Download as PPSX, PPTX




![Evolutionary Algorithms
Background
Evolutionary Algorithms are based on a model of natural, biological evolution, which
was formulated for the first time by Charles Darwin [4]. Darwin’s “Theory of Evolution”
explains the adaptive change of species by the principle of natural selection, which
favours those species for survival and further evolution that are best adapted to their
environmental conditions. In addition to selection, Darwin recognized the occurrence of
small, apparently random and undirected variations between the phenotypes (any
observable characteristic or trait of an organism).
Modern biochemistry and genetics has extended the Darwinian Theory by microscopic
findings concerning the mechanisms of heredity, the resulting theory is called the
“Synthetic Theory of Evolution” [6]. This theory is based on genes as transfer units of
heredity. Genes are occasionally changed by mutations. Selection acts on the individual,
which expresses in its phenotype the complex interactions within its genotype, its total
genetic information, as well as the interaction of the genotype with the environment in
determining the phenotype. The evolving unit is the population which consists of a
common gene pool included in the genotypes of the individuals.
5](https://image.slidesharecdn.com/20091220mscpresentation-1319639708782-phpapp01-111026093842-phpapp01/75/2009-MSc-Presentation-for-Parallel-MEGA-5-2048.jpg)
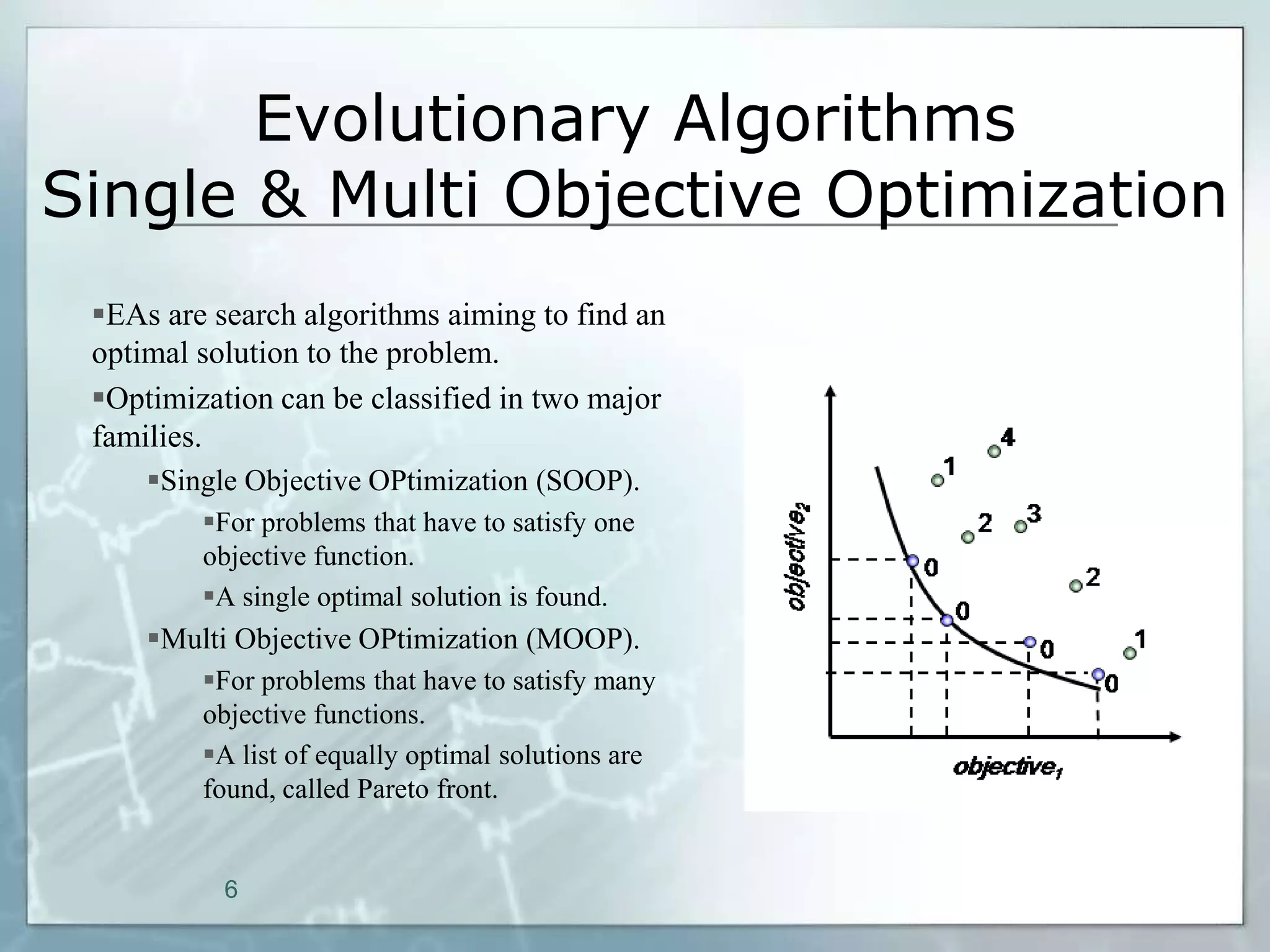
