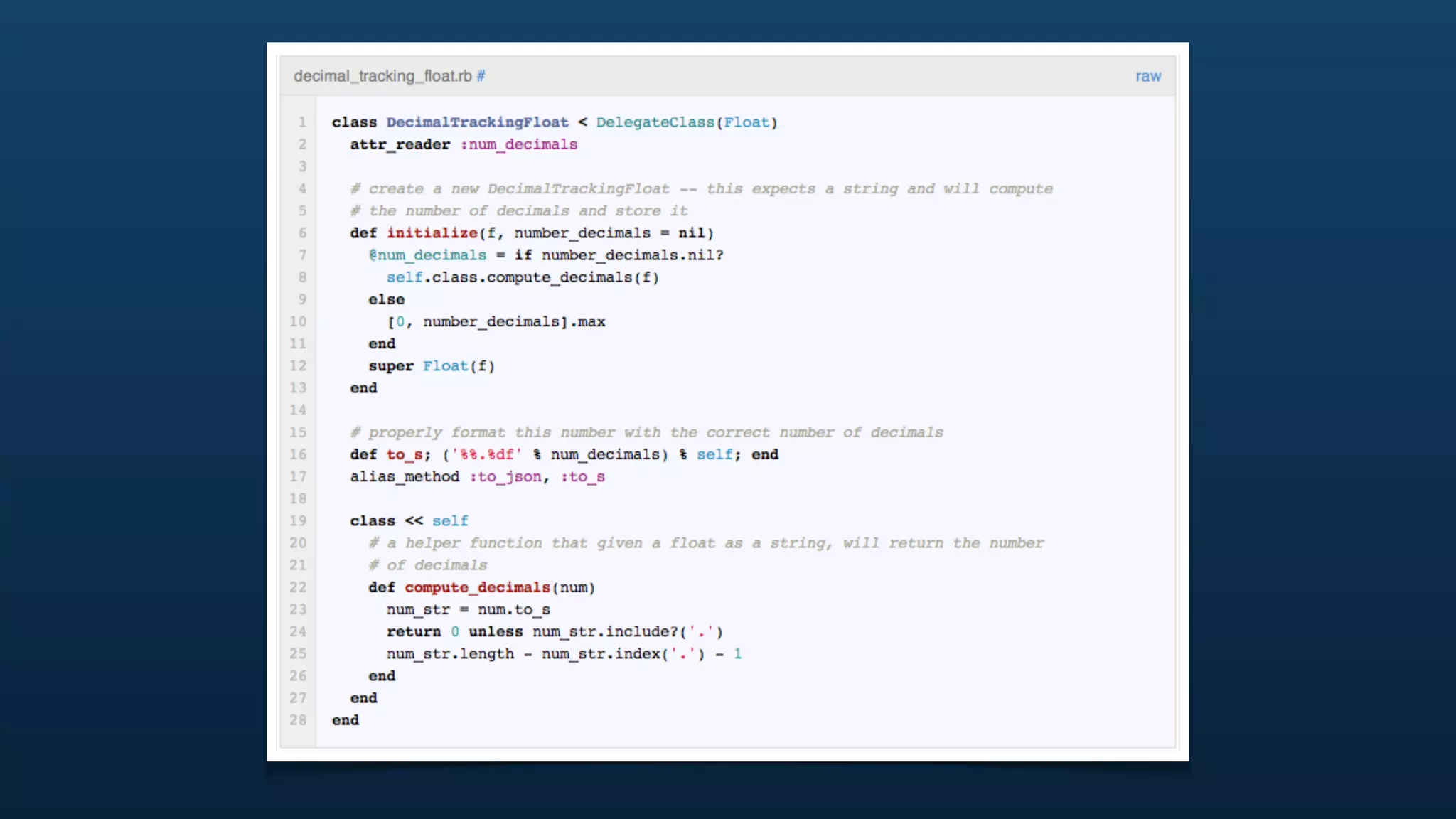
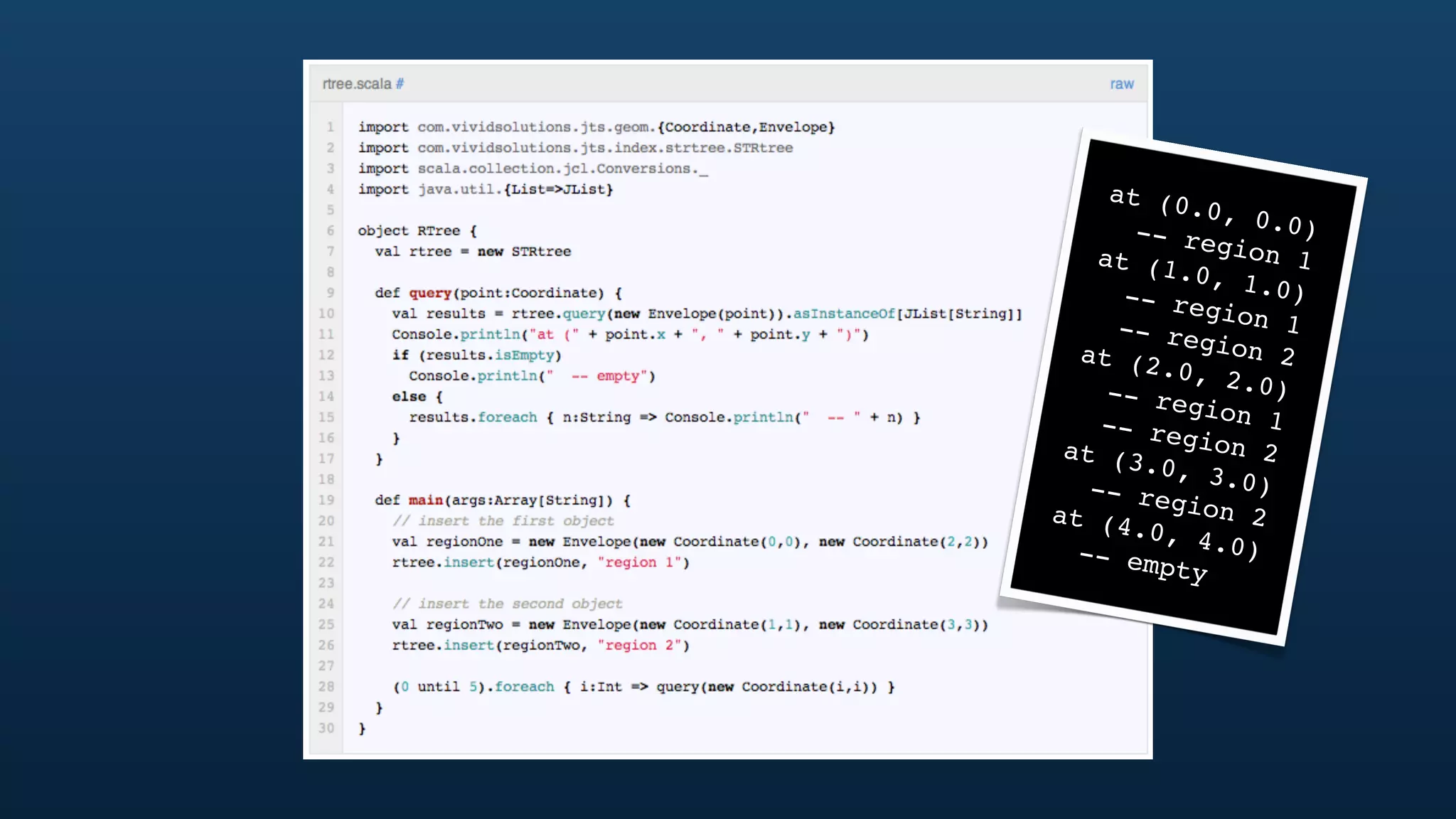
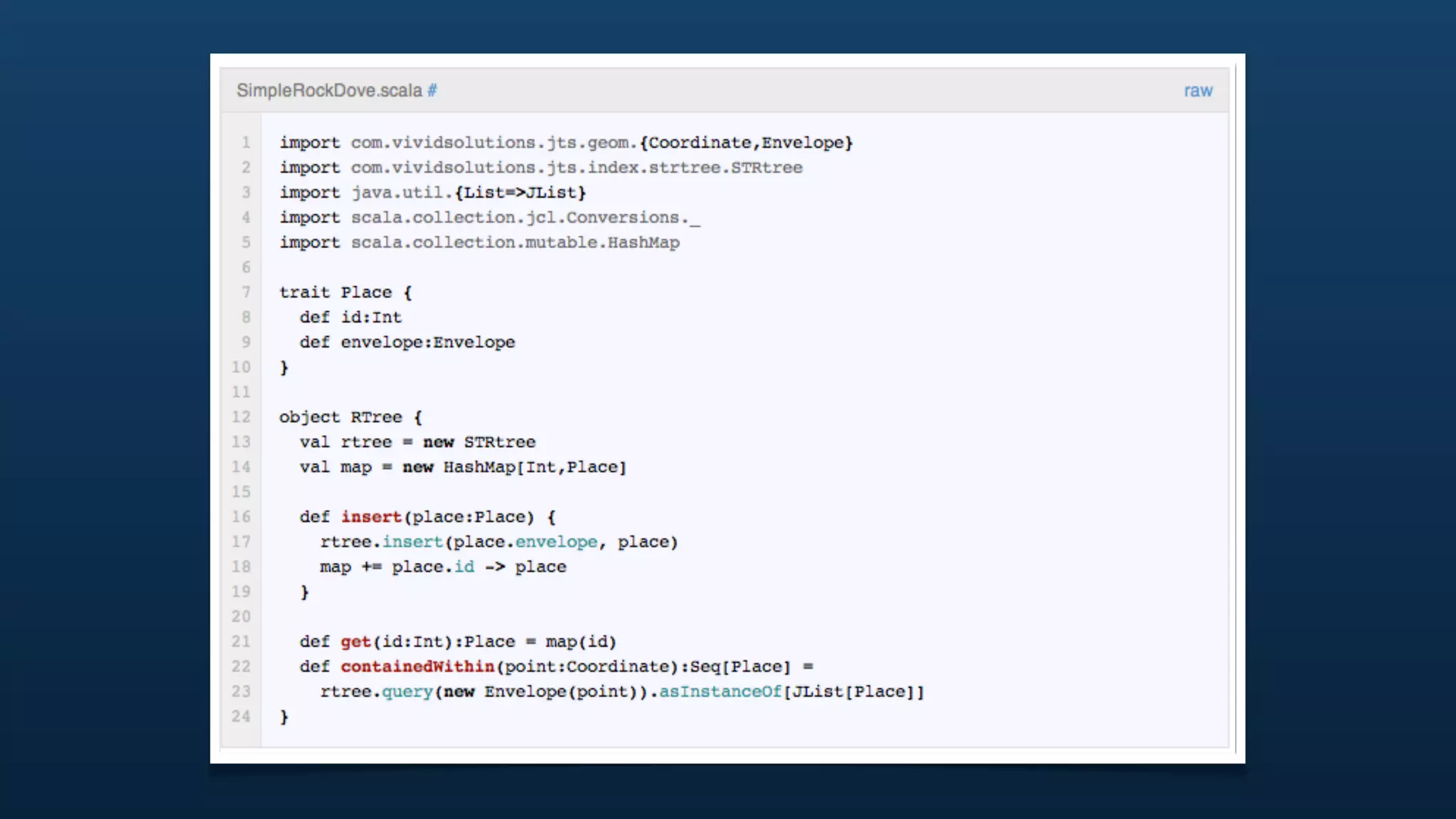
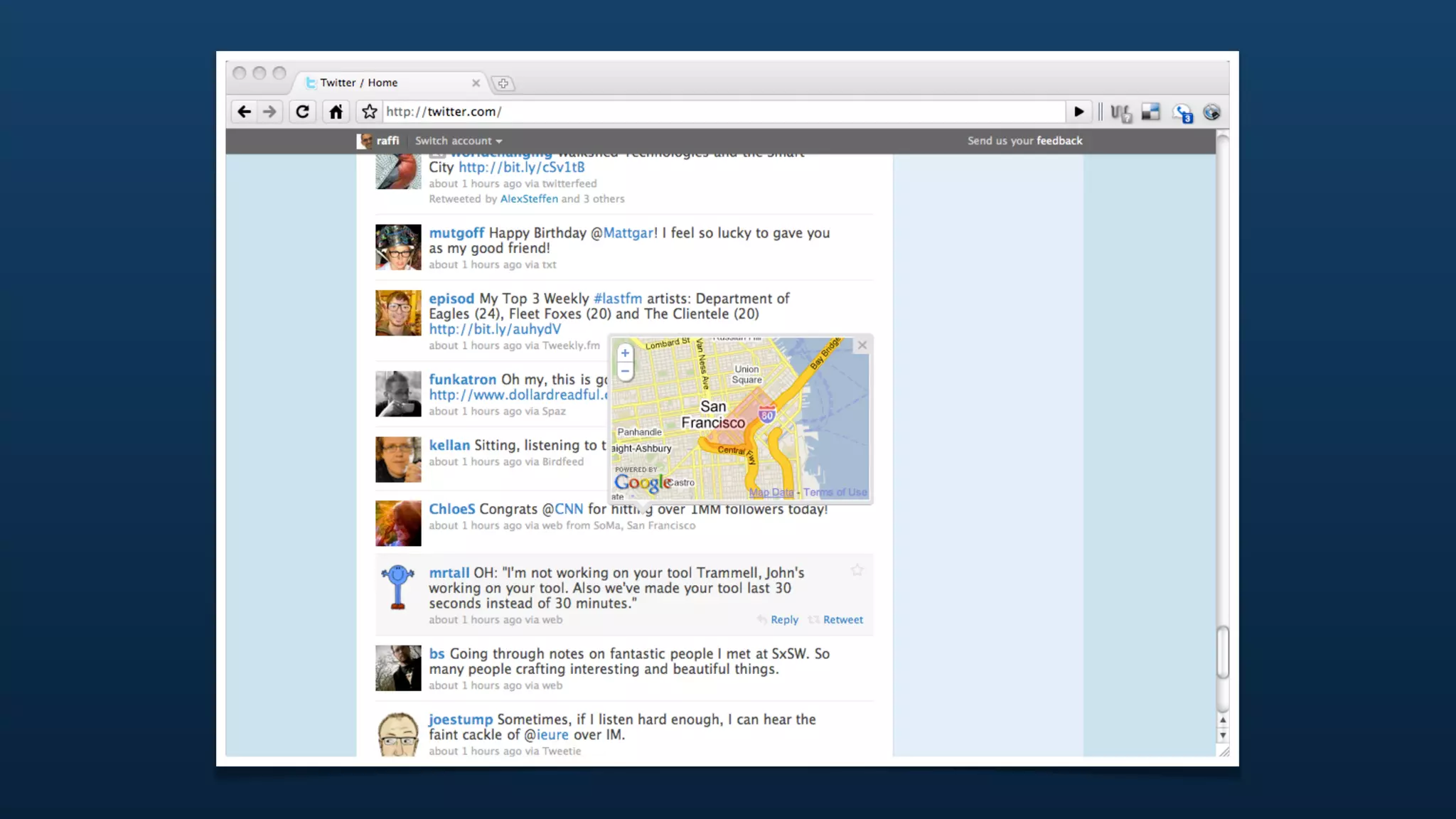
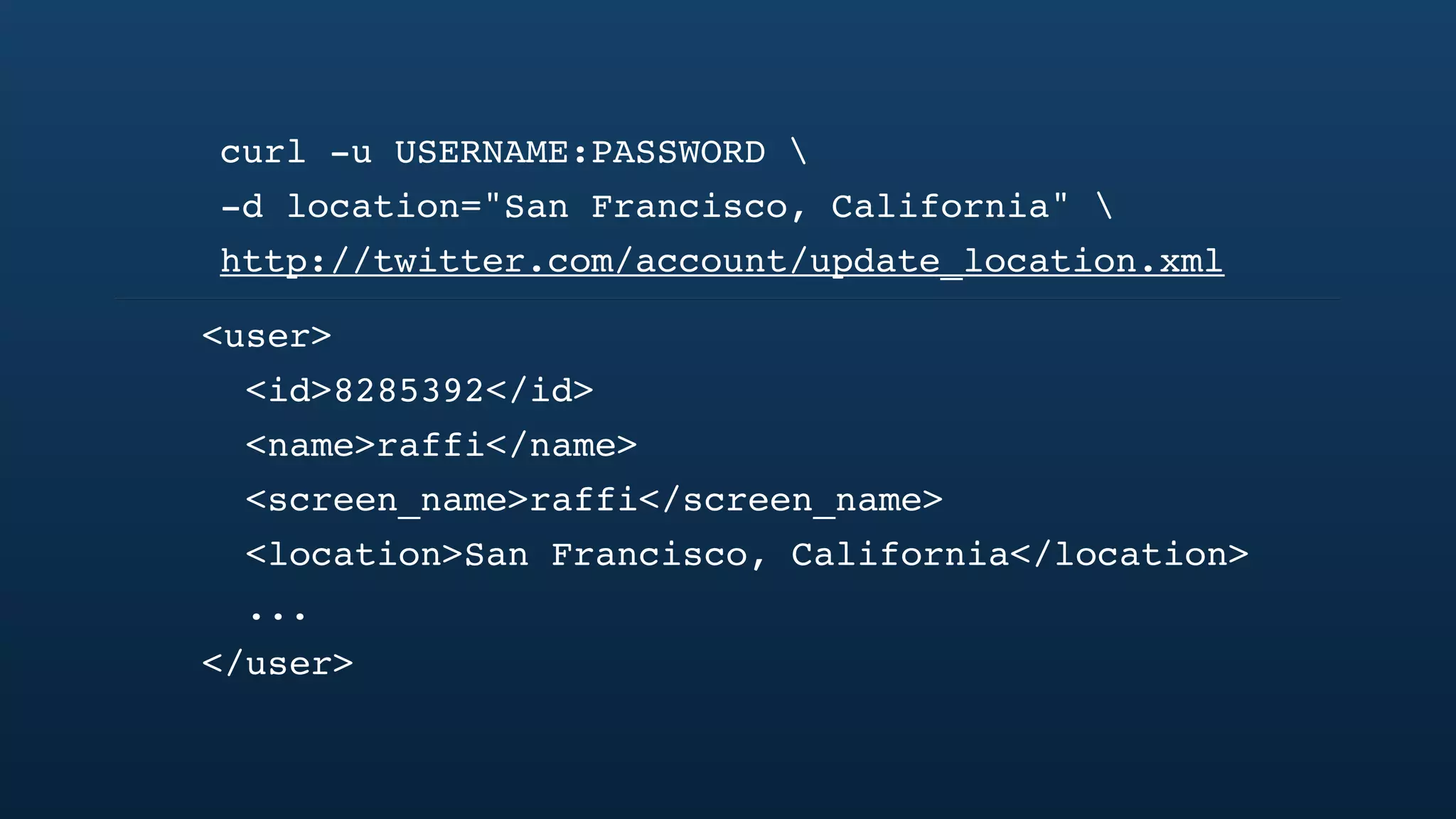
