Download as ODP, PPTX








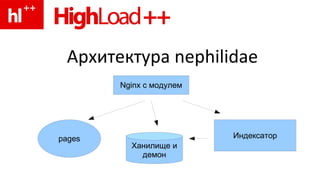




Документ описывает архитектуру системы Nephilidae для обработки миллионов запросов к страницам сайтов с высокими нагрузками и минимальными задержками. Включает различные оптимизационные подходы по хранению и индексации страниц, а также проблемы, с которыми сталкивалась система. Основной задачей является разработка эффективной файловой системы, чтобы улучшить производительность и сократить трафик между датацентрами.











































