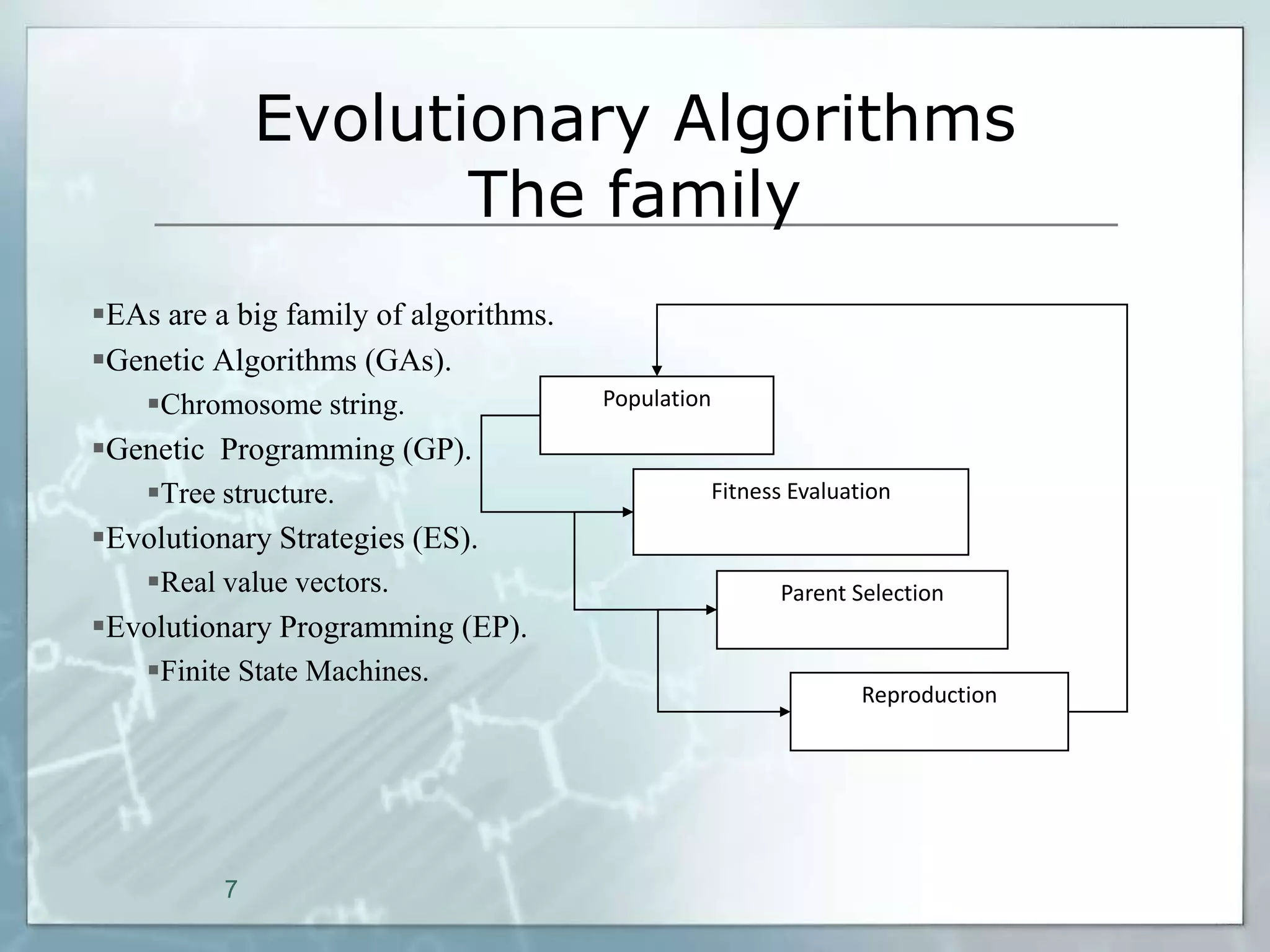
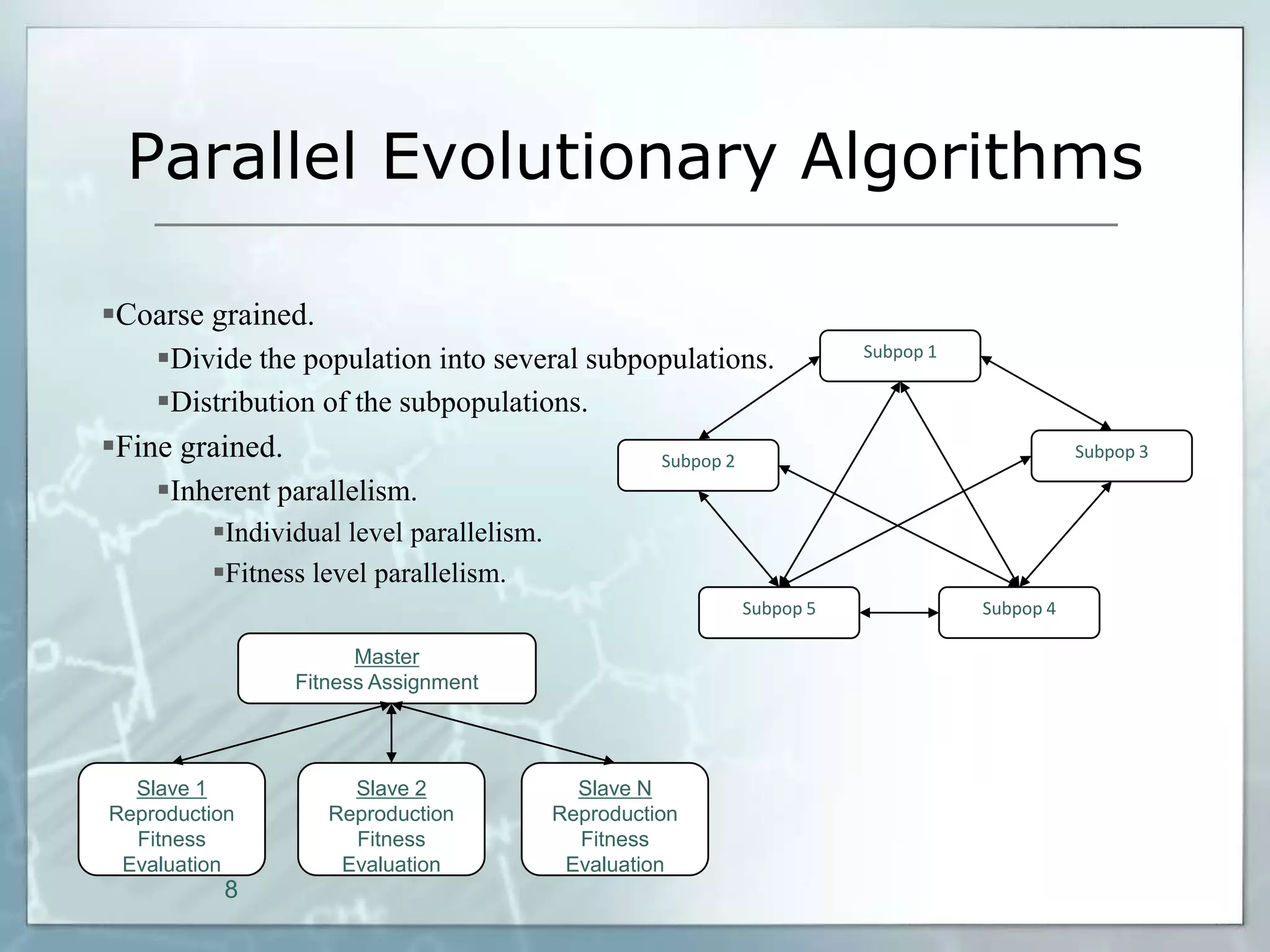
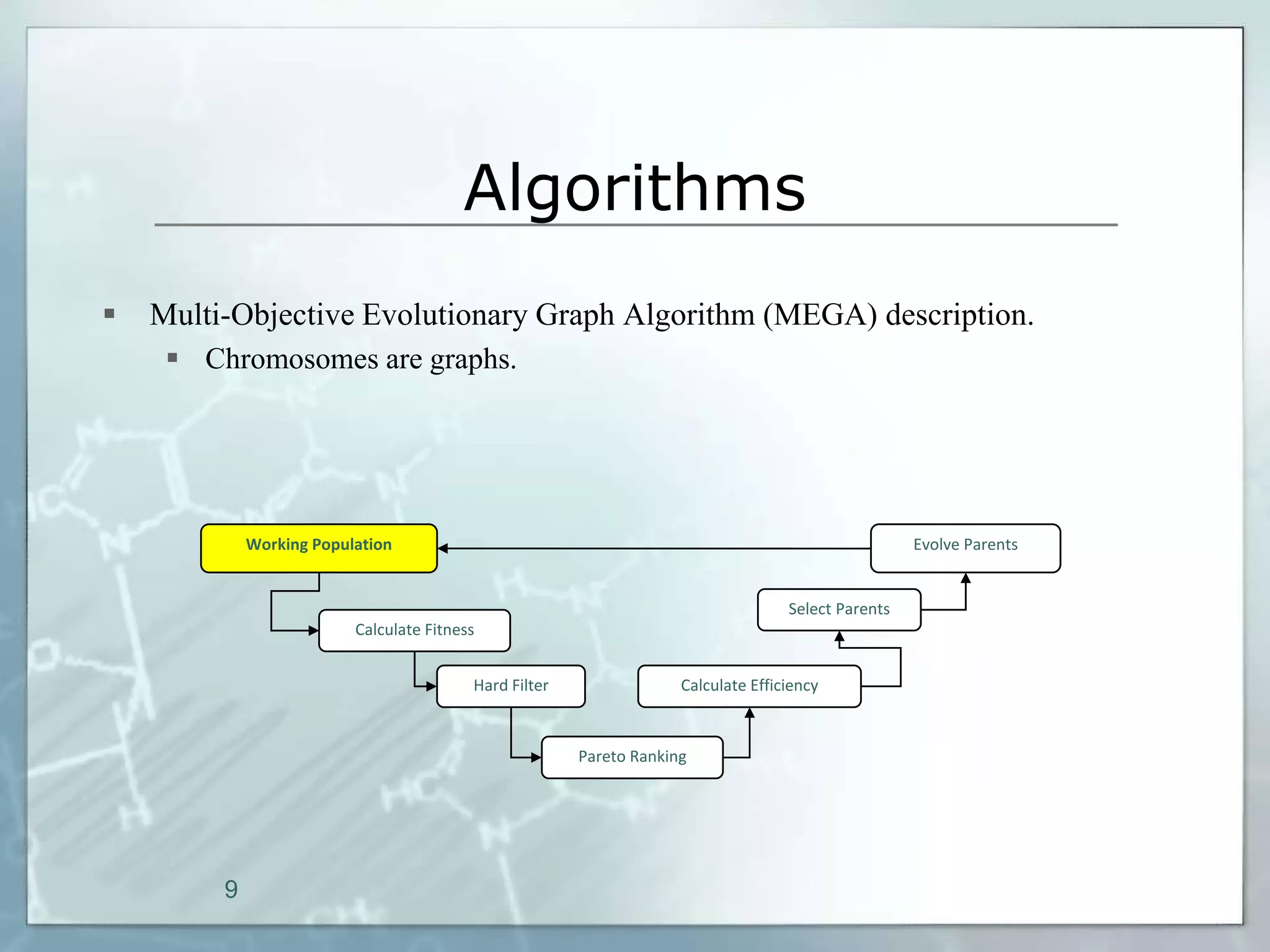
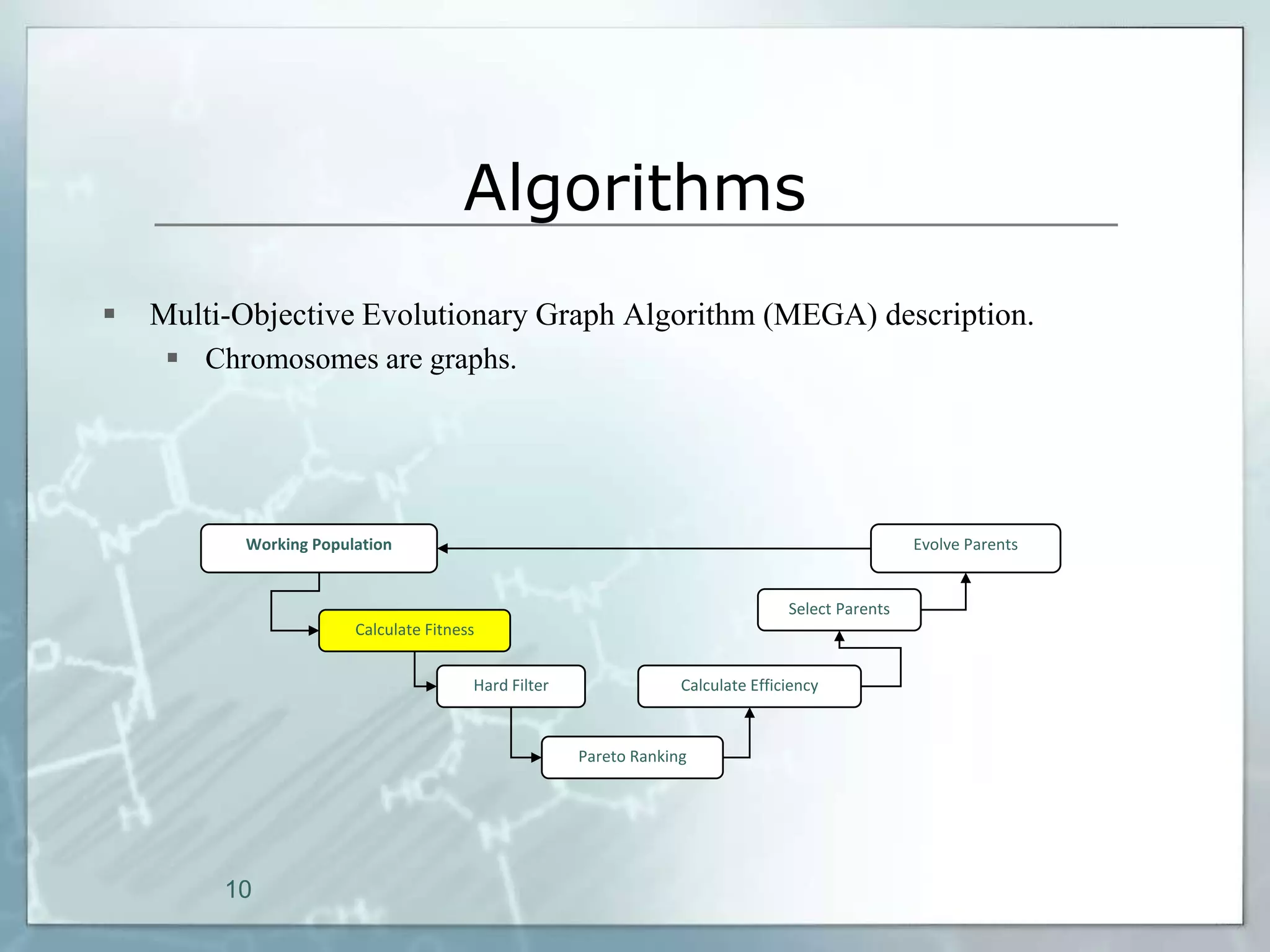
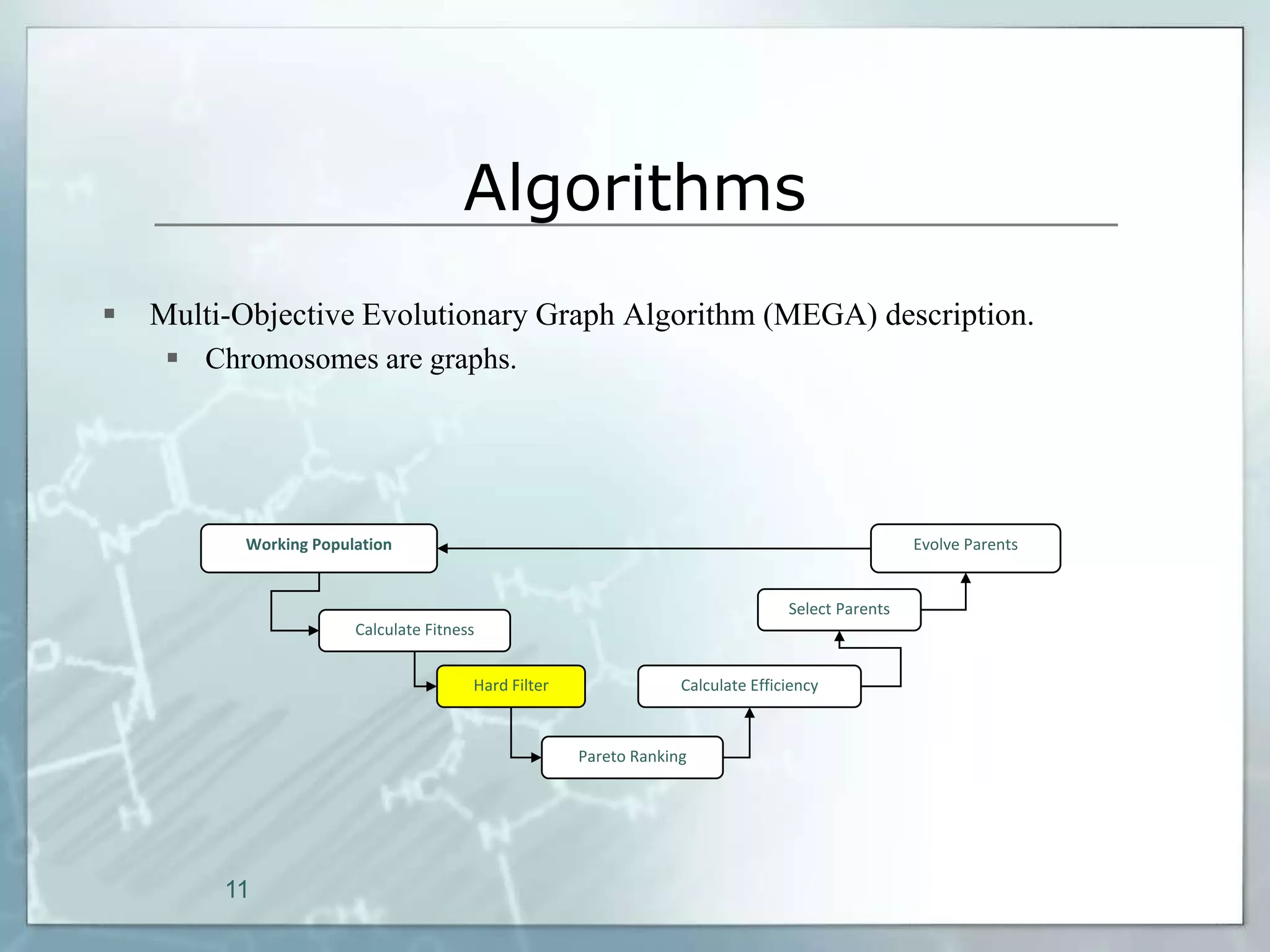
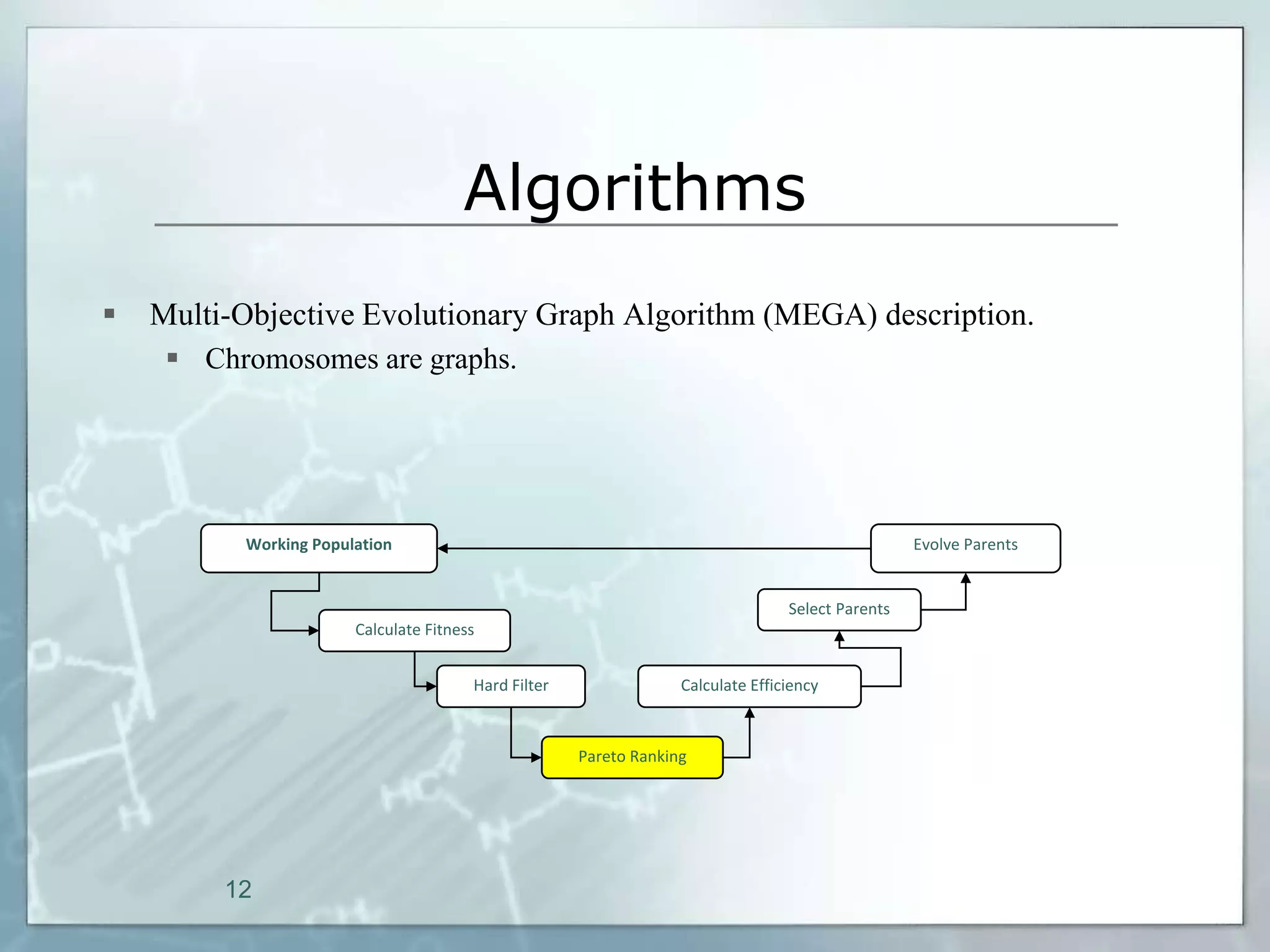
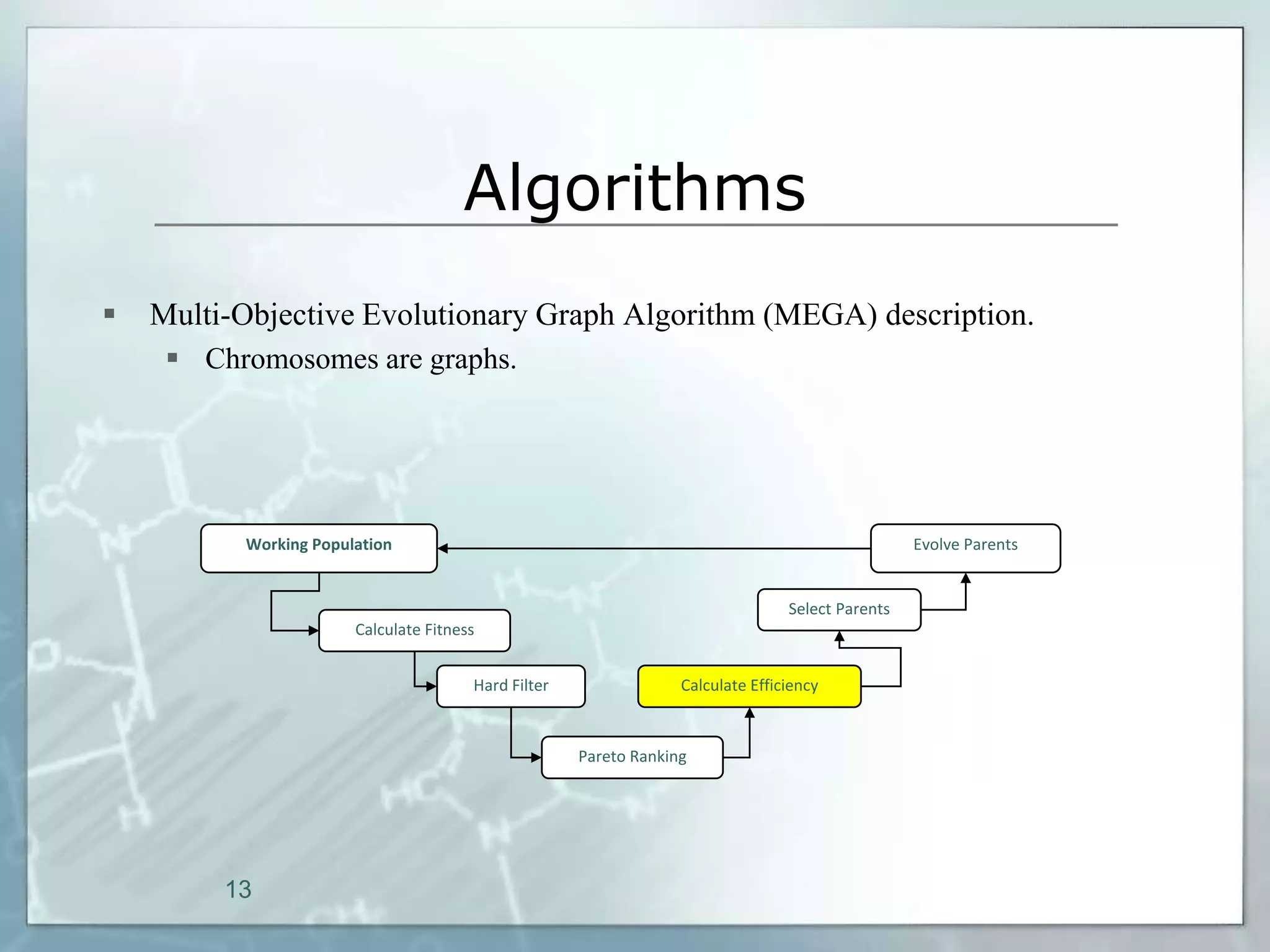

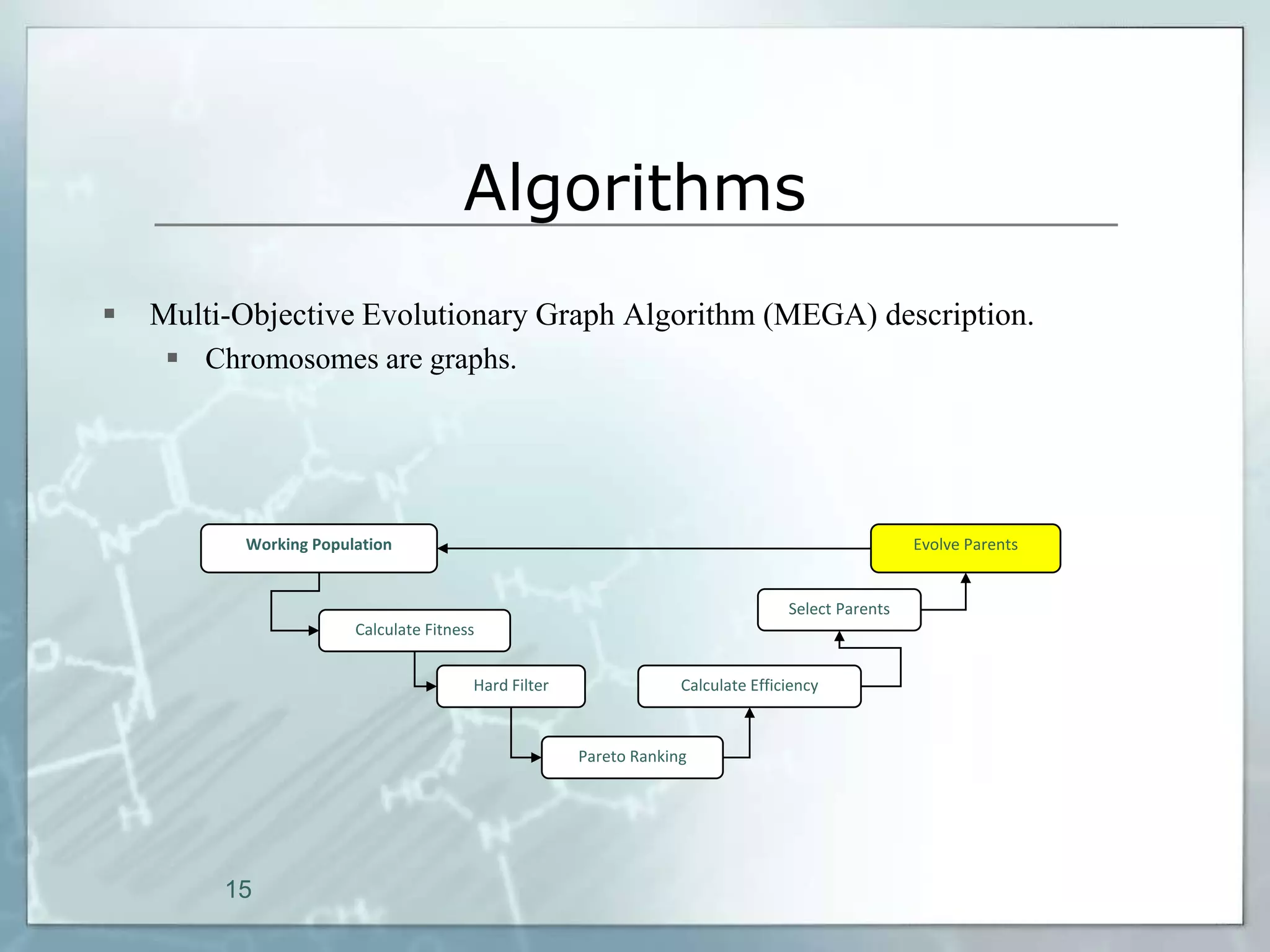