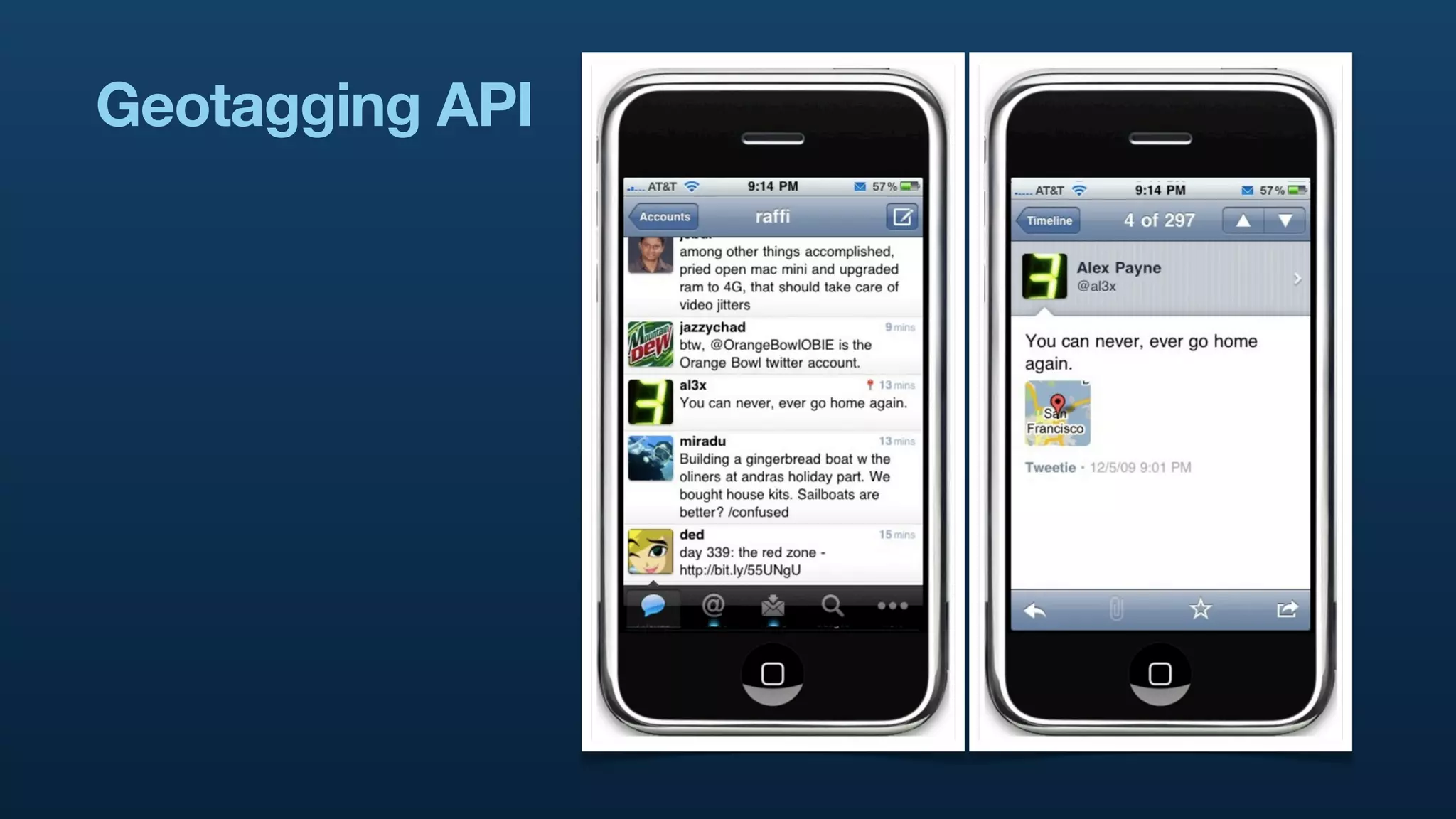
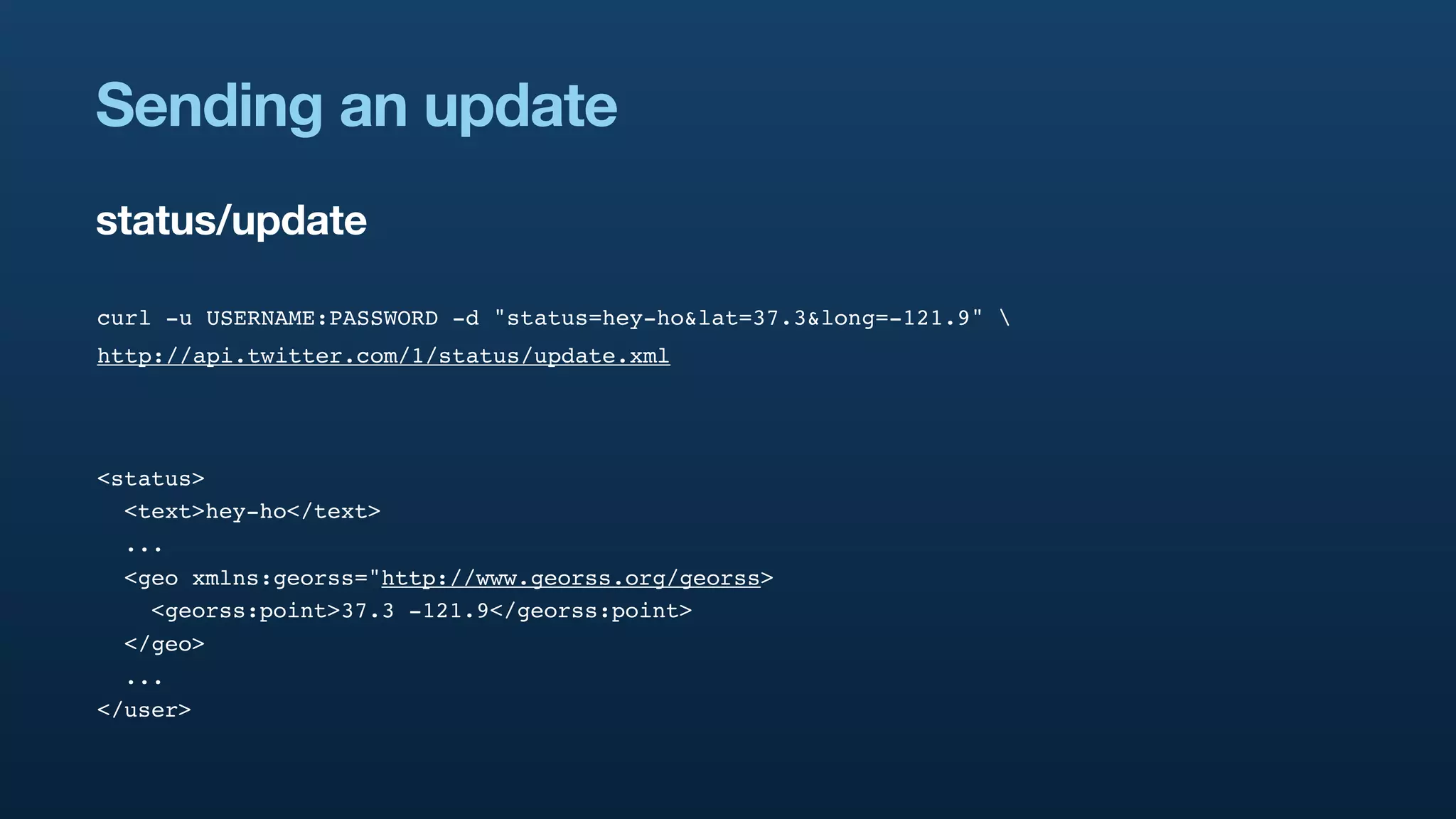
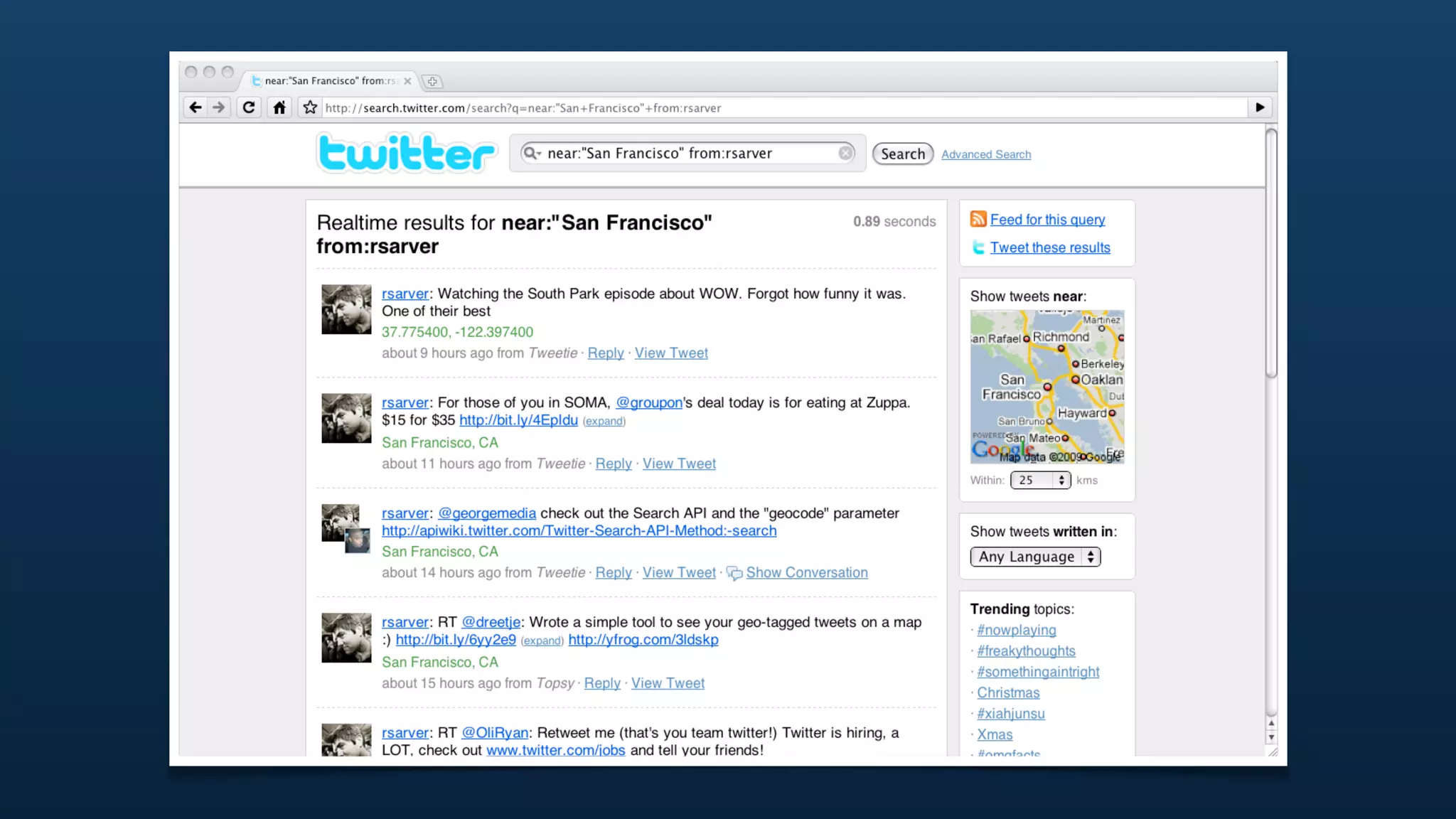
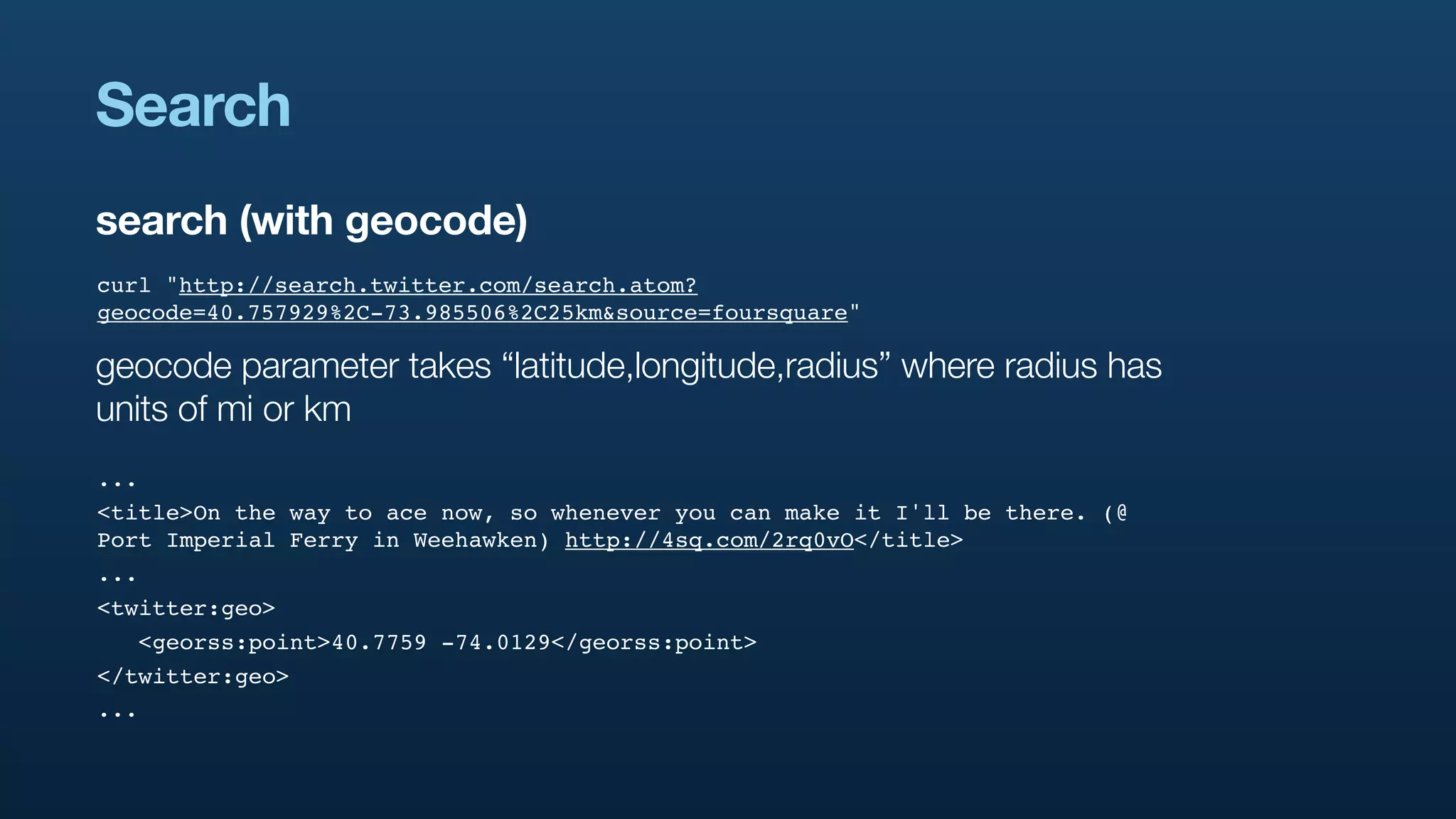
