RDB
• リクエスト単位でユーザDB向けに Octopus.usingを指定
class ApiController < ApplicationController
around_action :select_shard
private
def select_shard(&block)
if current_user.blank?
logger.error "select_shard current_user is blank"
yield
else
Octopus.using(User.shard(current_user.id),
&block)
end
end
end
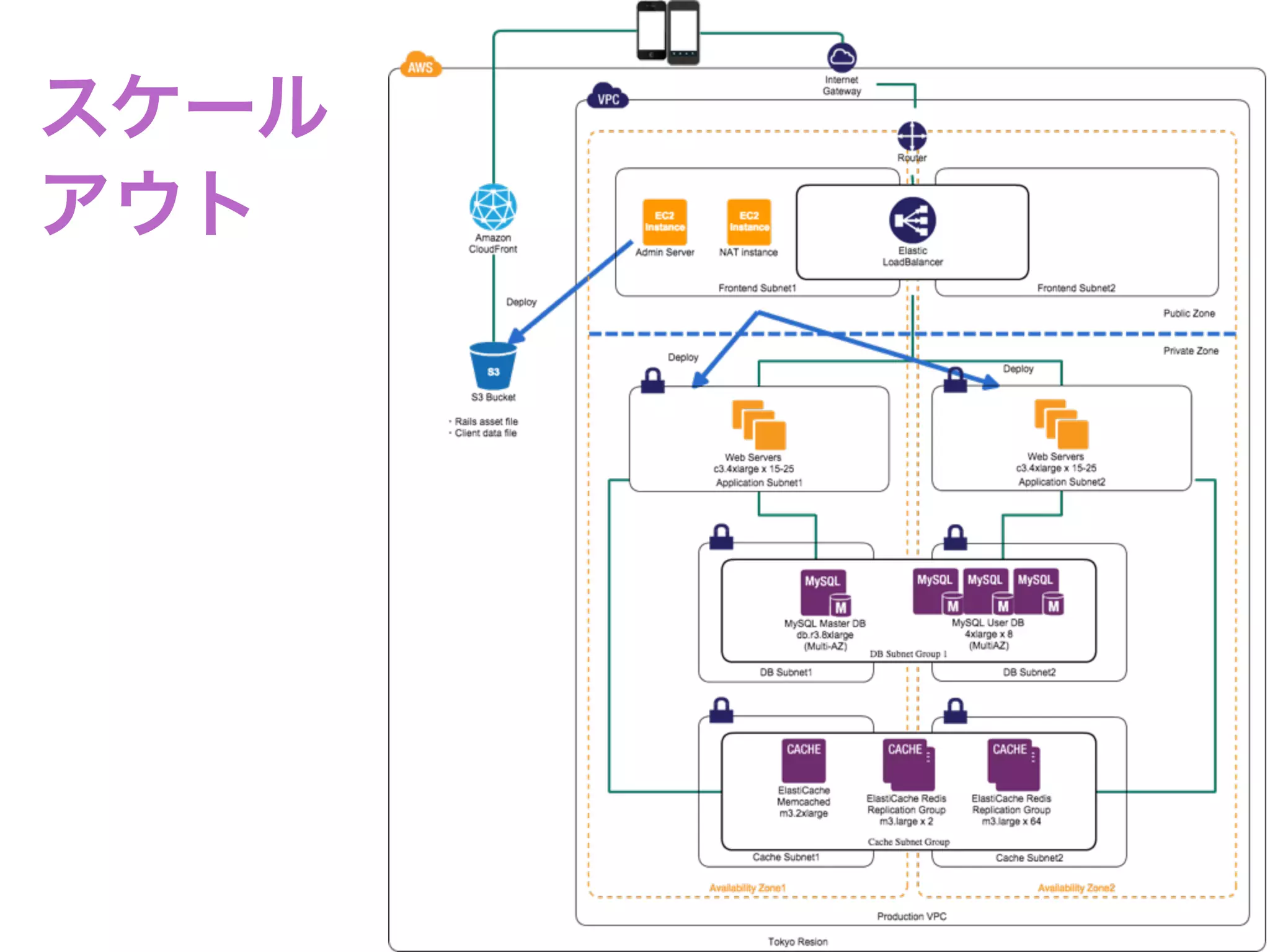
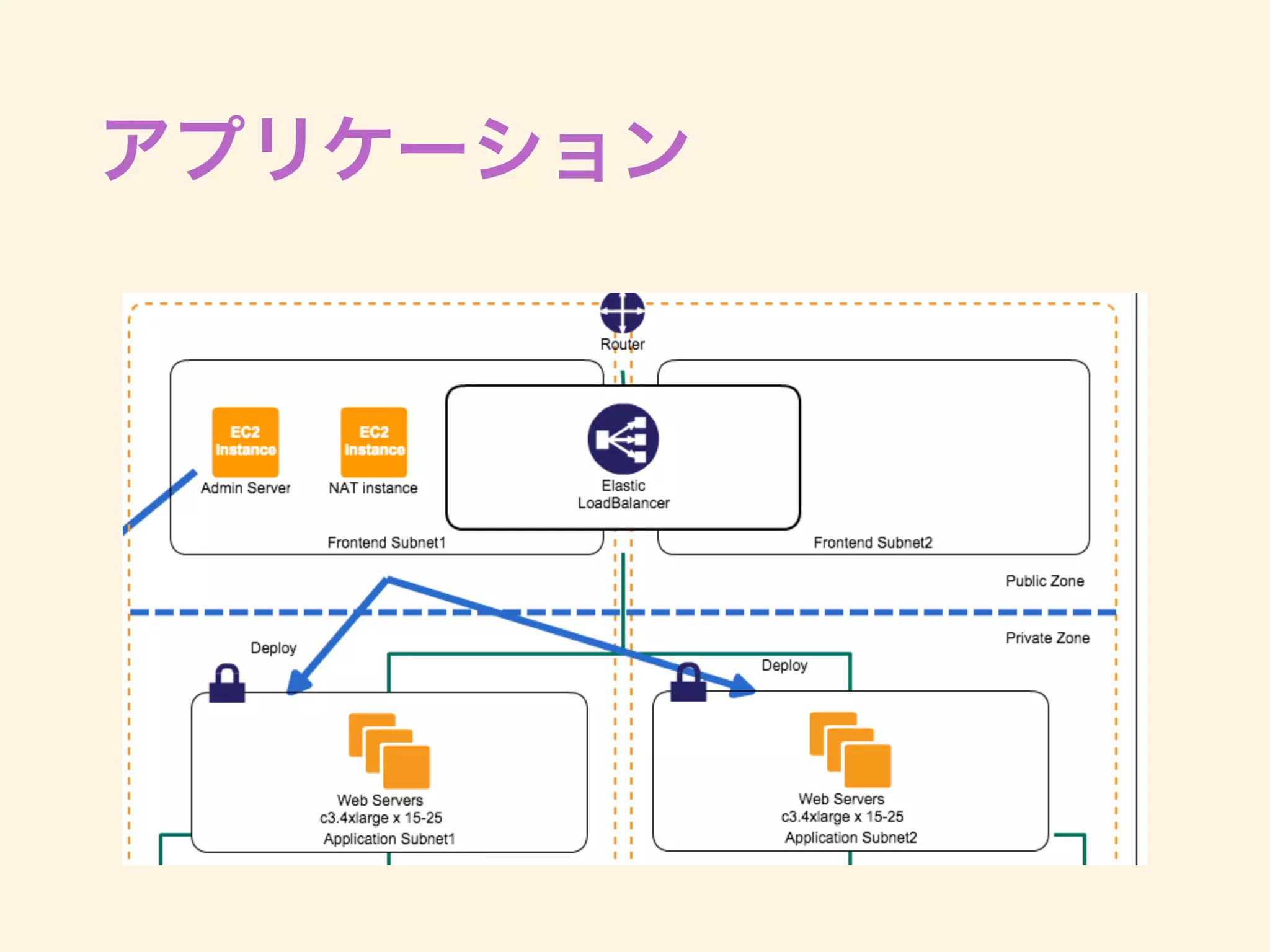
デプロイ on AWS
•Capistrano3 with EC2 tag
• EC2のタグを元に、デプロイ先を決定する
module Ec2Helper
def self.included(_klass)
::AWS.config(access_key_id: ENV['AWS_ACCESS_KEY_ID'],
secret_access_key: ENV['AWS_SECRET_ACCESS_KEY'],
max_retries: 8)
end
def tagged_servers(tag_key, tag_value, default = [])
@ec2 ||= ::AWS::EC2.new(ec2_endpoint: 'ec2.ap-northeast-1.amazonaws.com')
addresses = @ec2.instances.map do |instance|
next if instance.tags[tag_key] != tag_value
next if instance.status != :running
instance.dns_name || instance.private_dns_name || instance.ip_address
end.compact
return default if addresses.empty?
addresses
end
def ec2_tag(tag_value, *args)
::AWS.memoize do
tagged_servers(fetch(:tag_key), tag_value).each do |host|
server(host, *args)
end
end
end
end
24.
デプロイ on AWS
includeEc2Helper
set :tag_key, 'Role'
set :tag_value, ENV['EC2_TAG'] || 'app'
ec2_tag fetch(:tag_value), user: 'deployer', roles: %w(web app)
• Capistrano3 with EC2 tag
• EC2のタグを元に、デプロイ先を決定する
ruby-jmeter
extract_id =<<EOS
var json= JSON.parse(prev.getResponseDataAsString());
var id = json['key'][0]['id']
vars.put('id', id);
EOS
test do
threads count: 100 do
header({name: "Content-Type", value: "application/json"})
header({name: "X-Platform", value: "android"})
header({name: "X-ClientVersion", value: "1.0.0"})
post name: '/api_with_body', url: "#{protocol}://#{host}:#{port}/api_with_body",