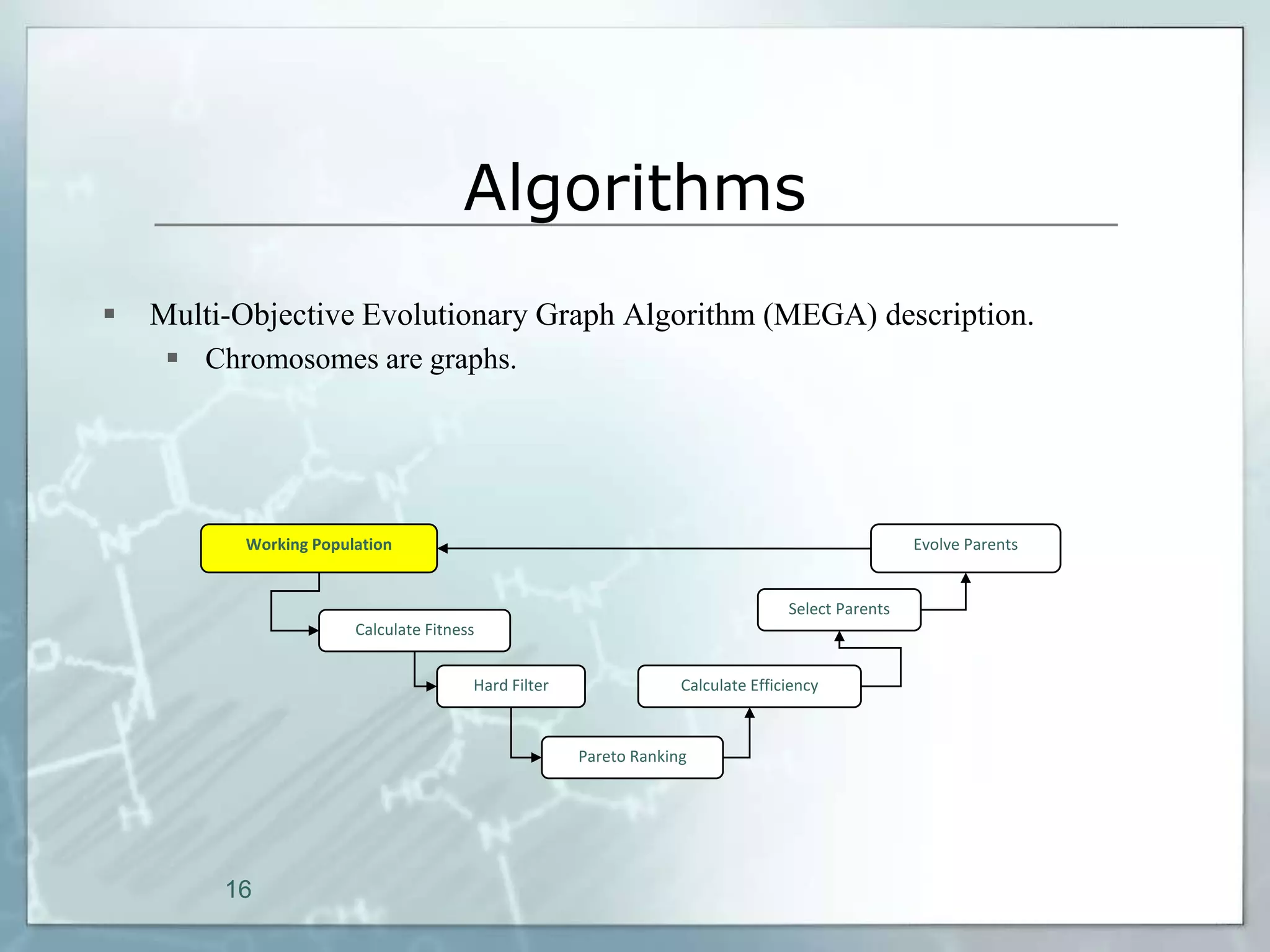





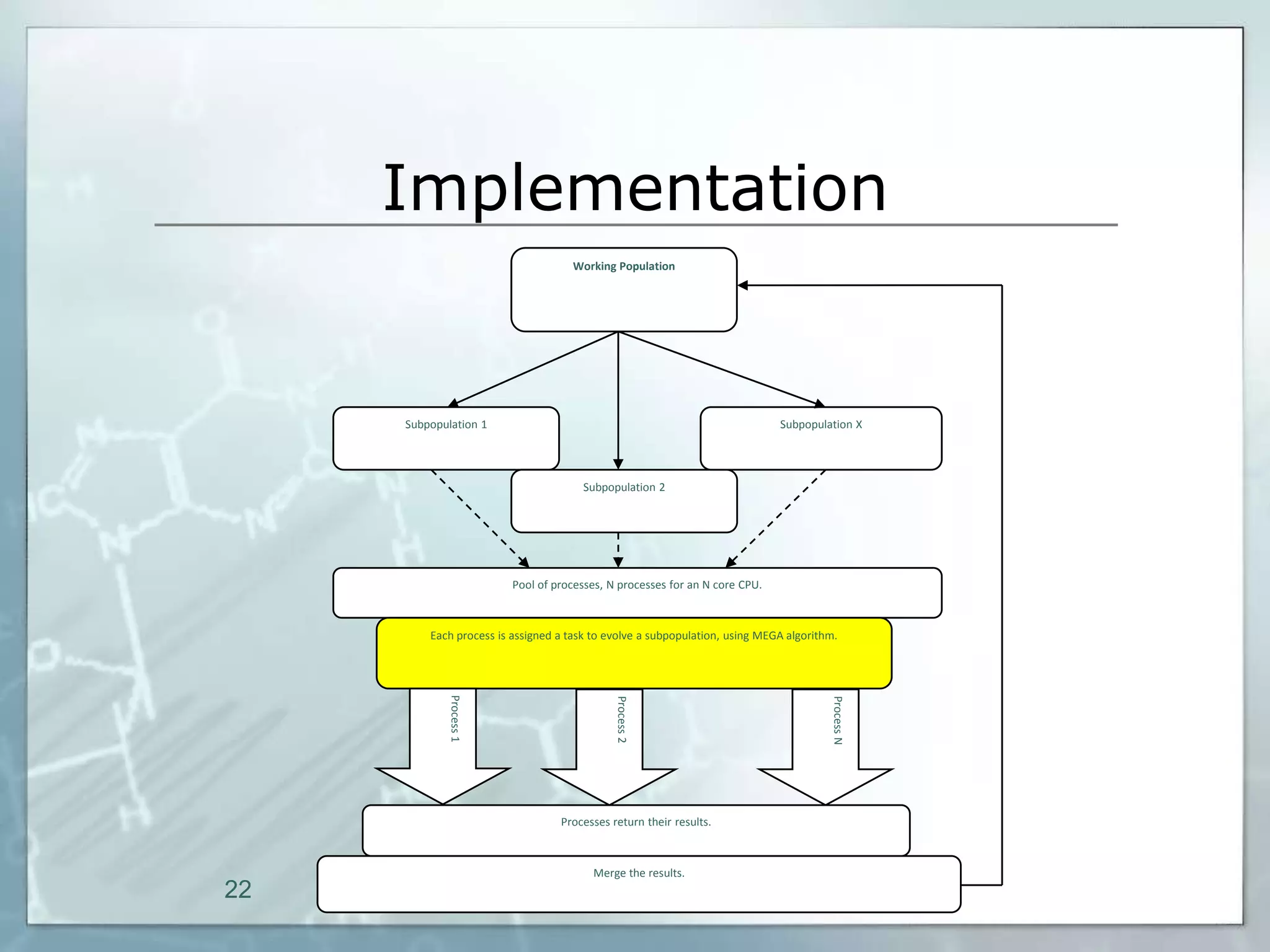
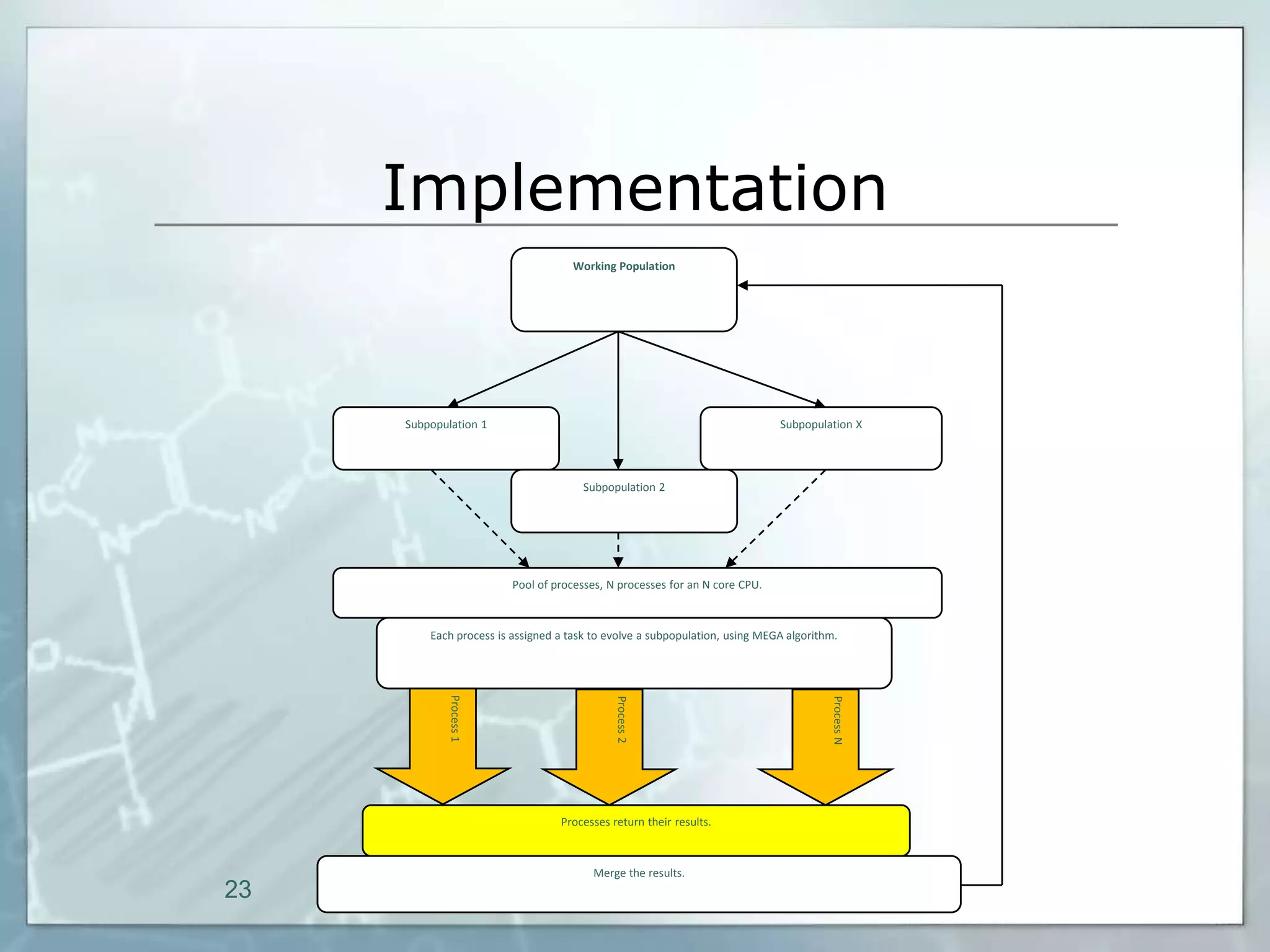

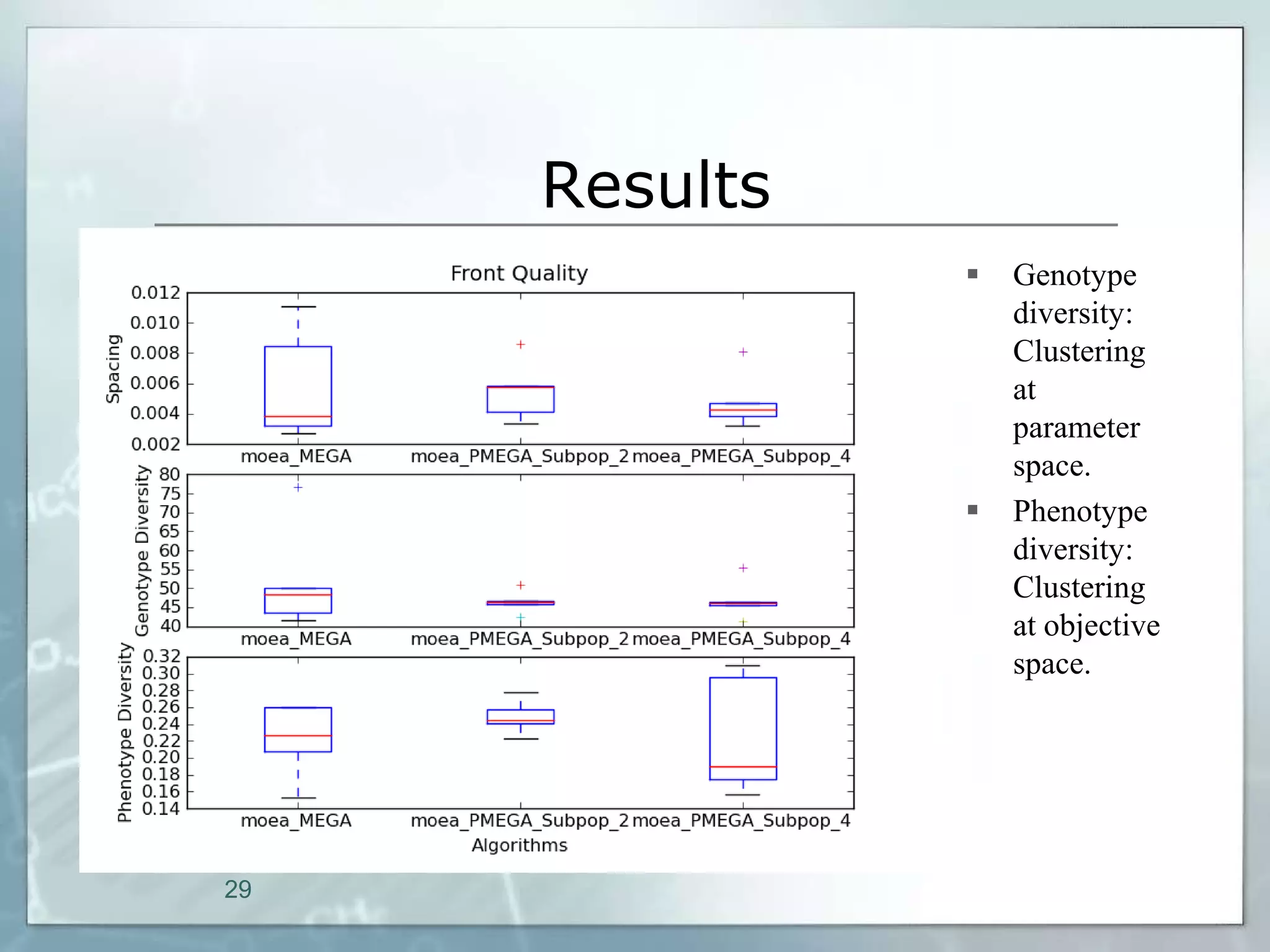
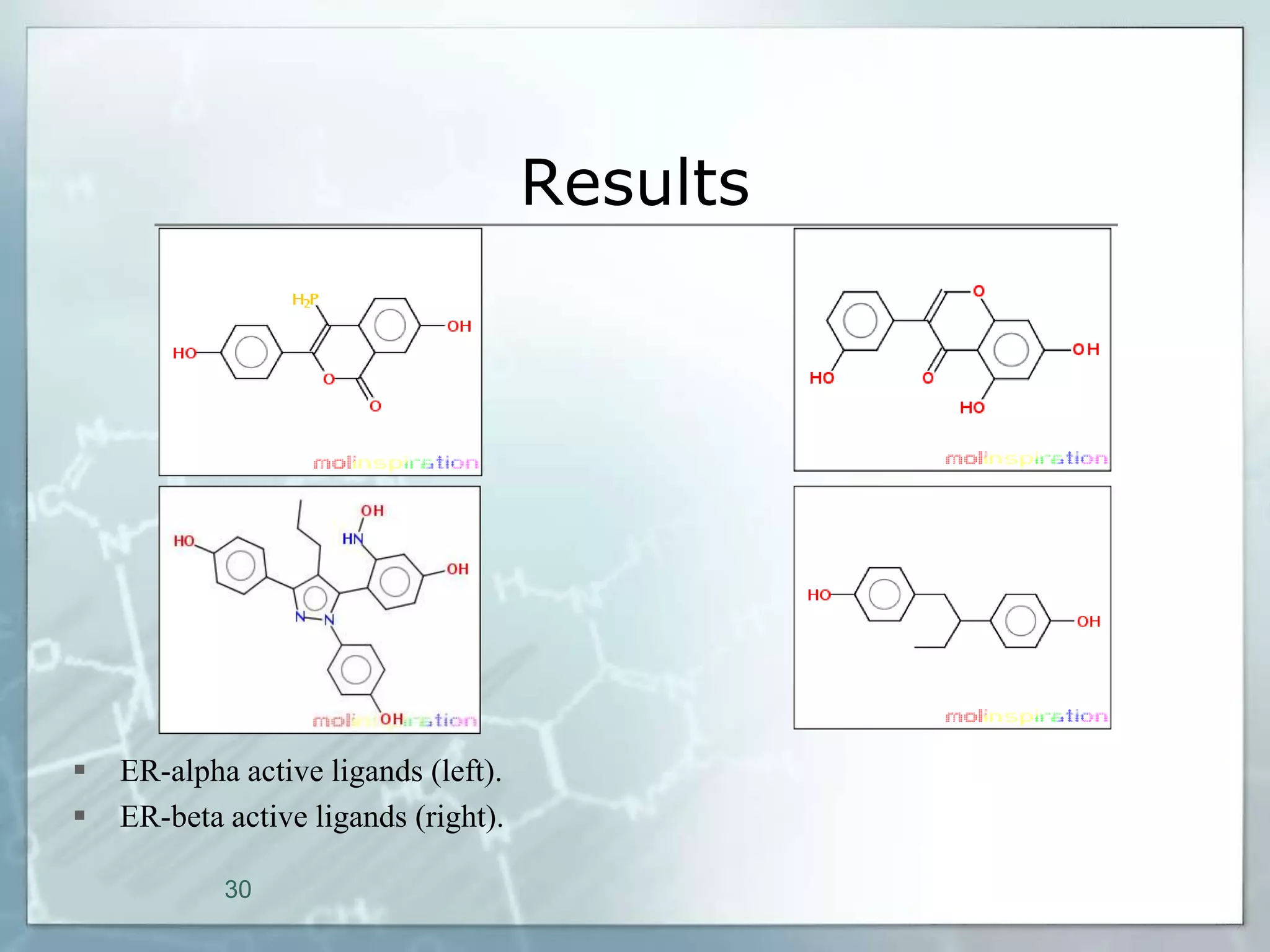
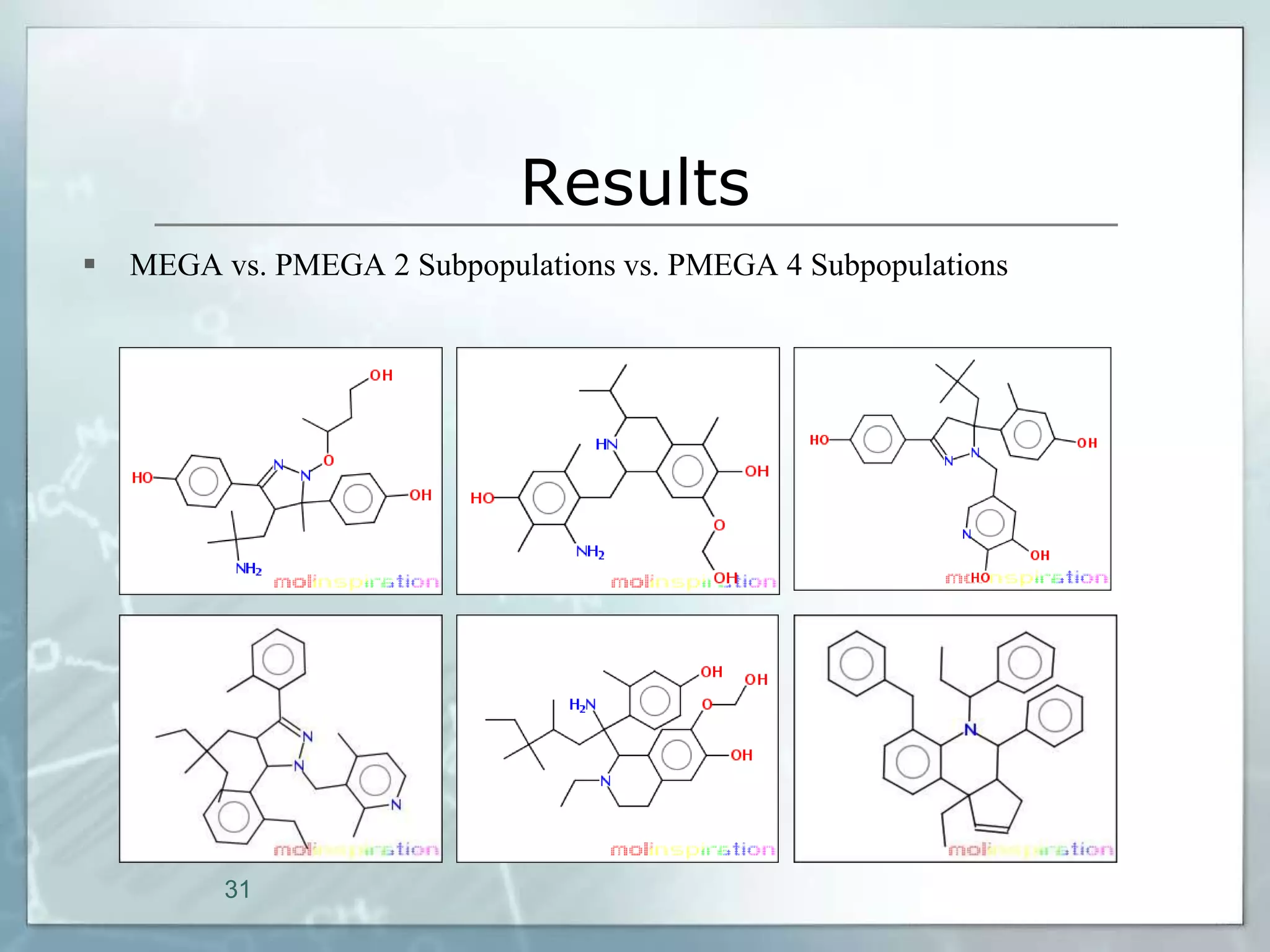
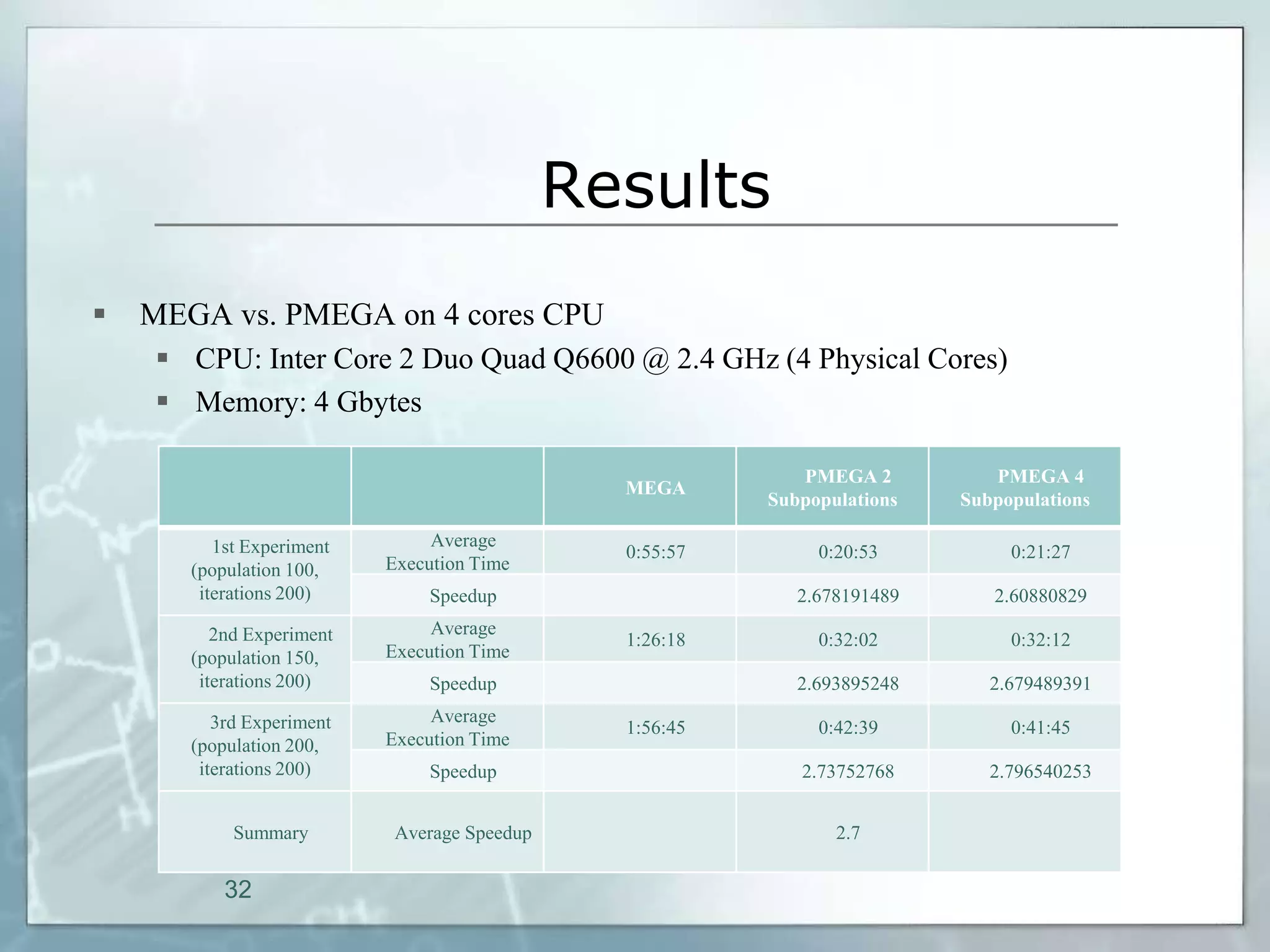
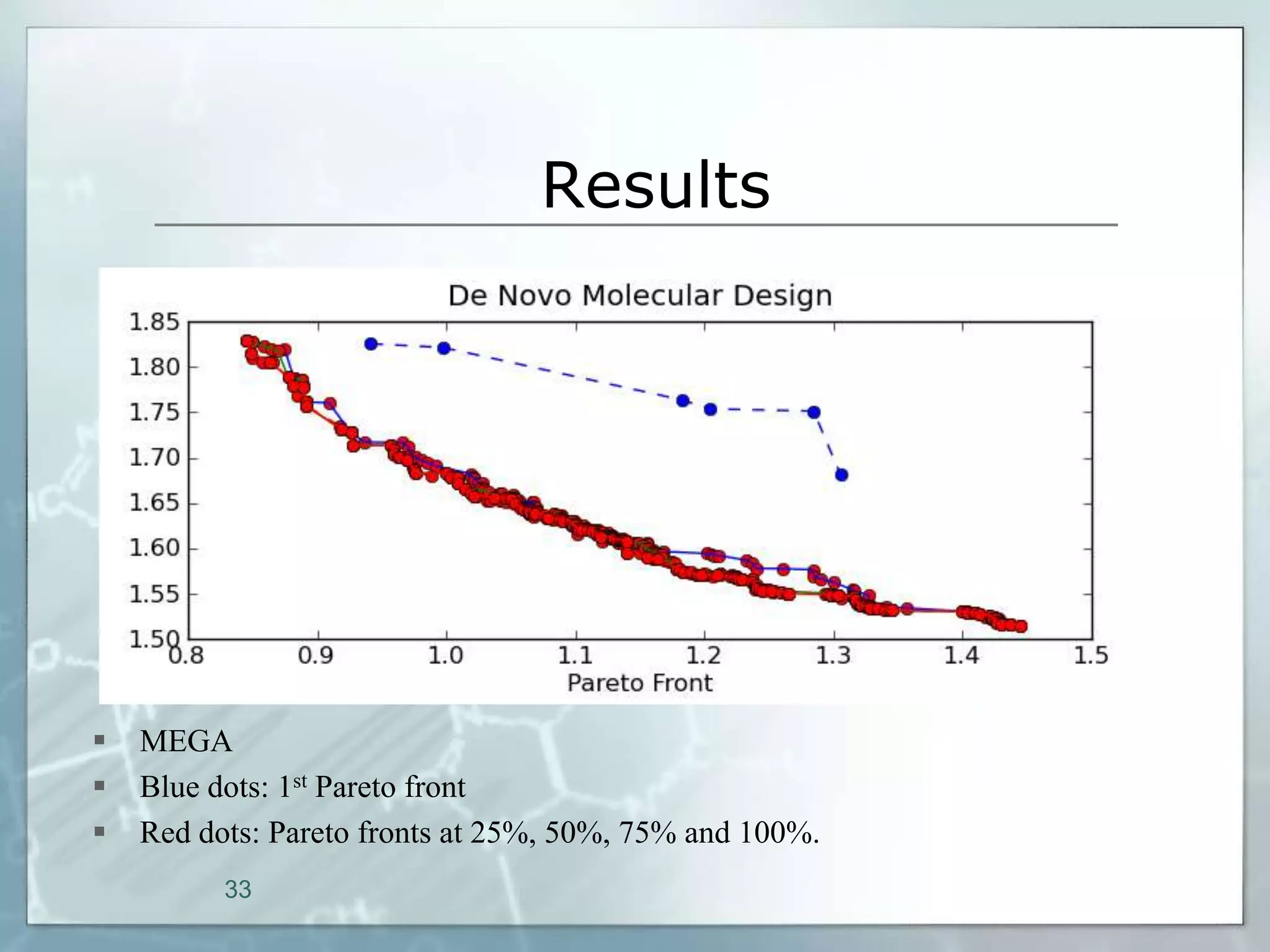
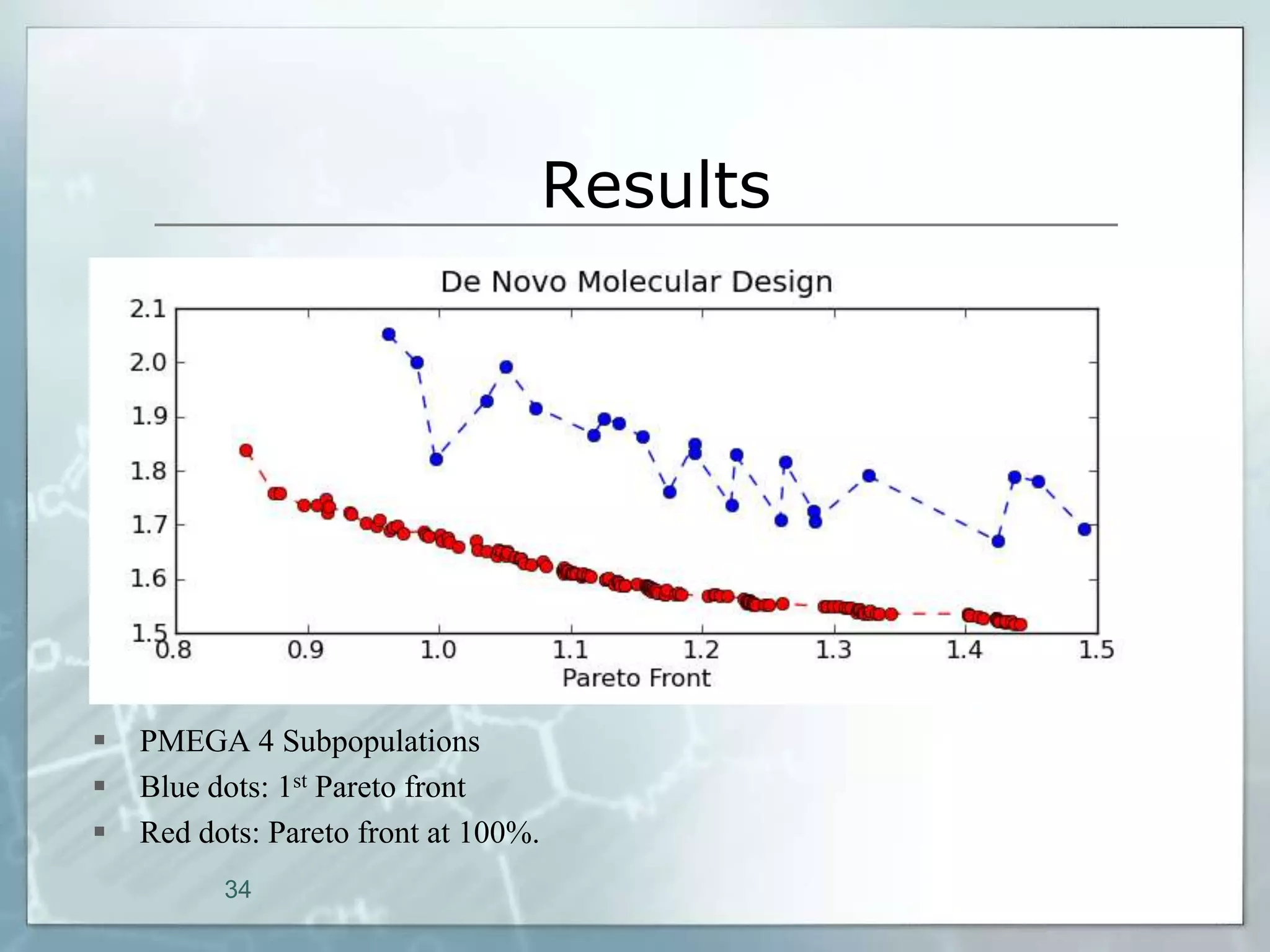
