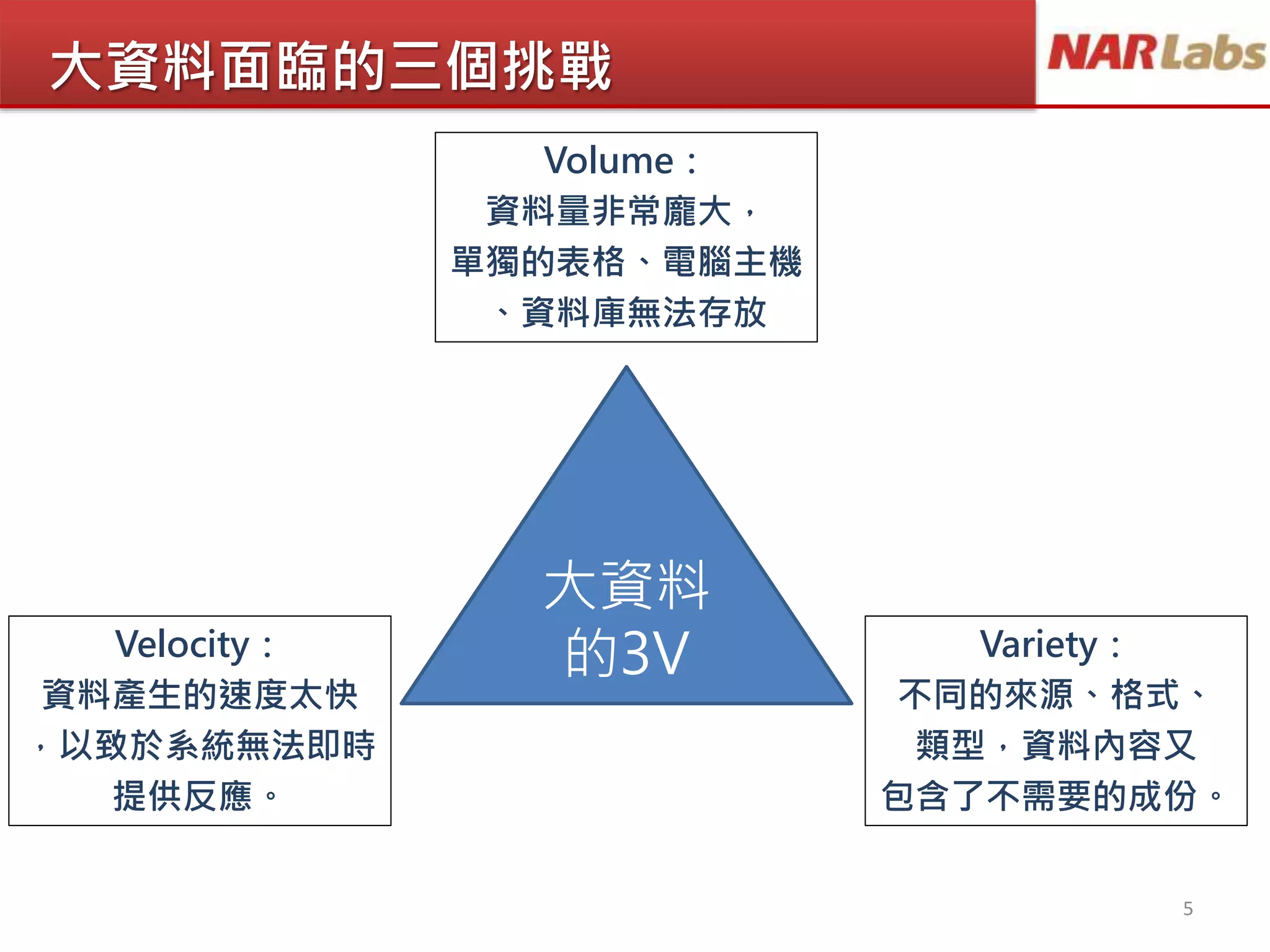
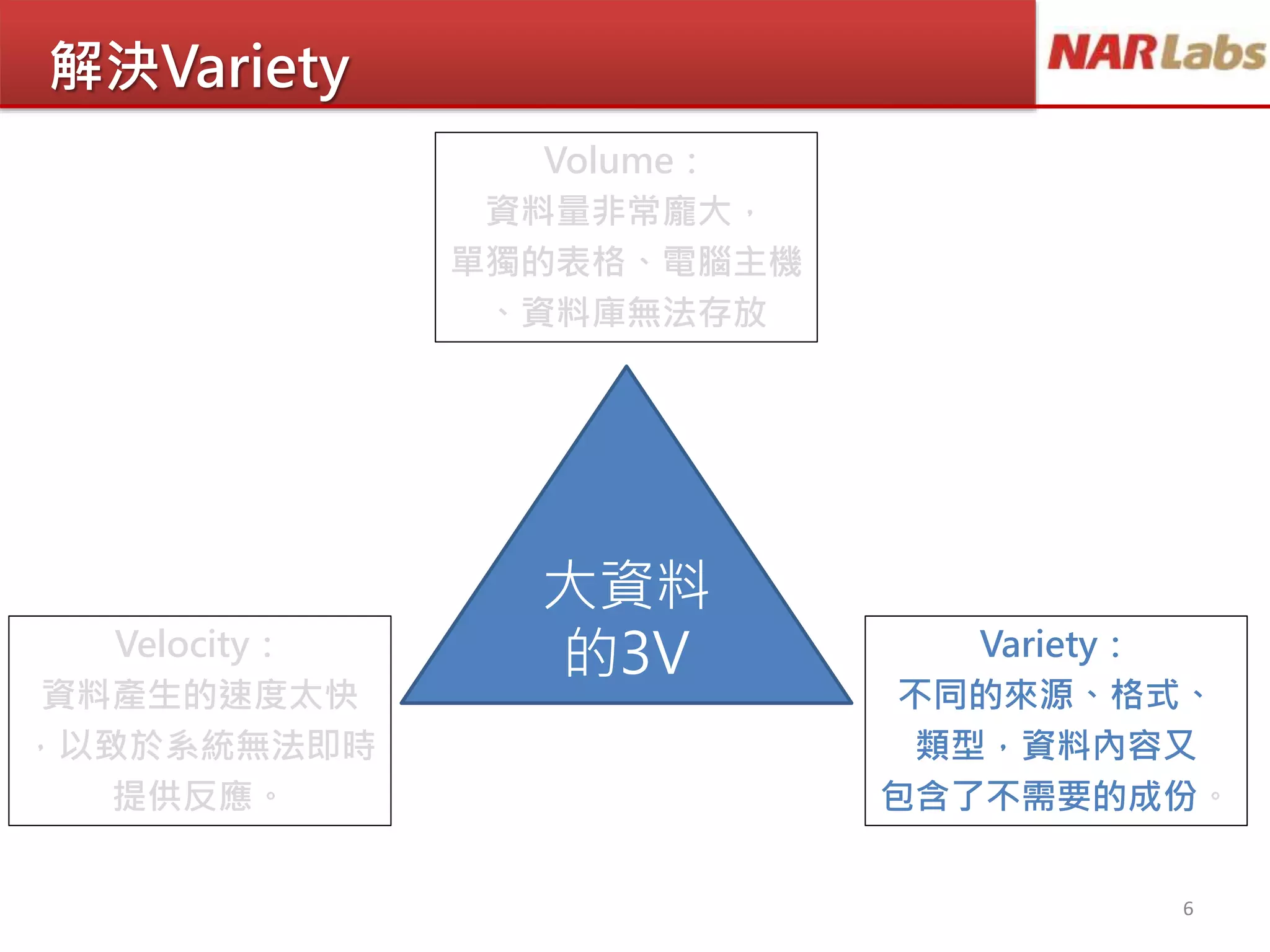
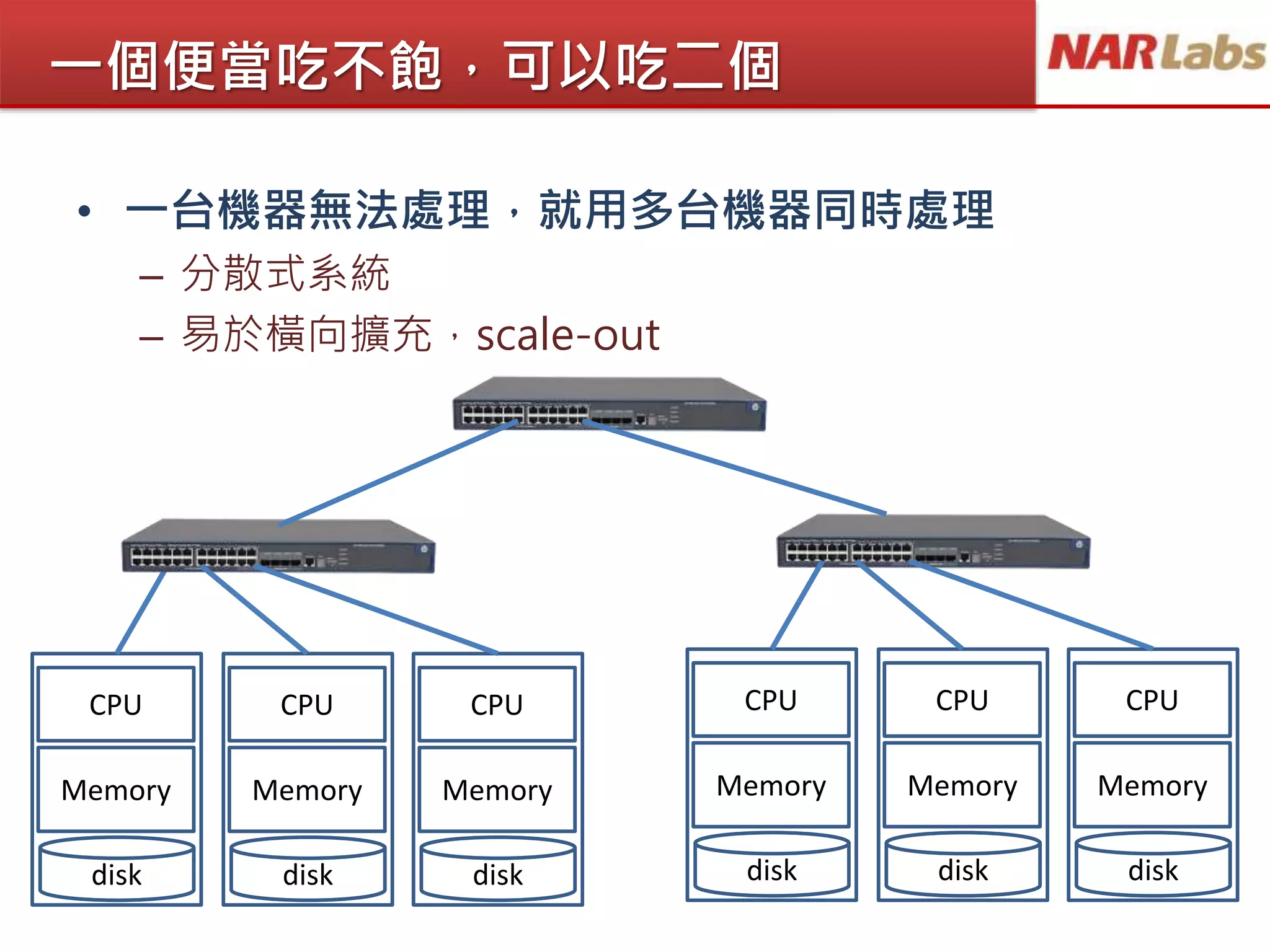
文档讨论大数据分析技术的发展,重点介绍了Hadoop和MapReduce的作用及其在处理大数据面临的挑战。通过分散式系统解决数据的体量、速度和多样性问题,并强调数据清洗的重要性。最后,文档提到了常用的Hadoop平台及其在大数据分析中的应用和教育支持。








![分散式系統的挑戰
• CAP定理
– 資料一致性:[C]onsistency
– 系統可用系:[A]vailability
– 分區容忍性:[P]artition Tolerance
• 全世界最大的廣告公司Google