raw_body: {"user_account"=>{"some_parameter"=>"SomeValue",
"some_parameter2"=>"SomeValue2"}}.to_json do
extract name: 'return_value', regex: %q{"value":s?([d]+)}
end
get name: '/get_api', url: "#{protocol}://#{host}:#{port}/get_api/#{return_value}"
post name: "/api/js", url: "#{protocol}://#{host}:#{port}/api/js", raw_body:
params.to_json do
bsf_postprocessor name: "extract_id", scriptLanguage: 'javascript', script: extract_id
end
end
end.jmx
ruby-jmeter
test do
threads count:100 do
post name: '/api_with_body', url: "#{protocol}://
#{host}:#{port}/api_with_body", raw_body:
{"user_account"=>{"some_parameter"=>"SomeValue",
"some_parameter2"=>"SomeValue2"}}.to_json do
end
end
end.jmx
• リクエストBodyの指定
35.
ruby-jmeter
test do
threads count:100 do
post name: '/api_with_body', url: "#{protocol}://
#{host}:#{port}/api_with_body", raw_body:
{"user_account"=>{"some_parameter"=>"SomeValue",
"some_parameter2"=>"SomeValue2"}}.to_json do
extract name: 'return_value', regex: %q{"value":s?([d]+)}
end
end
end.jmx
• レスポンスBodyから、正規表現で値を抽出 to ‘return_value’
36.
ruby-jmeter
test do
threads count:100 do
get name: '/get_api', url: "#{protocol}://#{host}:#{port}/
get_api/#{return_value}"
end
end.jmx
• ‘return_value’ を使って、GETリクエスト
37.
ruby-jmeter
extract_id =<<EOS
var json= JSON.parse(prev.getResponseDataAsString());
var id = json['key'][0]['id']
vars.put('id', id);
EOS
test do
threads count: 100 do
post name: "/api/js", url: "#{protocol}://#{host}:#{port}/api/js",
raw_body: params.to_json do
bsf_postprocessor name: "extract_id", scriptLanguage: 'javascript',
script: extract_id
end
end
end.jmx
• レスポンスBodyから、JavaScriptを使って値を抽出 to ‘extract_id’