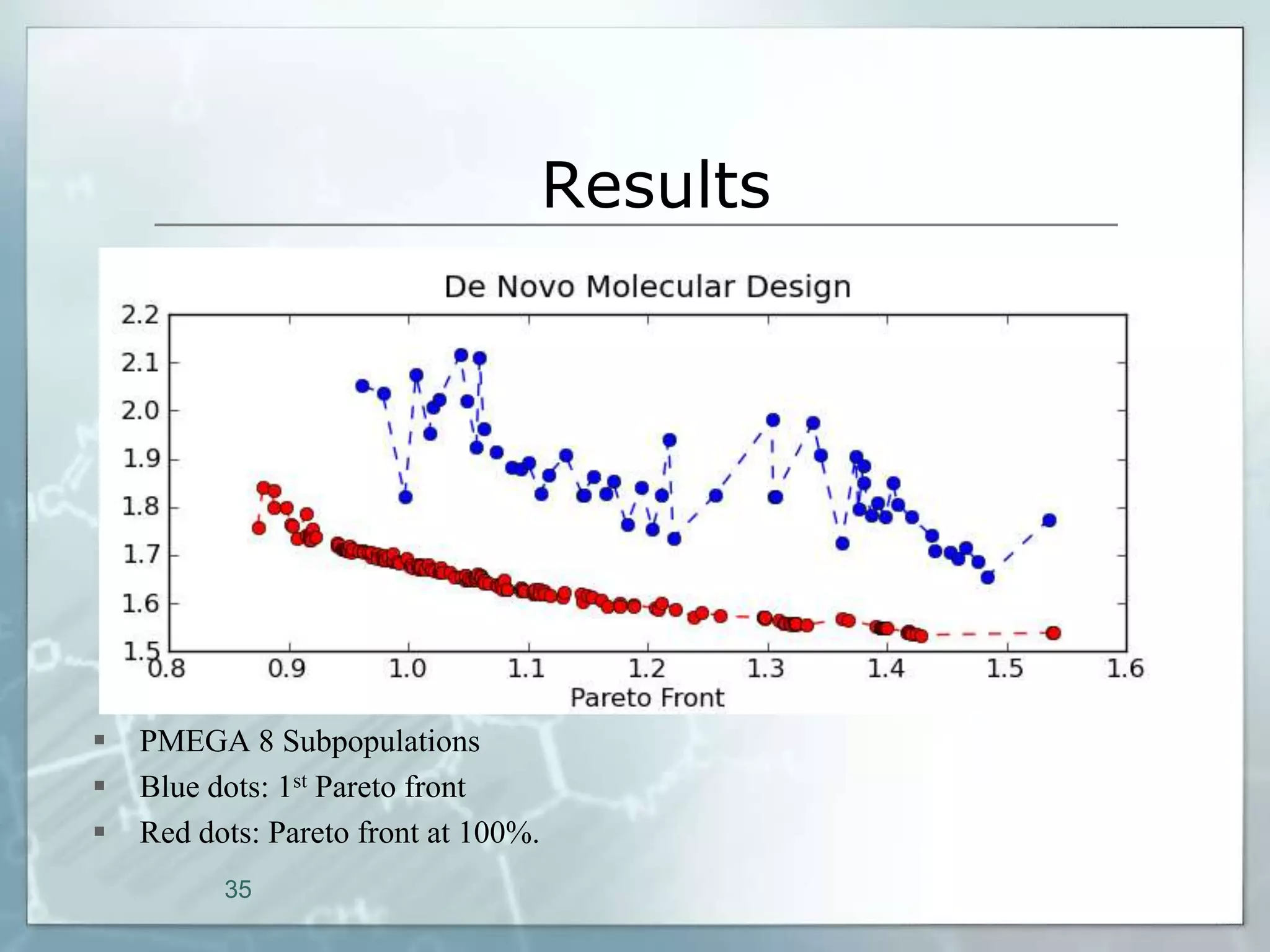
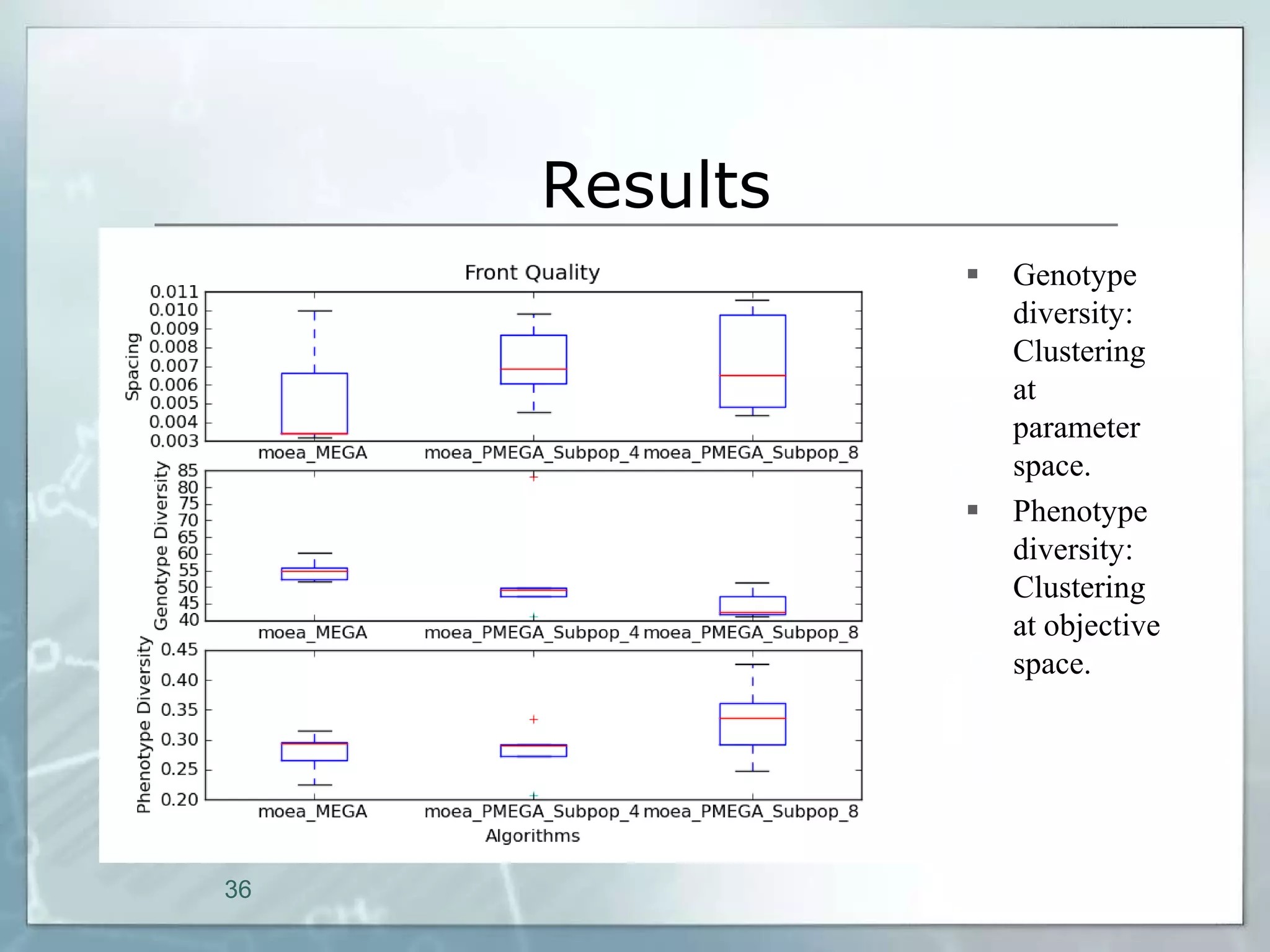
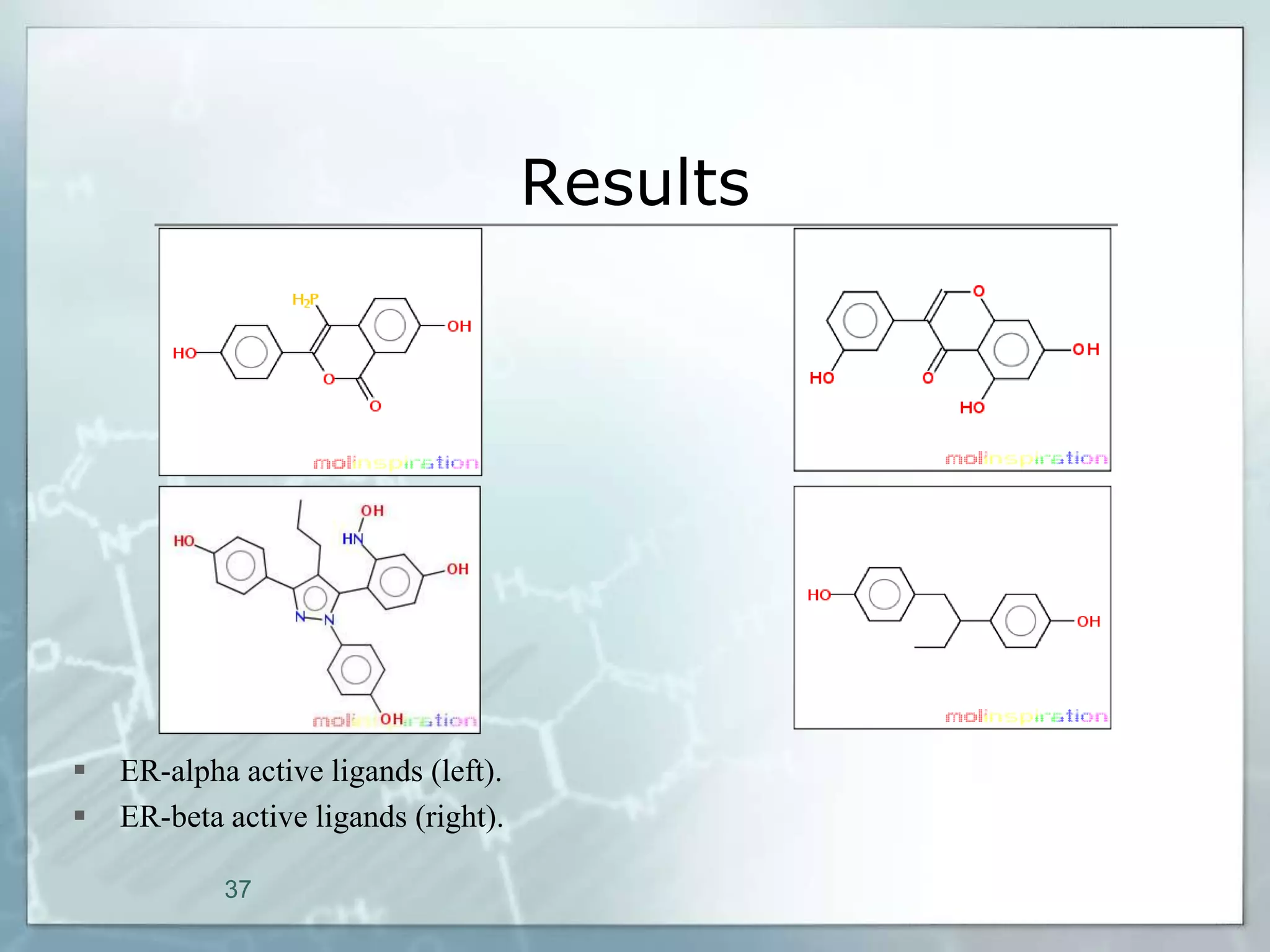



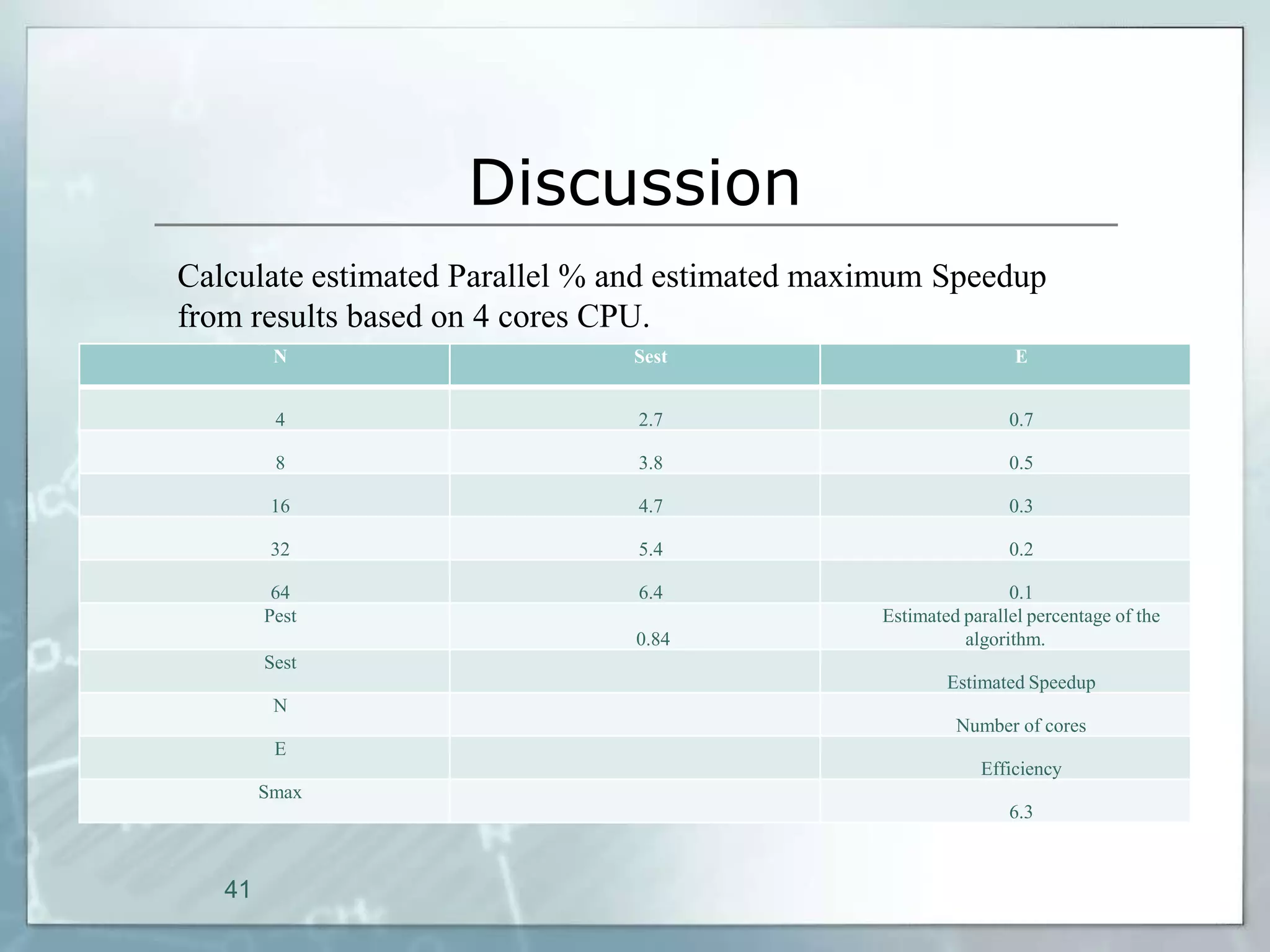










This document outlines a parallel implementation of a multi-objective evolutionary algorithm. It discusses evolutionary algorithms and their use for single and multi-objective optimization problems. It also describes how parallel evolutionary algorithms can distribute computational work across multiple cores for faster computation. The document then details a Multi-Objective Evolutionary Graph Algorithm and its parallel implementation to solve multi-objective optimization problems efficiently using parallel computing resources.








































