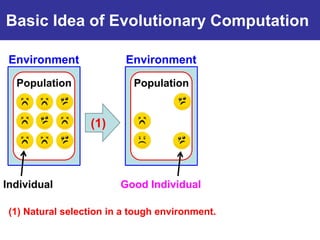
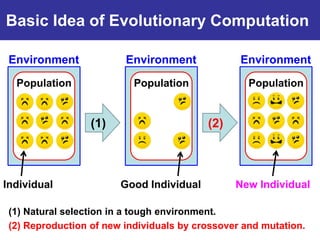
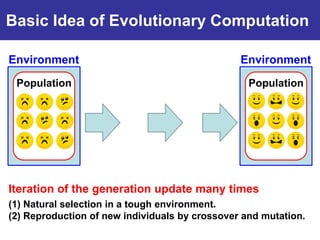

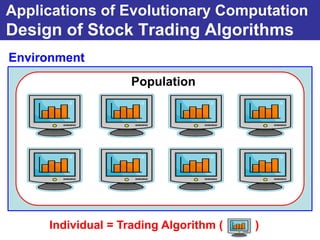

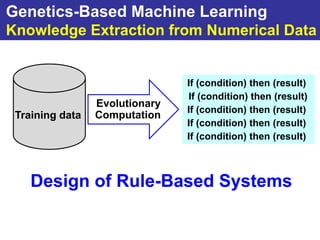
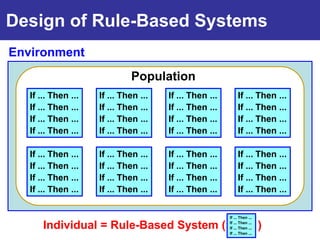
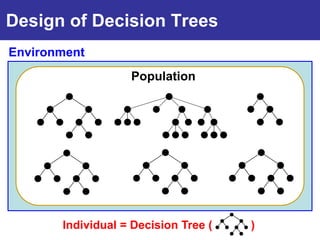
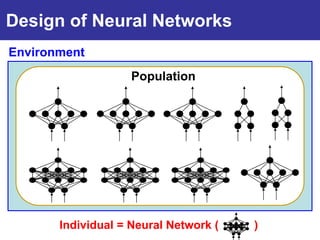
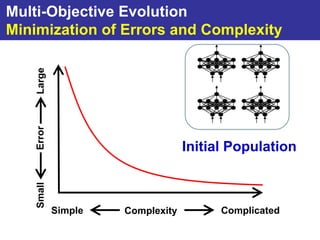
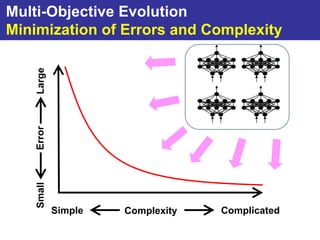
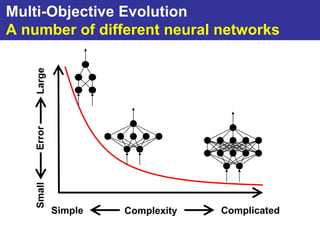
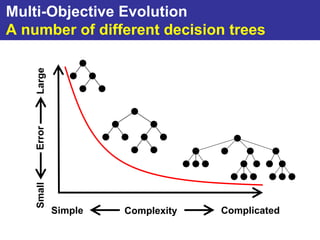
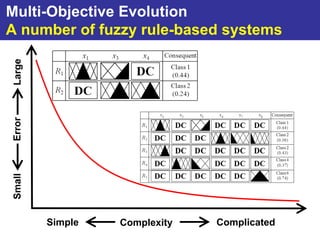

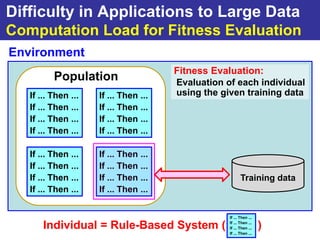
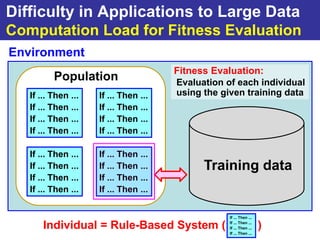
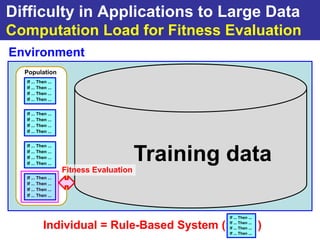