![RDB
• すると、ゲームデータ(1DB)へのアクセスは、ActiveRecord
レベルでusing(:master)を指定することになる
• 以下の様に、ActiveRecord::Baseを継承して、Baseモデル
を作りたい
class MasterModel < ActiveRecord::Base
self.abstract_class = true
octopus_establish_connection(Rails.configuration.database_configuration[Rails.env])
end
class Card < MasterModel
end](https://image.slidesharecdn.com/hikarabo-150518025128-lva1-app6892/75/RoR-AWS-100-000Req-Min-18-2048.jpg)




![デプロイ on AWS
• Capistrano3 with EC2 tag
• EC2のタグを元に、デプロイ先を決定する
module Ec2Helper
def self.included(_klass)
::AWS.config(access_key_id: ENV['AWS_ACCESS_KEY_ID'],
secret_access_key: ENV['AWS_SECRET_ACCESS_KEY'],
max_retries: 8)
end
def tagged_servers(tag_key, tag_value, default = [])
@ec2 ||= ::AWS::EC2.new(ec2_endpoint: 'ec2.ap-northeast-1.amazonaws.com')
addresses = @ec2.instances.map do |instance|
next if instance.tags[tag_key] != tag_value
next if instance.status != :running
instance.dns_name || instance.private_dns_name || instance.ip_address
end.compact
return default if addresses.empty?
addresses
end
def ec2_tag(tag_value, *args)
::AWS.memoize do
tagged_servers(fetch(:tag_key), tag_value).each do |host|
server(host, *args)
end
end
end
end](https://image.slidesharecdn.com/hikarabo-150518025128-lva1-app6892/75/RoR-AWS-100-000Req-Min-23-2048.jpg)
![デプロイ on AWS
include Ec2Helper
set :tag_key, 'Role'
set :tag_value, ENV['EC2_TAG'] || 'app'
ec2_tag fetch(:tag_value), user: 'deployer', roles: %w(web app)
• Capistrano3 with EC2 tag
• EC2のタグを元に、デプロイ先を決定する](https://image.slidesharecdn.com/hikarabo-150518025128-lva1-app6892/75/RoR-AWS-100-000Req-Min-24-2048.jpg)