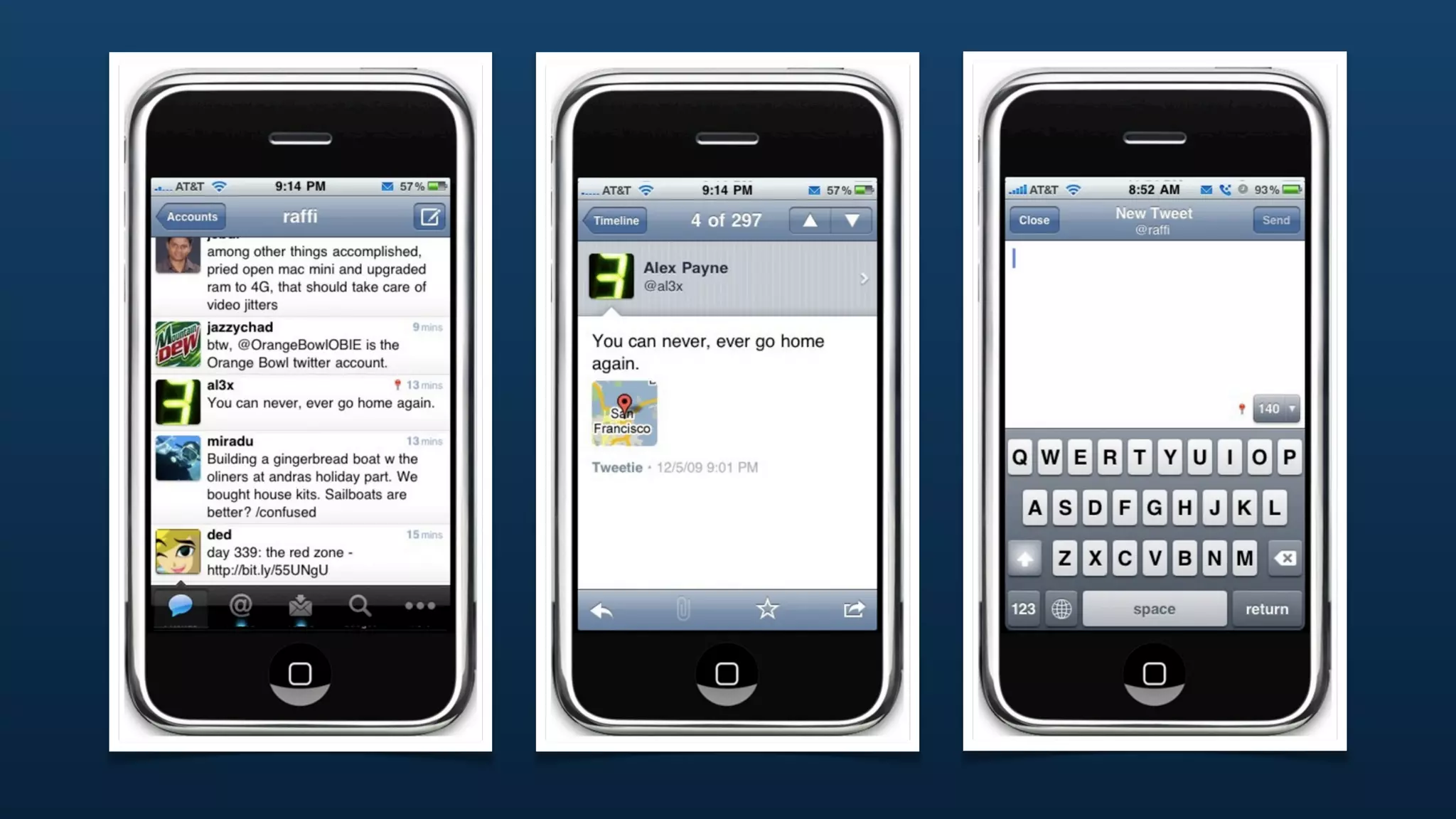
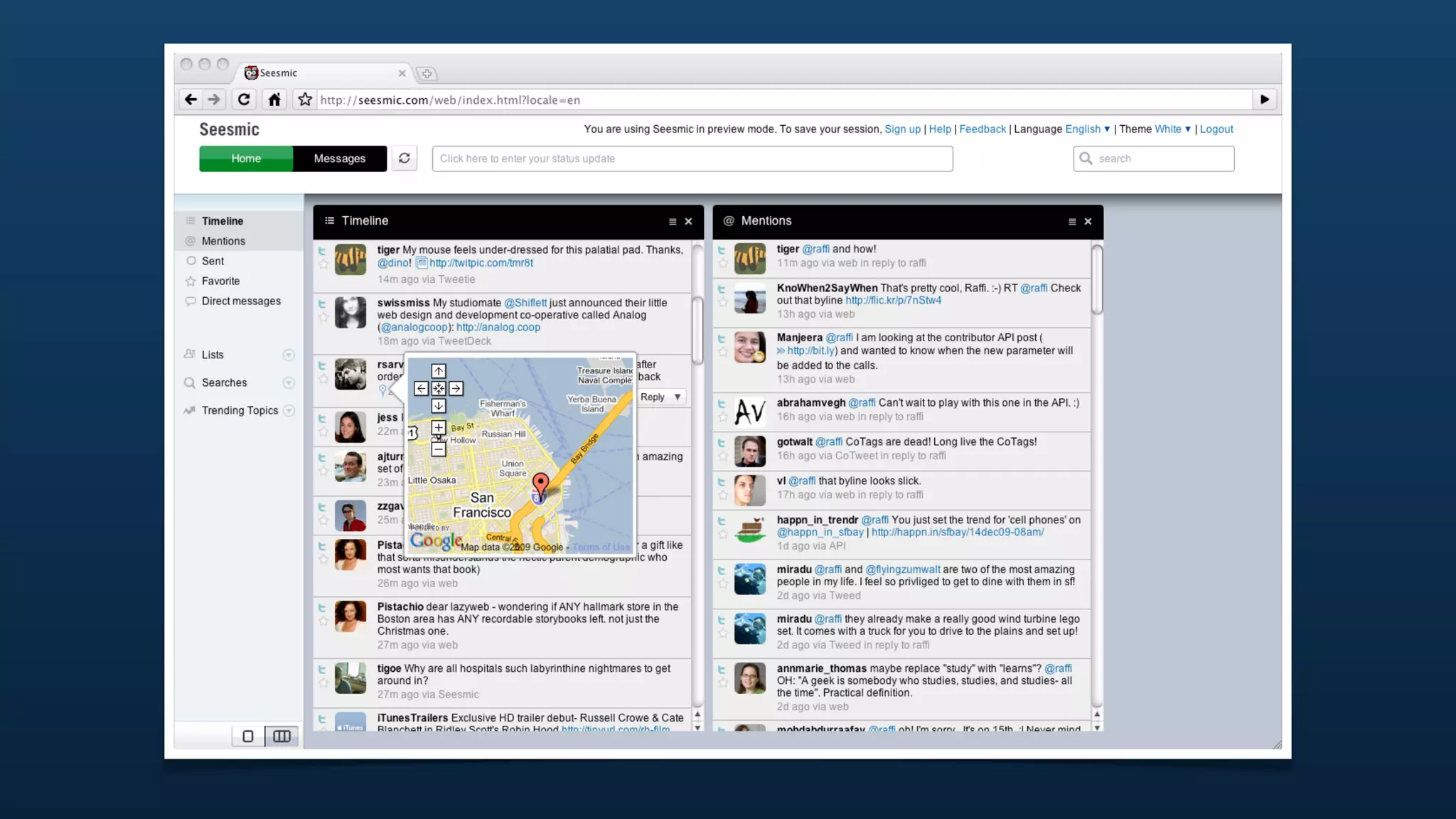
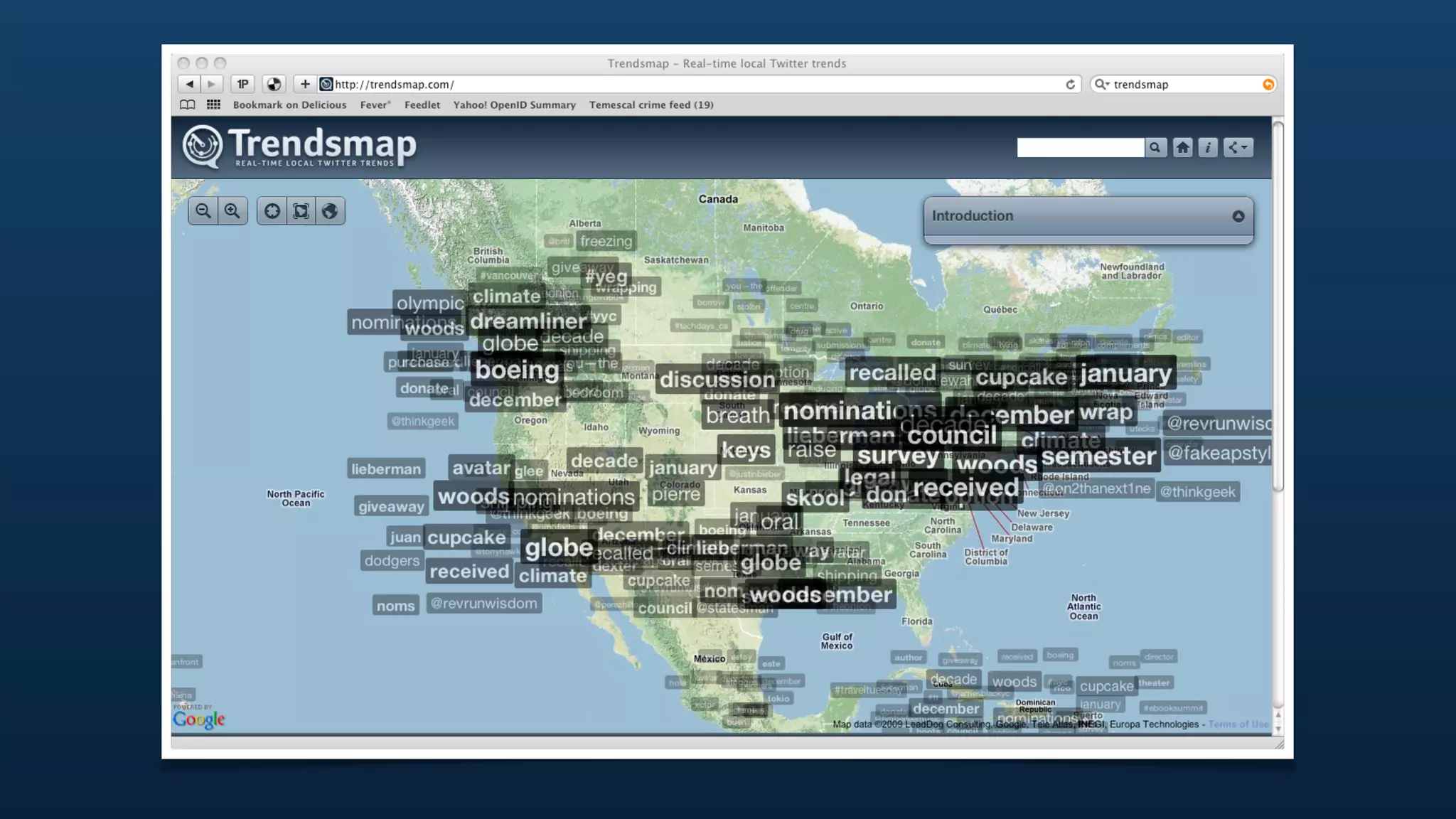
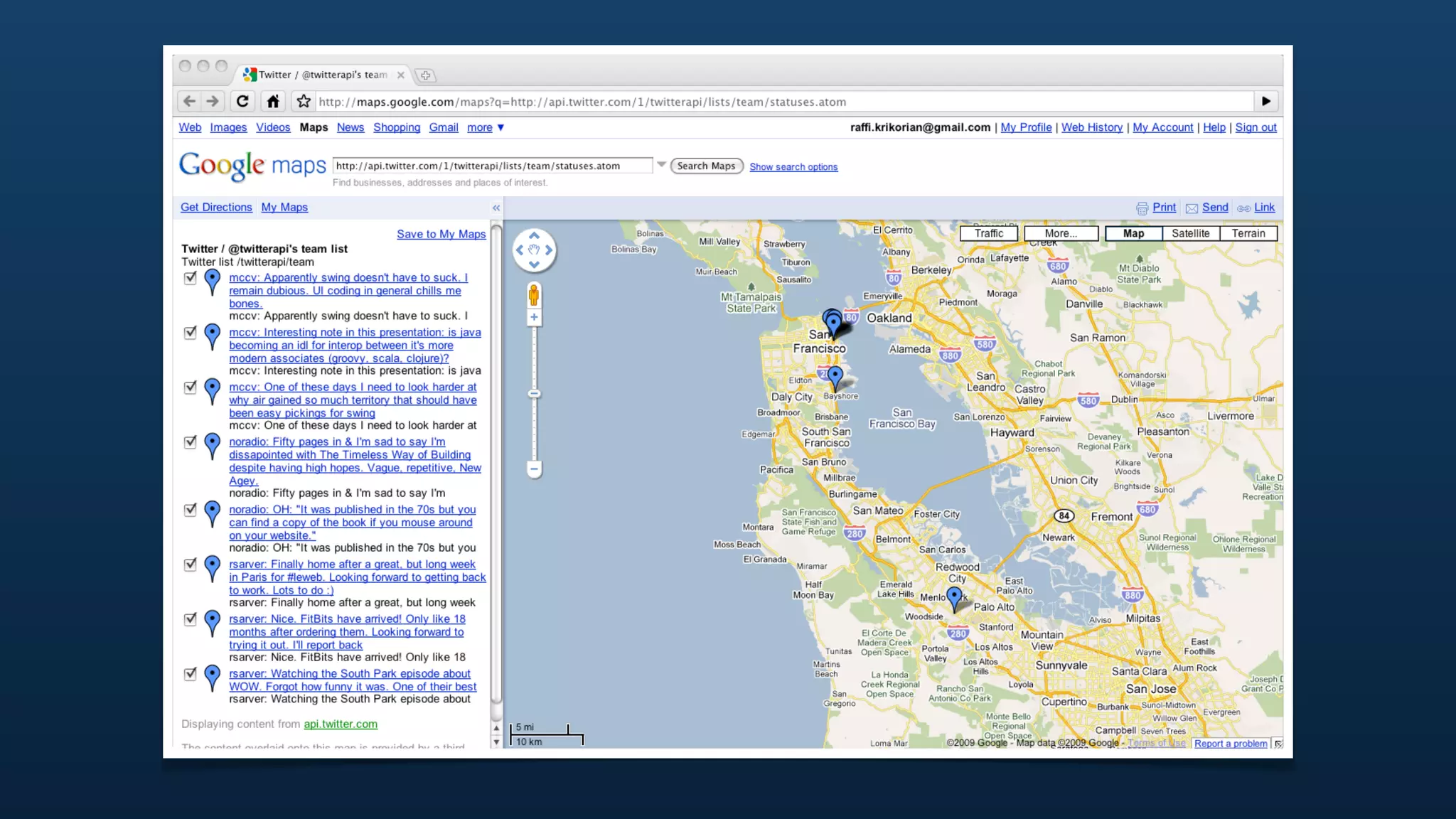
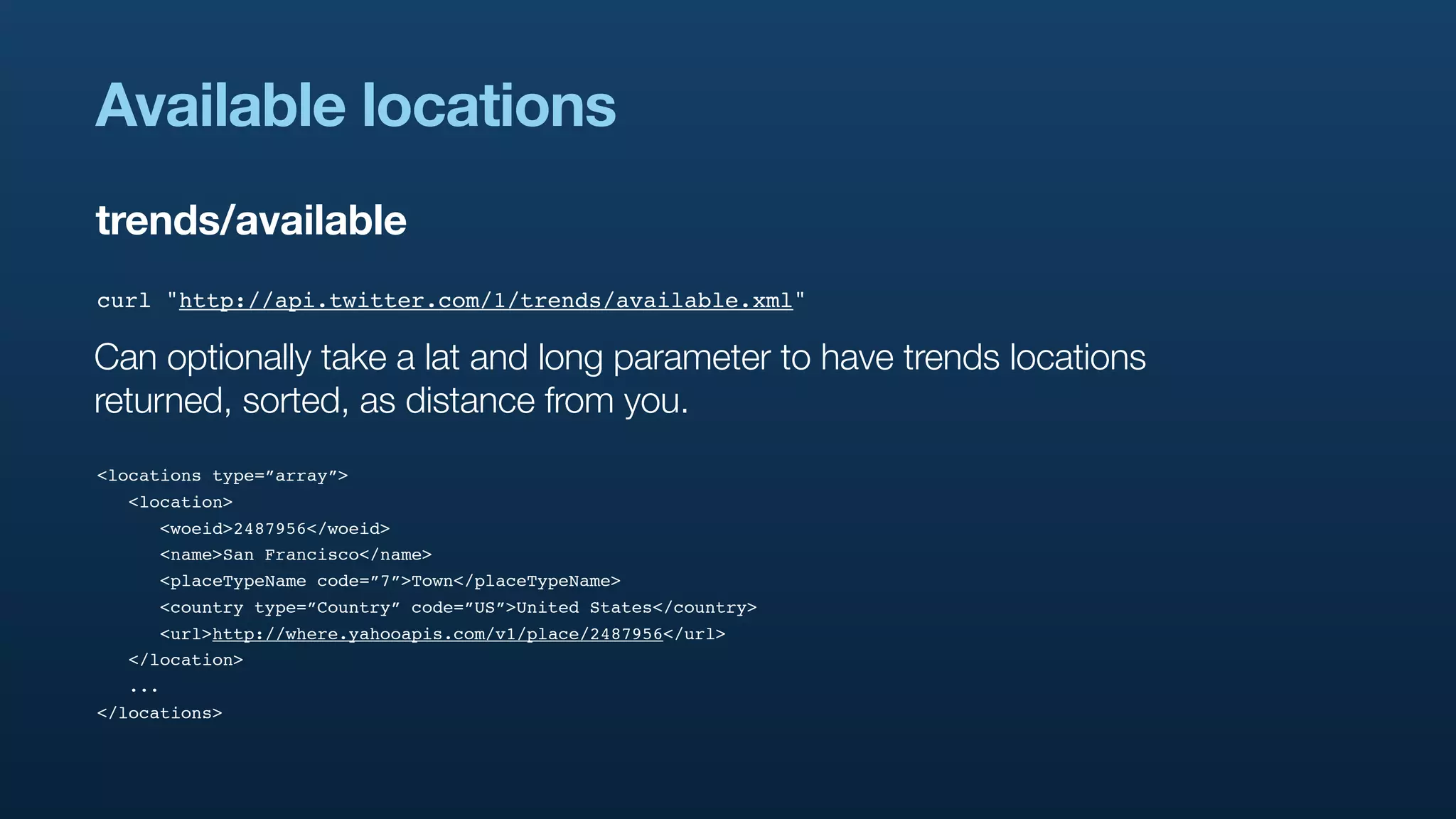