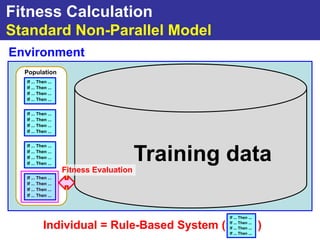
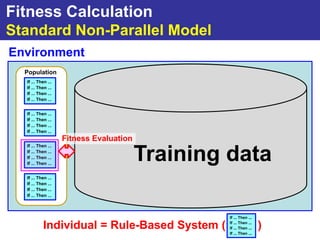
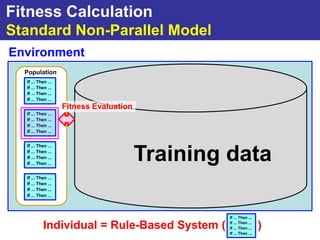
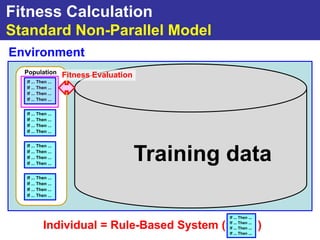

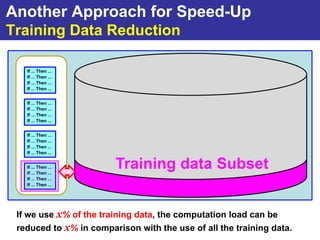
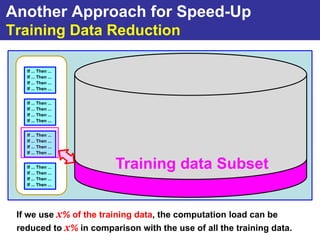
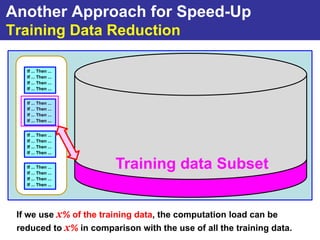
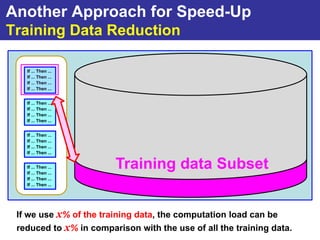
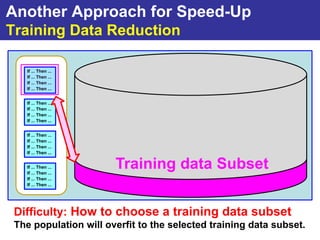
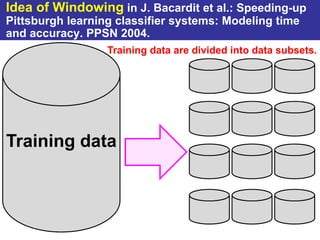
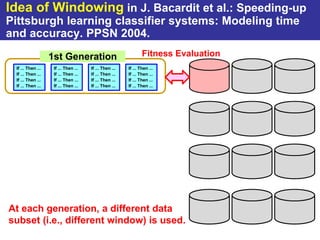
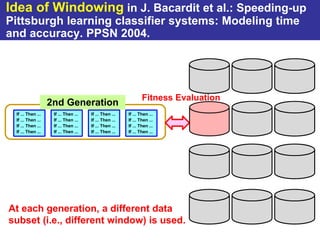
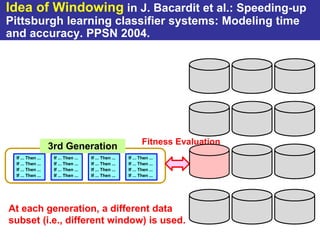
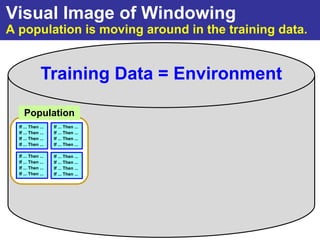
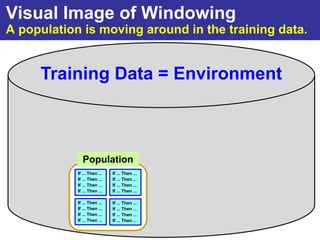