– 提出GFS、MapReduce、BigTable等針對大資料應用
的分散式技術
13](https://image.slidesharecdn.com/0720-150721055155-lva1-app6891/75/slide-13-2048.jpg)




![台灣最熱衷的全民運動
18
•台北市10個選區,共100萬票,要算出每個候選人的得票數
Id:A151
選2號 Id:B257
選5號
號次 票數
1 1
1 1
3 1
… …
號次 票數
2 1
1 1
… …
號次 票數
3 1
2 1
1 1
號次 票數
1 1
3 1
3 …
號次 票數
3 1
2 1
3 1
監票人1
[負責1區]
監票人2
[負責2區]
監票人3
[負責3區]
監票人4
[負責4區]
監票人5
[負責5區]](https://image.slidesharecdn.com/0720-150721055155-lva1-app6891/75/slide-18-2048.jpg)
![號次 票數
1 1
1 1
1 1
1 1
1 …
中選會
[負責 全部的候選人]
號次 票數
5 1
1 1
7 1
… …
號次 票數
2 1
1 1
… …
號次 票數
5 1
2 1
1 1
號次 票數
1 1
5 1
3 …
號次 票數
4 1
2 1
6 1
由各投開票所送到中選會
號次 票數
2 1
2 1
2 1
2 1
2 …
號次 票數
3 1
3 1
3 1
3 1
3 …
19
號次 總票數
1 187532
號次 總票數
2 574821
號次 總票數
3 237647](https://image.slidesharecdn.com/0720-150721055155-lva1-app6891/75/slide-19-2048.jpg)