![ruby-jmeter
extract_id =<<EOS
var json = JSON.parse(prev.getResponseDataAsString());
var id = json['key'][0]['id']
vars.put('id', id);
EOS
test do
threads count: 100 do
header({name: "Content-Type", value: "application/json"})
header({name: "X-Platform", value: "android"})
header({name: "X-ClientVersion", value: "1.0.0"})
post name: '/api_with_body', url: "#{protocol}://#{host}:#{port}/api_with_body",
raw_body: {"user_account"=>{"some_parameter"=>"SomeValue",
"some_parameter2"=>"SomeValue2"}}.to_json do
extract name: 'return_value', regex: %q{"value":s?([d]+)}
end
get name: '/get_api', url: "#{protocol}://#{host}:#{port}/get_api/#{return_value}"
post name: "/api/js", url: "#{protocol}://#{host}:#{port}/api/js", raw_body:
params.to_json do
bsf_postprocessor name: "extract_id", scriptLanguage: 'javascript', script: extract_id
end
end
end.jmx](https://image.slidesharecdn.com/hikarabo-150518025128-lva1-app6892/75/RoR-AWS-100-000Req-Min-31-2048.jpg)



![ruby-jmeter
test do
threads count: 100 do
post name: '/api_with_body', url: "#{protocol}://
#{host}:#{port}/api_with_body", raw_body:
{"user_account"=>{"some_parameter"=>"SomeValue",
"some_parameter2"=>"SomeValue2"}}.to_json do
extract name: 'return_value', regex: %q{"value":s?([d]+)}
end
end
end.jmx
• レスポンスBodyから、正規表現で値を抽出 to ‘return_value’](https://image.slidesharecdn.com/hikarabo-150518025128-lva1-app6892/75/RoR-AWS-100-000Req-Min-35-2048.jpg)

![ruby-jmeter
extract_id =<<EOS
var json = JSON.parse(prev.getResponseDataAsString());
var id = json['key'][0]['id']
vars.put('id', id);
EOS
test do
threads count: 100 do
post name: "/api/js", url: "#{protocol}://#{host}:#{port}/api/js",
raw_body: params.to_json do
bsf_postprocessor name: "extract_id", scriptLanguage: 'javascript',
script: extract_id
end
end
end.jmx
• レスポンスBodyから、JavaScriptを使って値を抽出 to ‘extract_id’](https://image.slidesharecdn.com/hikarabo-150518025128-lva1-app6892/75/RoR-AWS-100-000Req-Min-37-2048.jpg)














![NewRelic
• 以下設定しておいて、環境変数で切り替え
• 実運用では、5台適当に選択して有効にしている
• デプロイでサーバが変わることがあるが、利用料金は
5台で済む
production:
<<: *default_settings
monitor_mode: <%= ENV['NEWRELIC_MONITOR_MODE'] || "false" %>](https://image.slidesharecdn.com/hikarabo-150518025128-lva1-app6892/75/RoR-AWS-100-000Req-Min-52-2048.jpg)
![• dotenv-rails + Capistrano
• role(:app)のサーバを数台選択し、”NEWRELIC_MONITOR_MODE=true”
を設定して配布
NewRelic
# config/deploy/production.rb
set :newrelic_monitor_number, 5
# lib/capistrano/tasks/deploy.rake
namespace :deploy do
desc 'Upload added NEWRELIC_MONITOR_MODE=true .env file'
task :upload_newrelic_env do
monitor_true = "NEWRELIC_MONITOR_MODE=truen"
temp = Tempfile.new("env")
tempfile = temp.path
temp.write(File.open(".env", "r").read)
temp.write(monitor_true)
temp.close
on roles(:app).to_ary[0...fetch(:newrelic_monitor_number).to_i] do |host|
upload! tempfile, File.join(shared_path, ".env")
end
FileUtils.rm(tempfile)
end
end](https://image.slidesharecdn.com/hikarabo-150518025128-lva1-app6892/75/RoR-AWS-100-000Req-Min-53-2048.jpg)





![[AC08] 新世代のアーキテクチャに移行せよ。富士フイルムの事例に学ぶ、クラウドネイティブソリューションのビジョンと設計](https://cdn.slidesharecdn.com/ss_thumbnails/ac08-170602093745-thumbnail.jpg?width=640&height=640&fit=bounds)












![[GOJAS] クラウドワークスタイルとSplunk](https://cdn.slidesharecdn.com/ss_thumbnails/gojassplunk20170728-170729063715-thumbnail.jpg?width=640&height=640&fit=bounds)











