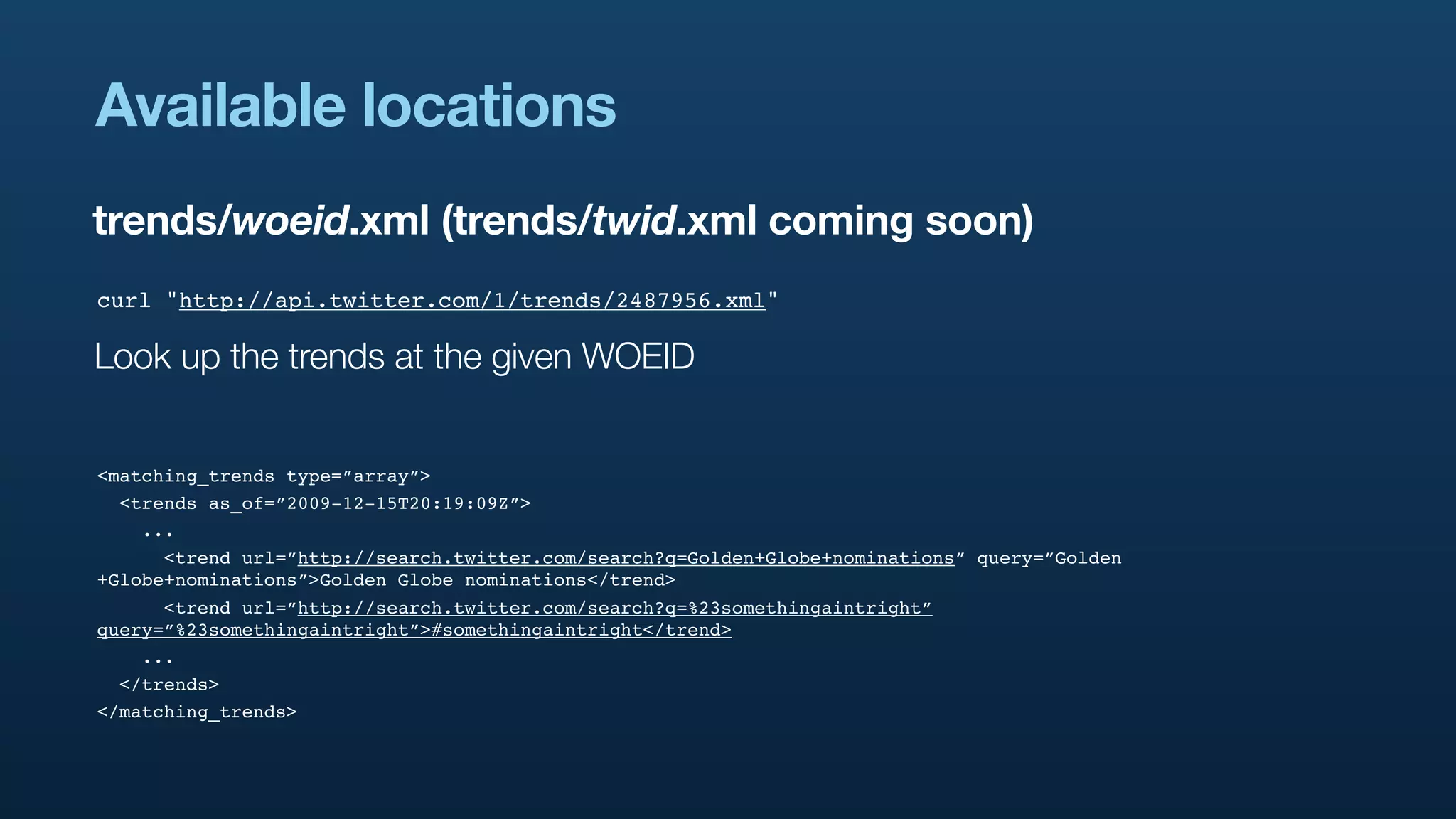
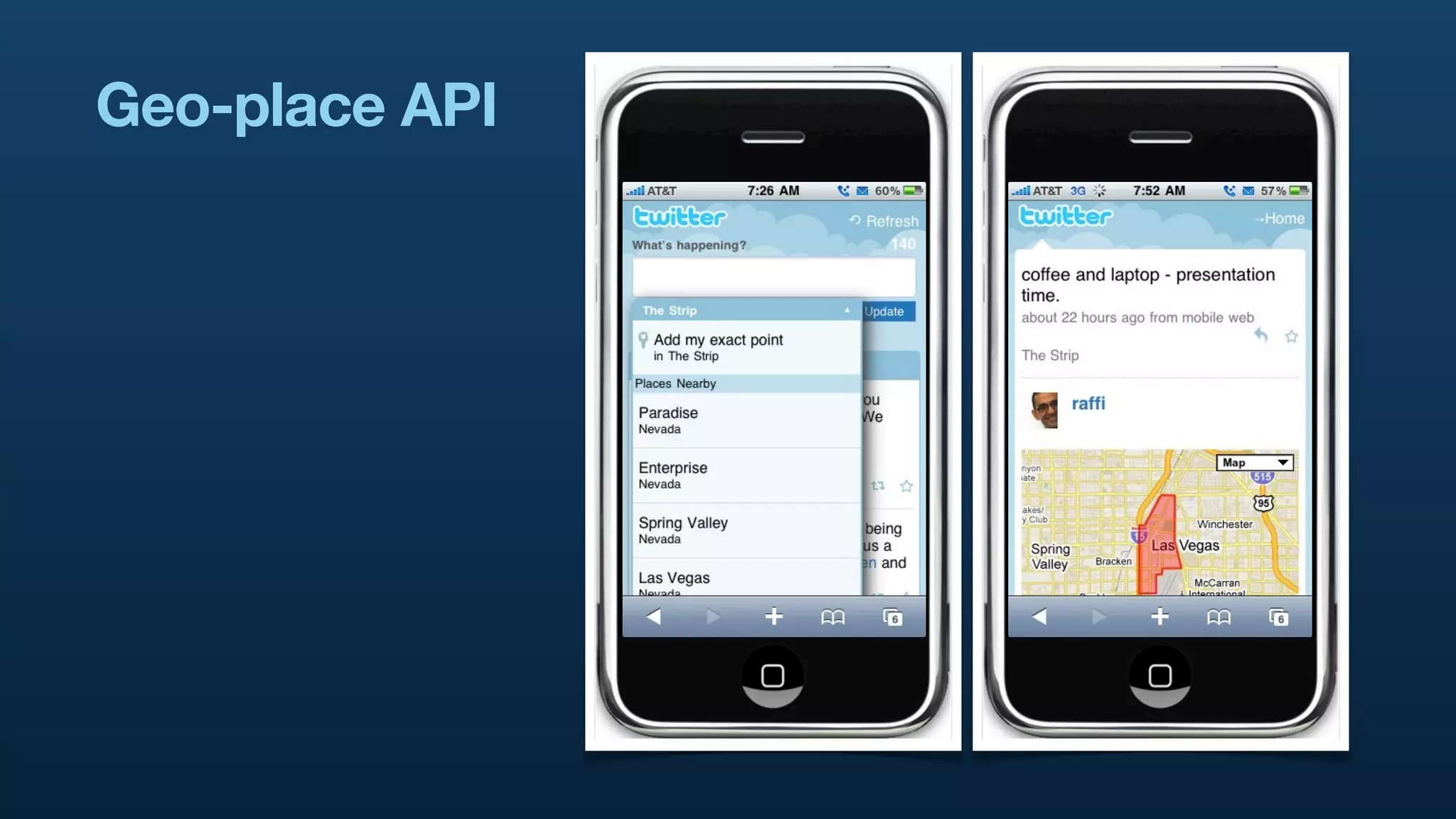
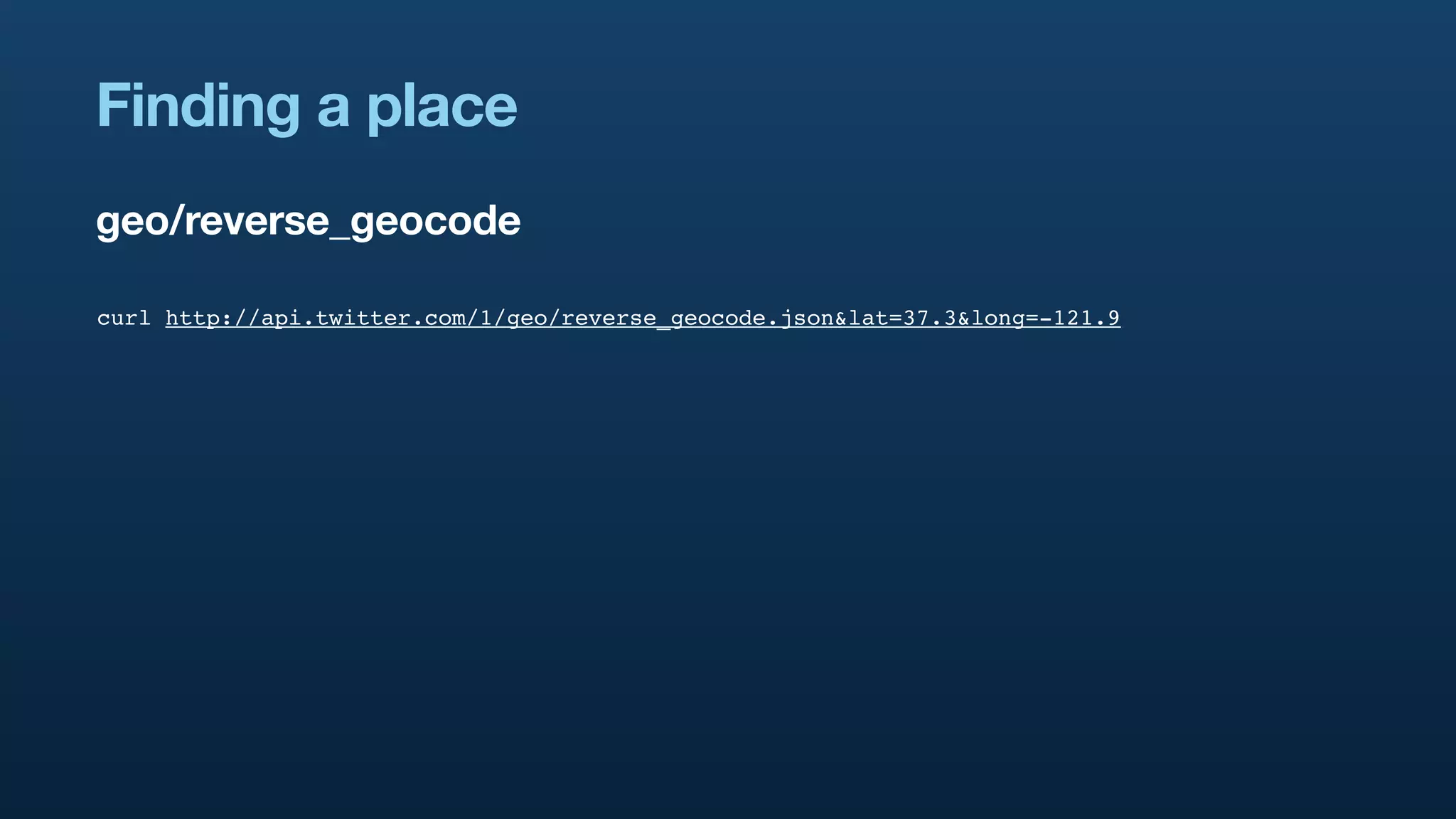
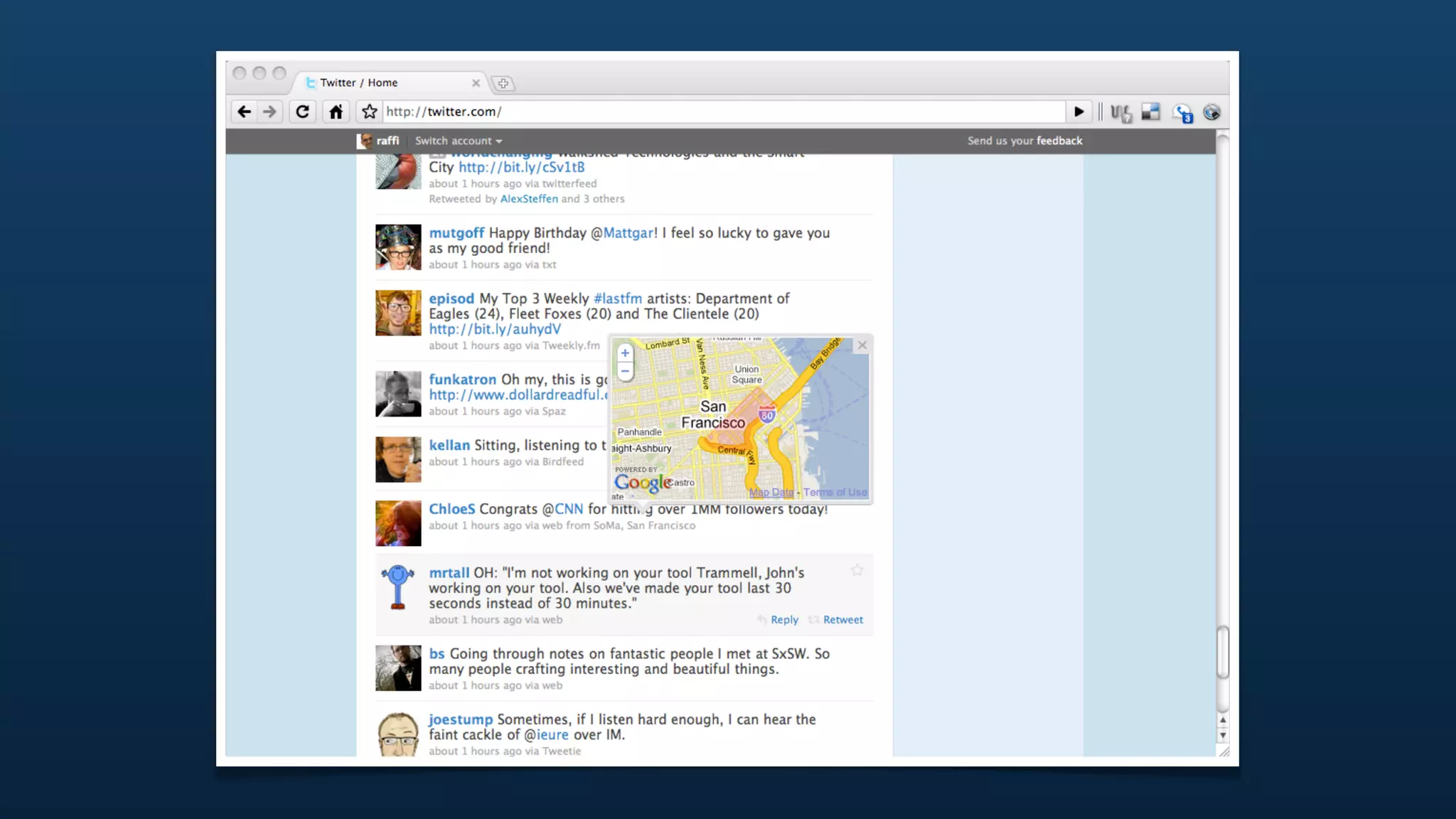
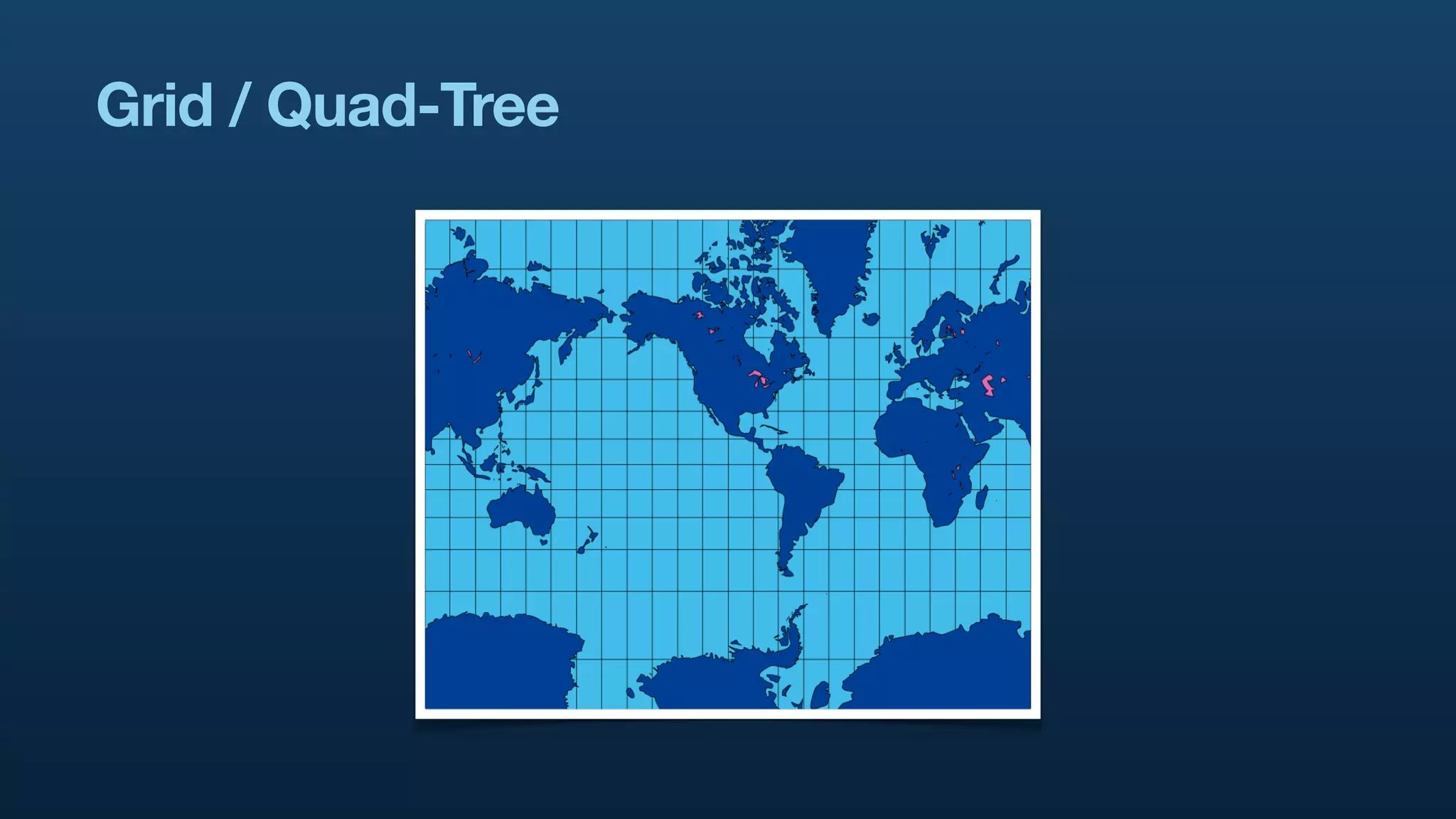