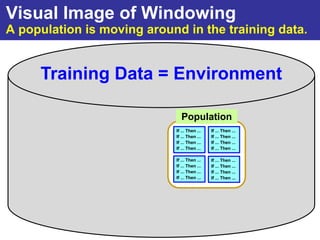
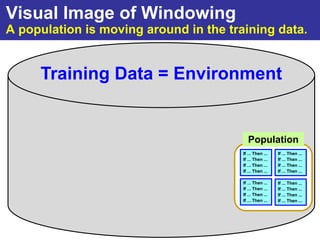
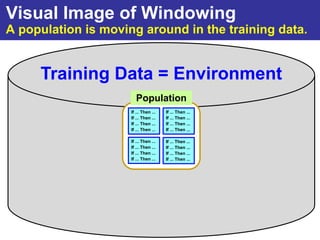
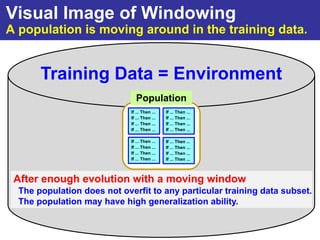
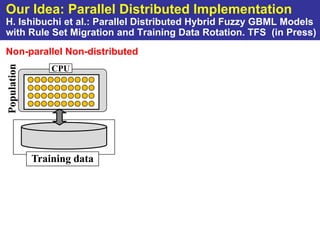
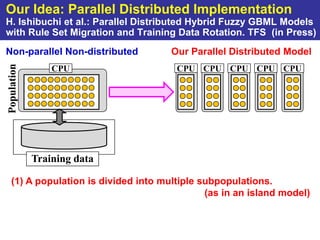
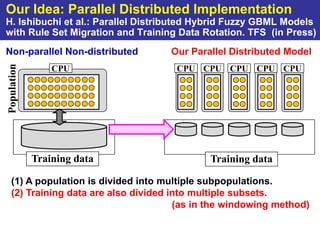
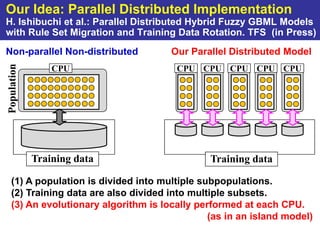
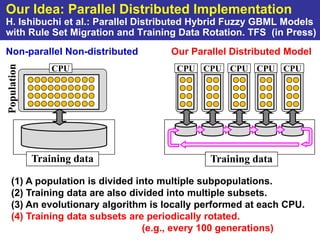
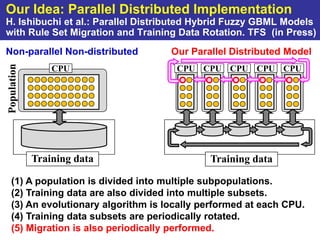
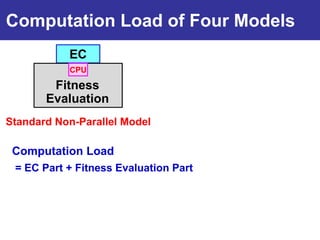
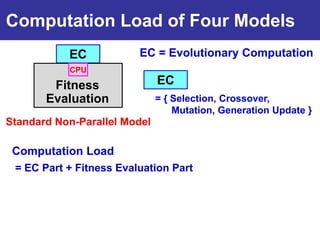
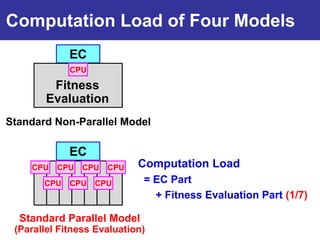
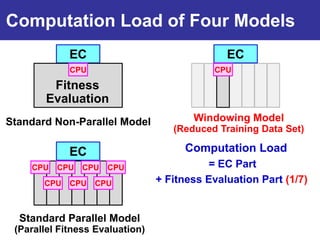
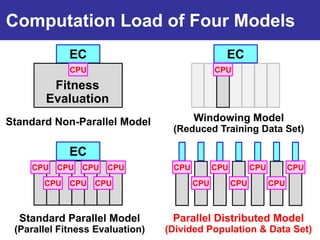
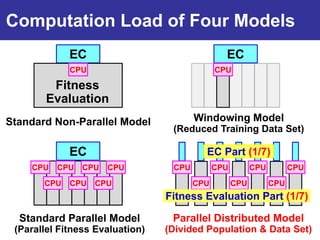