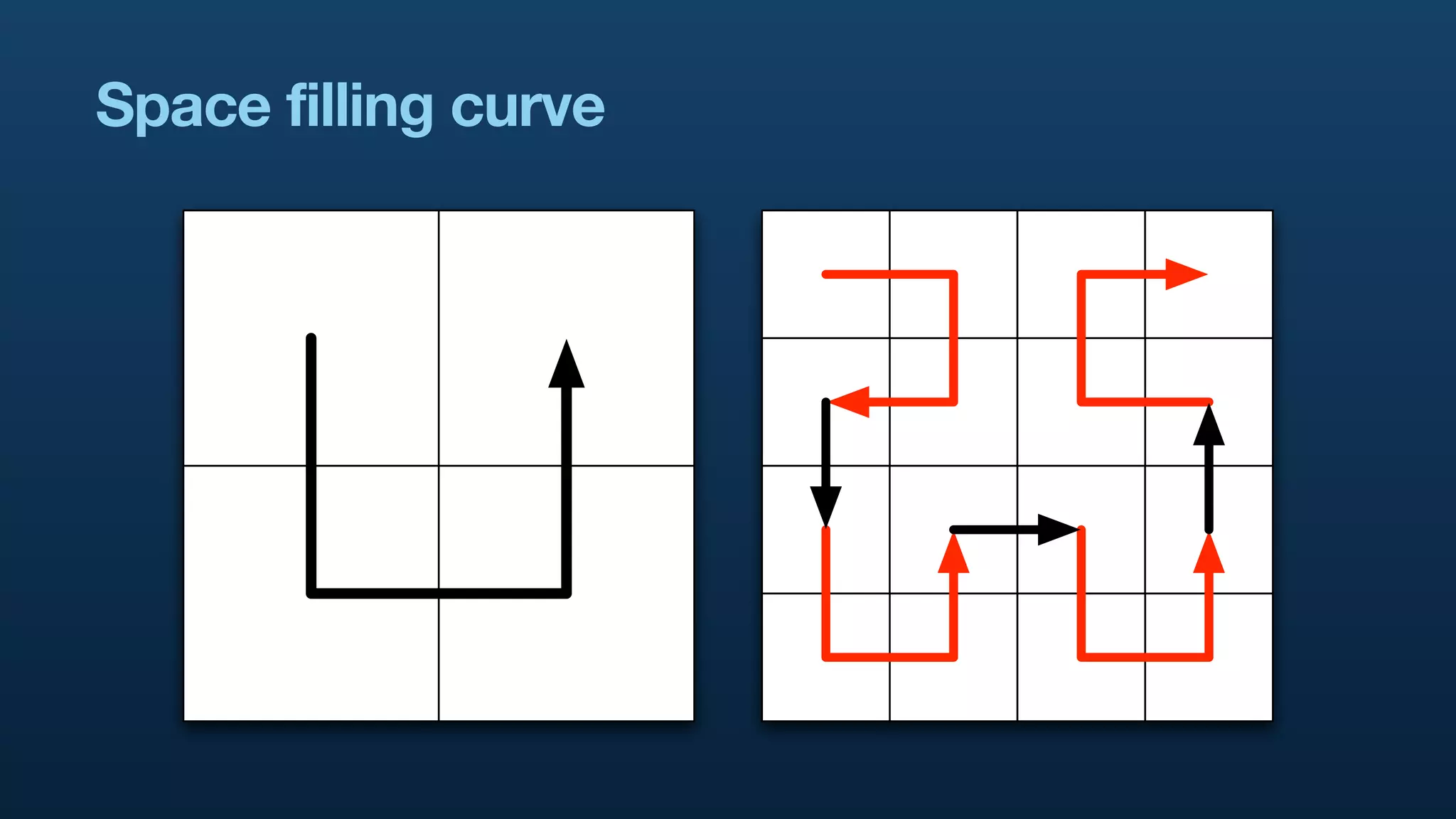
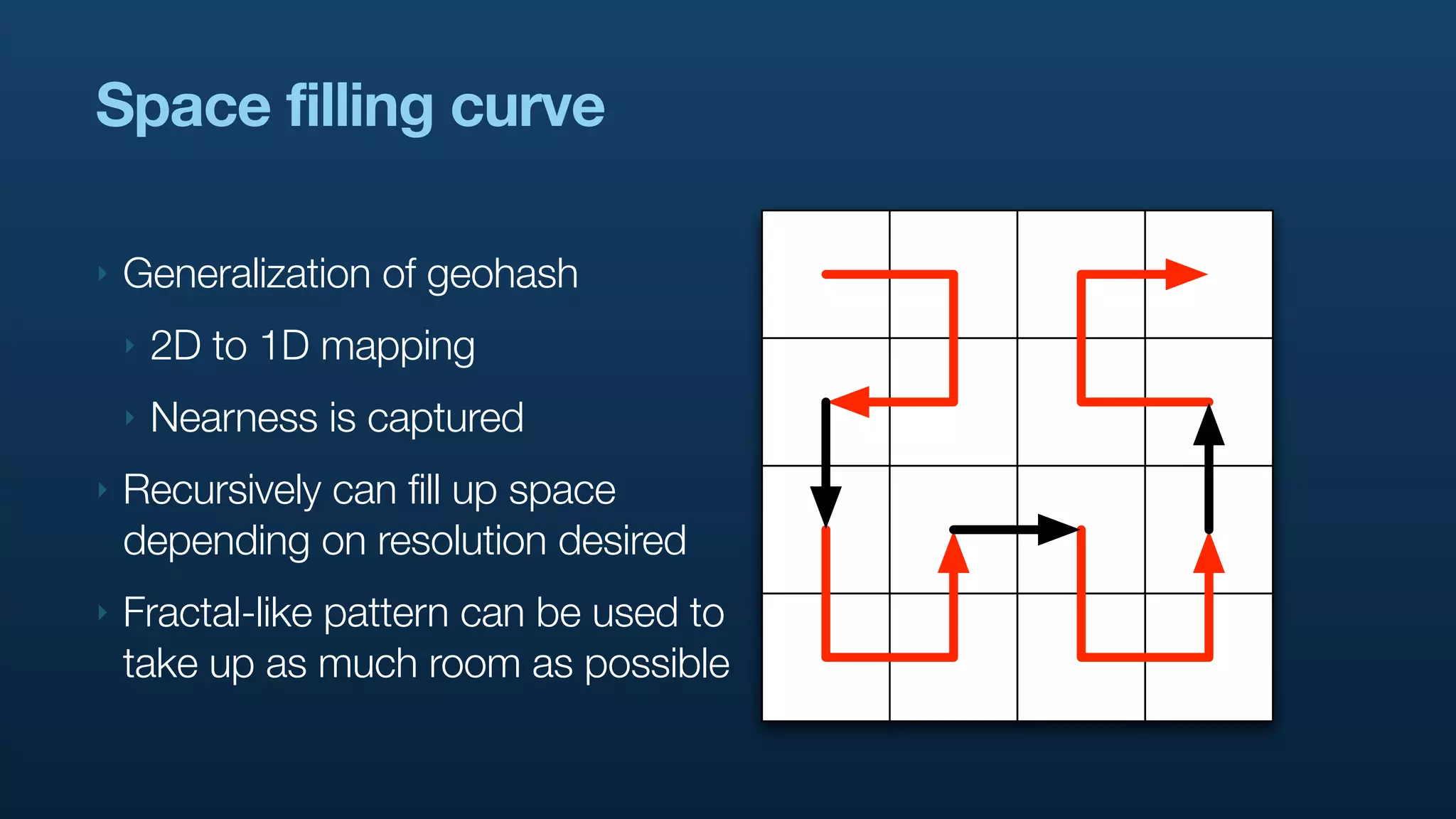
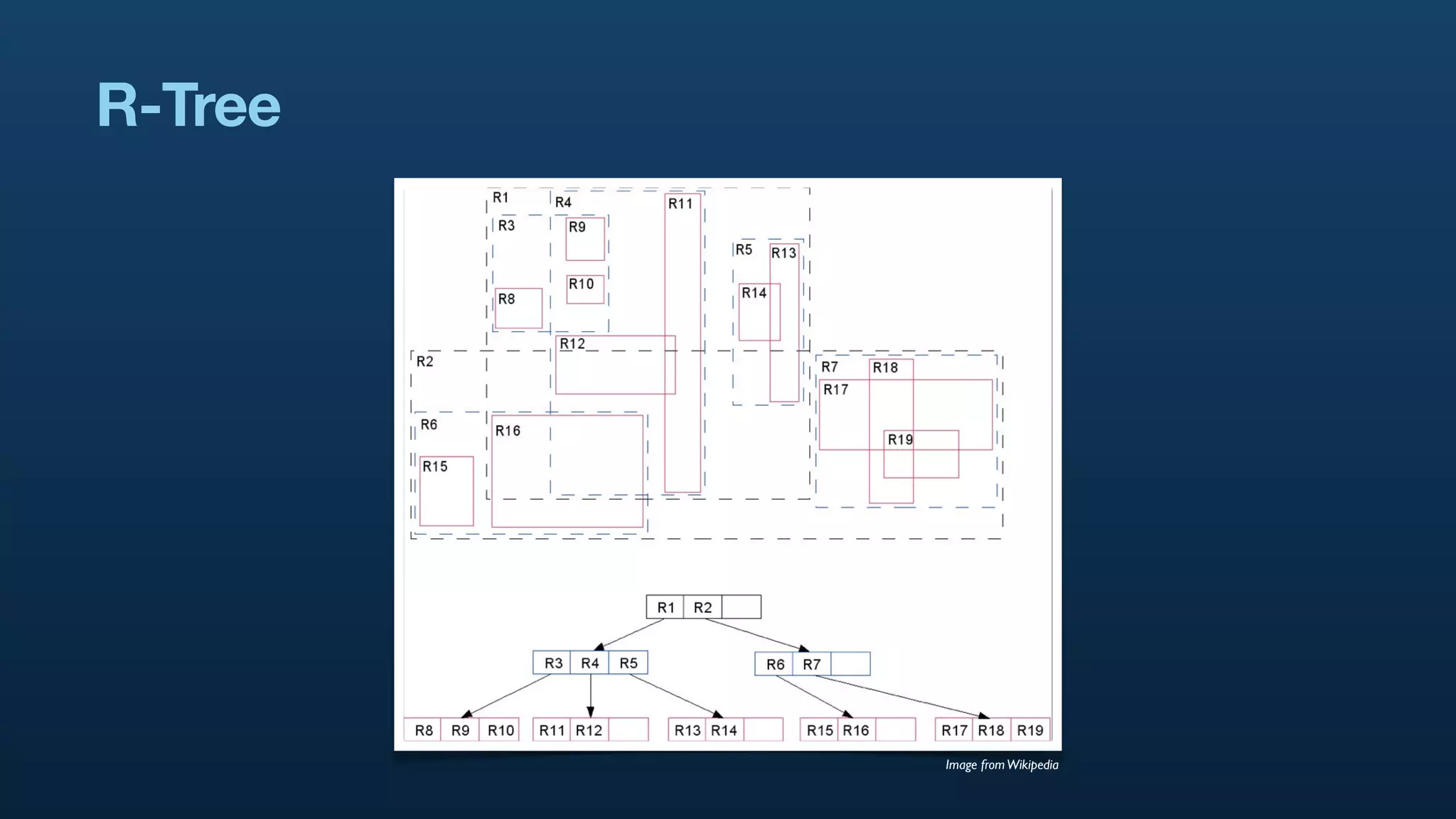
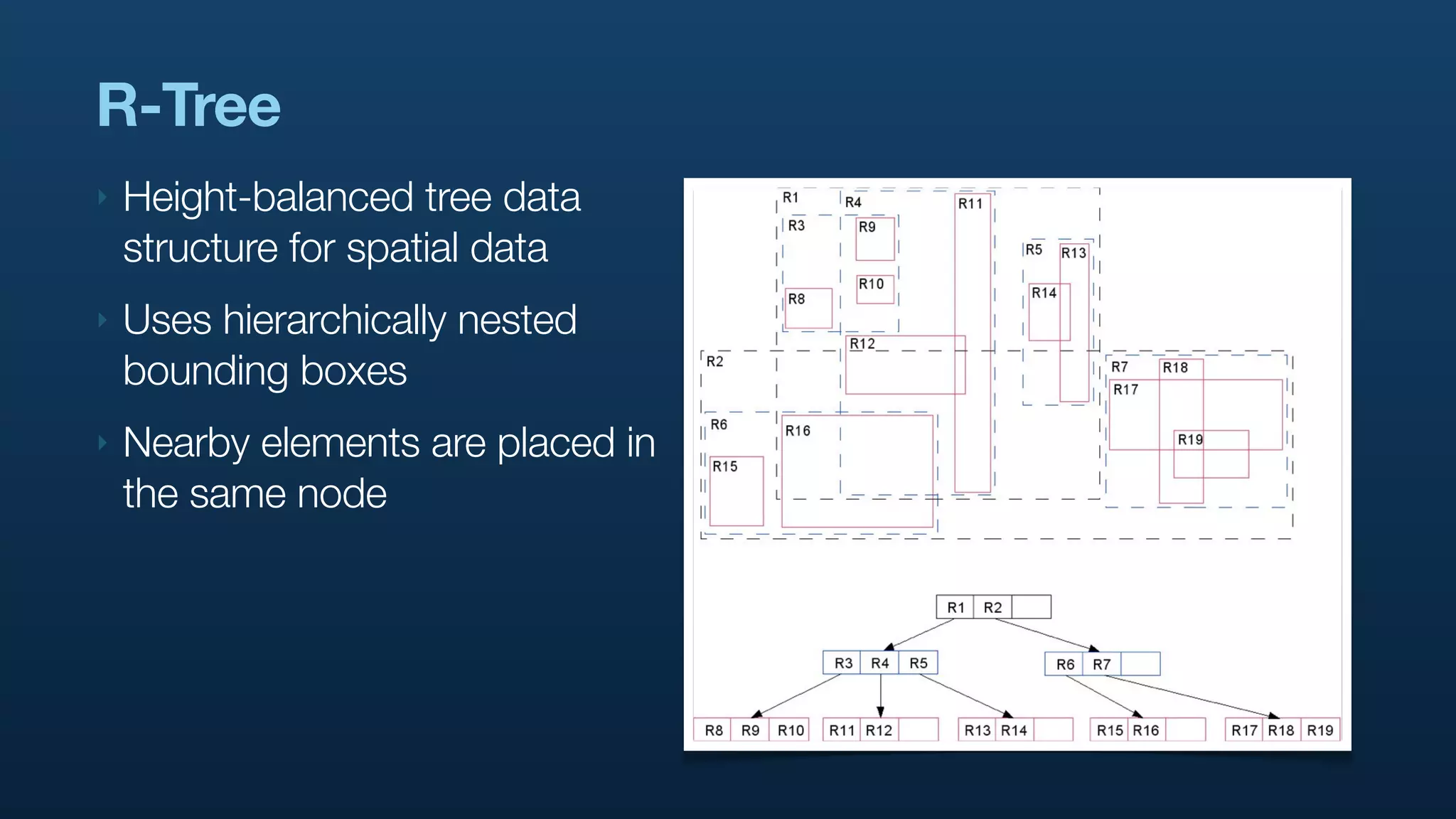
The document discusses Twitter's geo APIs and their integration of geolocation features into tweets, allowing users to talk about places. It covers infrastructure, methods for geotagging, and the complexities of spatial databases and querying for location-based data. Additionally, it addresses trending topics based on geographical relevance, reverse geocoding, and streaming real-time geo data.