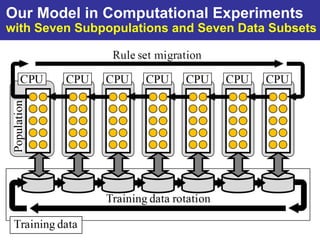
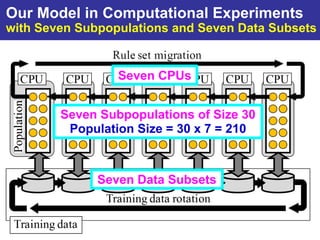
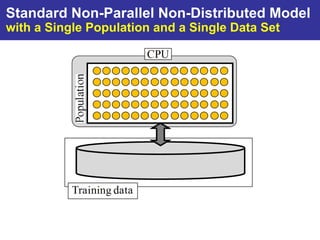
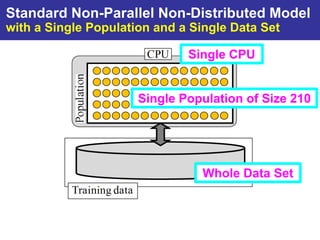

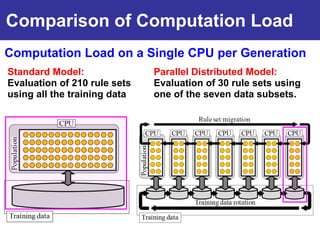
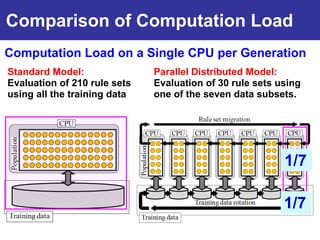
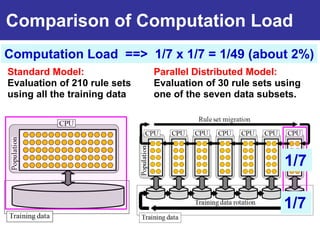
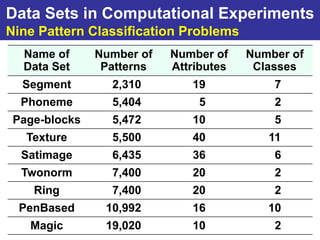
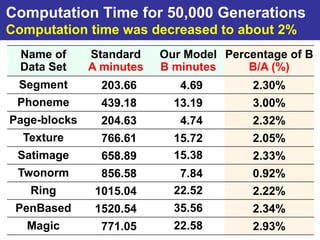
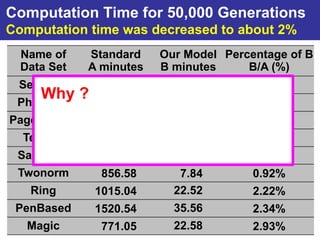
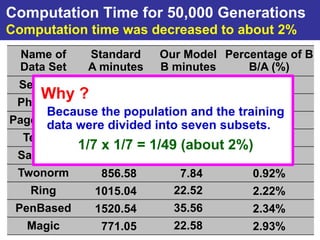
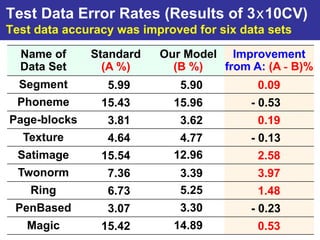
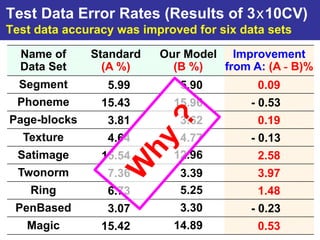
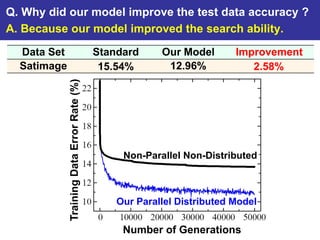
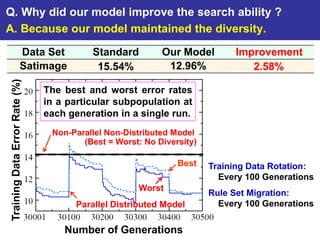
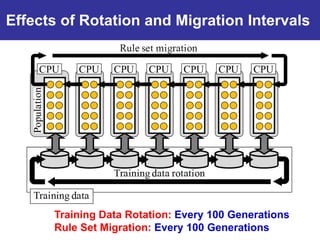
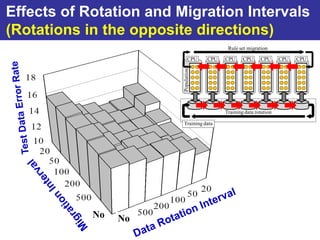
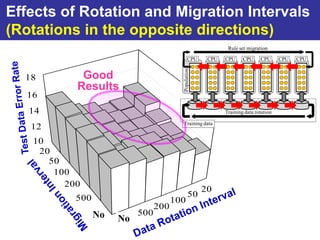
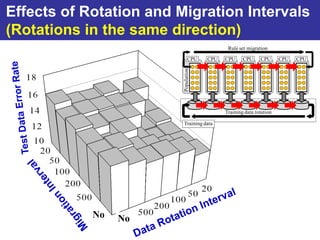
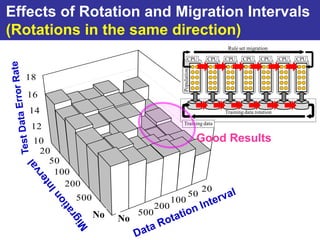
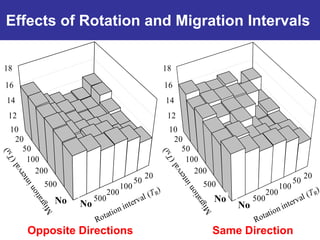
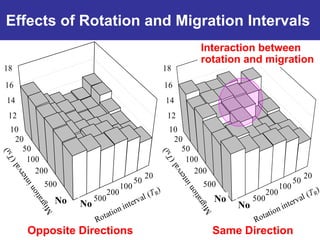
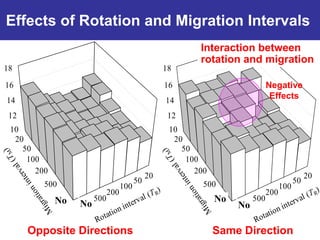

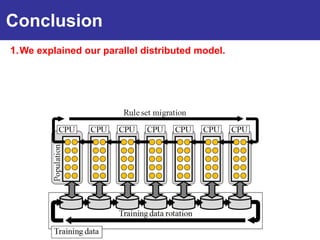
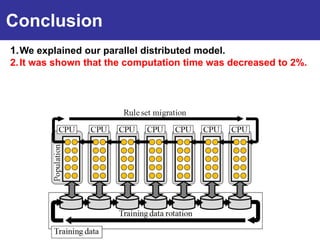
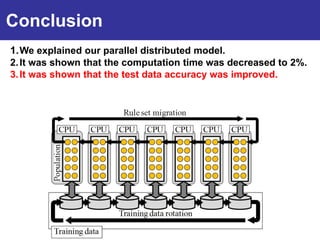
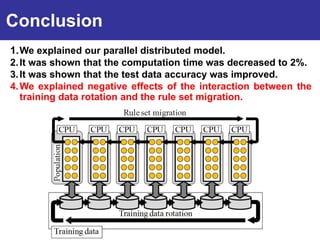
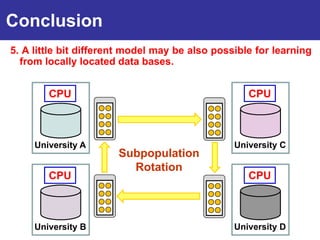
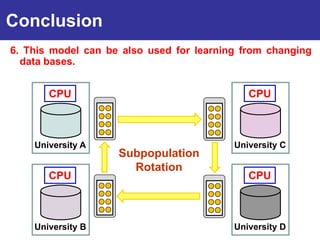
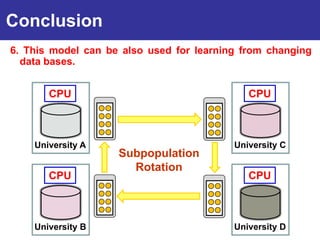
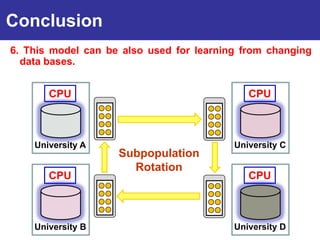
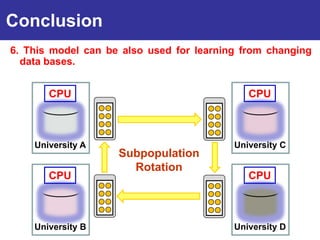
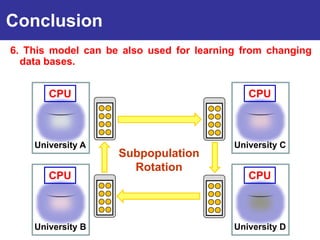


The document summarizes a presentation on improving the scalability of genetics-based machine learning to large datasets. It discusses using evolutionary computation approaches like genetic algorithms for machine learning tasks. A key challenge is the heavy computation required to evaluate fitness on large training data. The presentation proposes approaches like parallel distributed computation, reducing the training data used for each fitness evaluation, and a windowing method where different data subsets are used for fitness evaluation in each generation.



