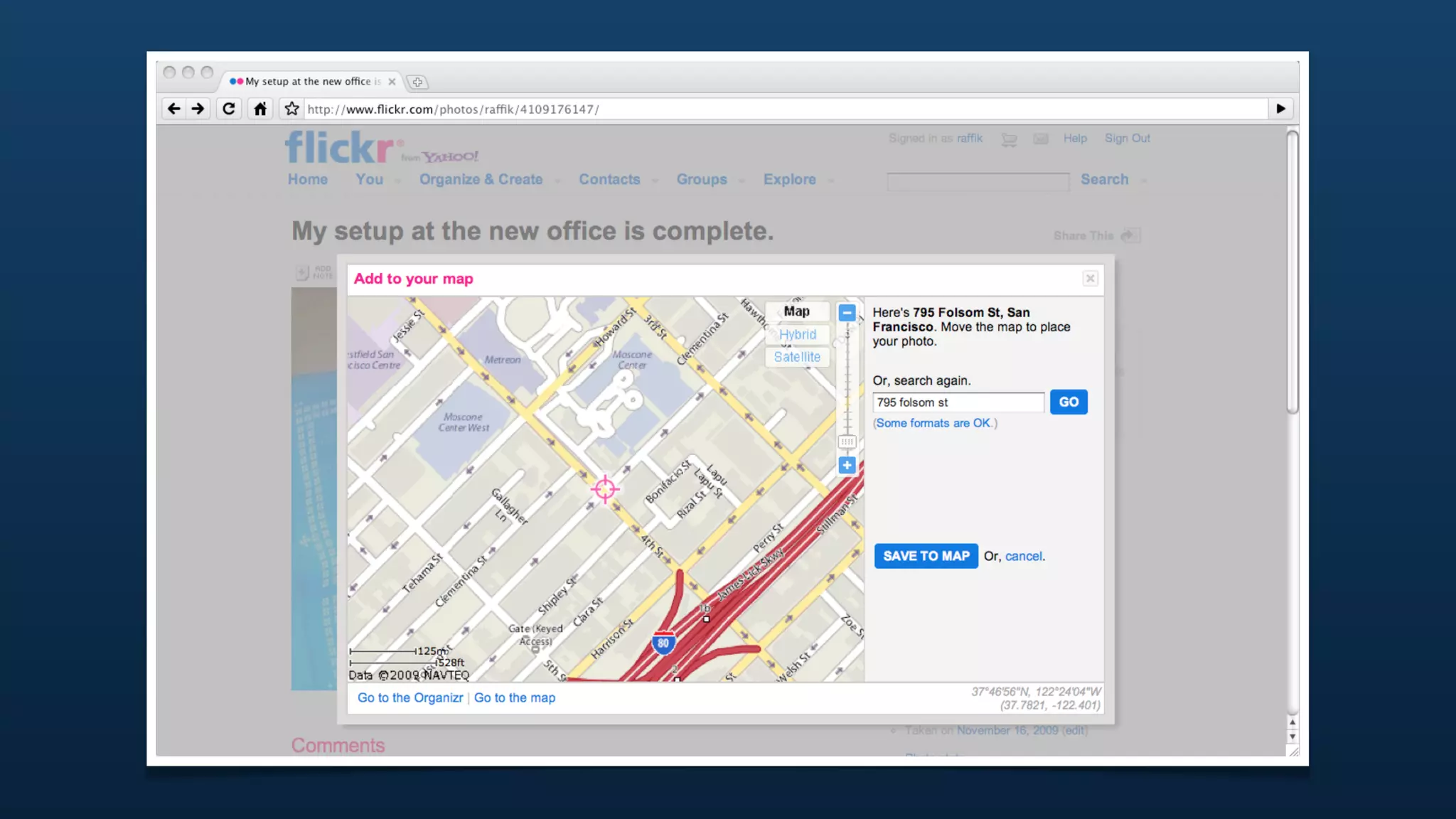
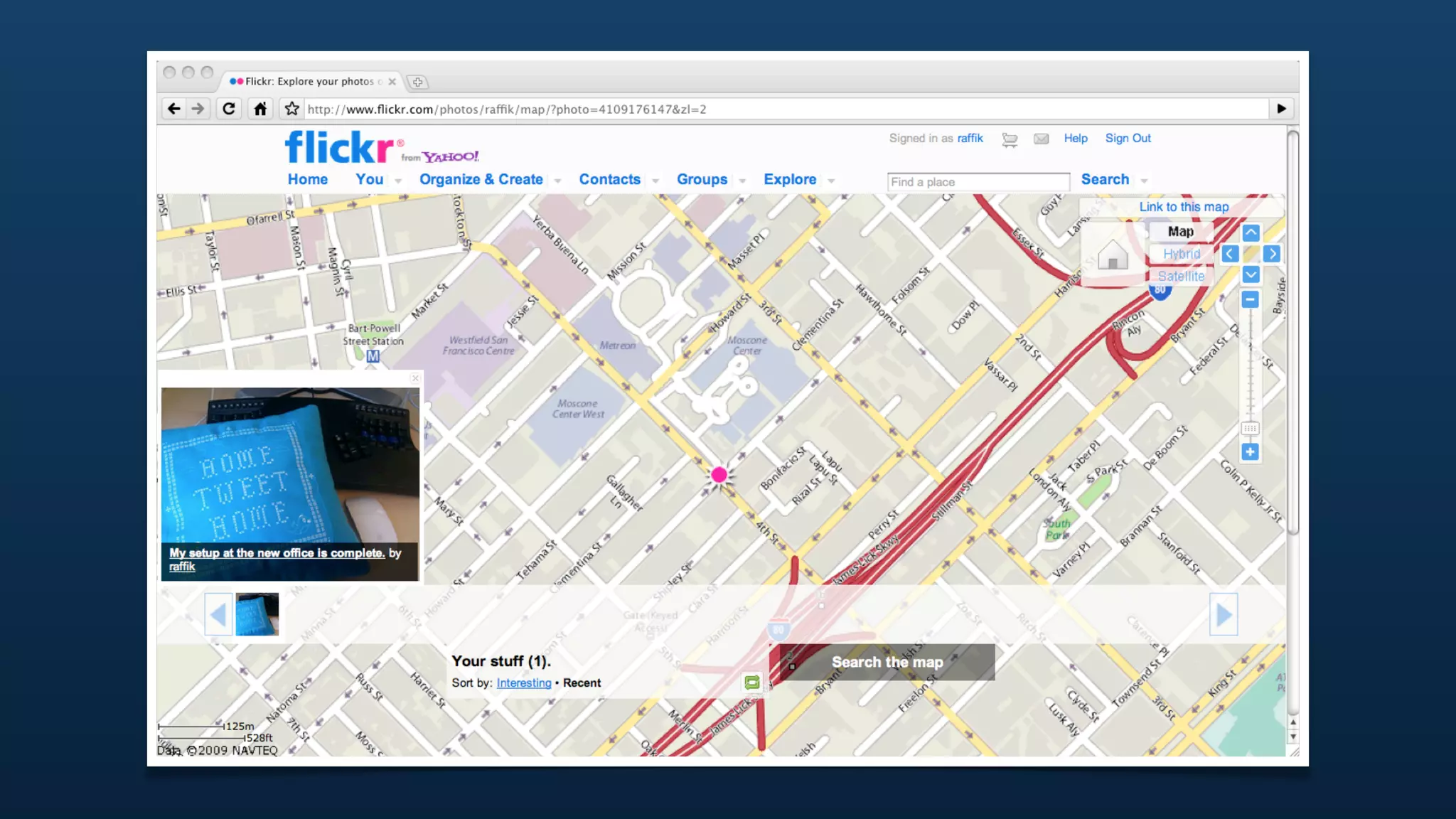


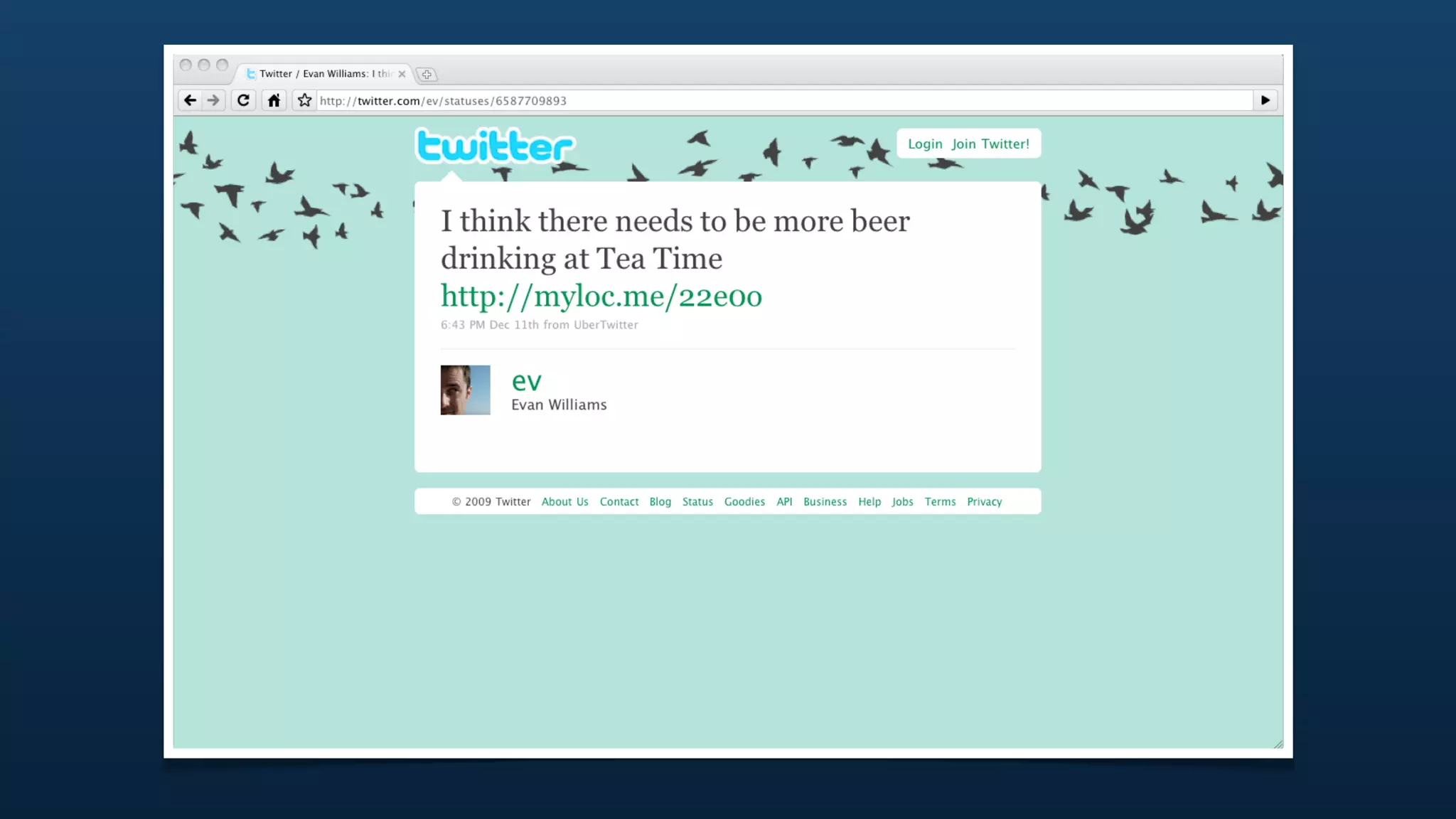
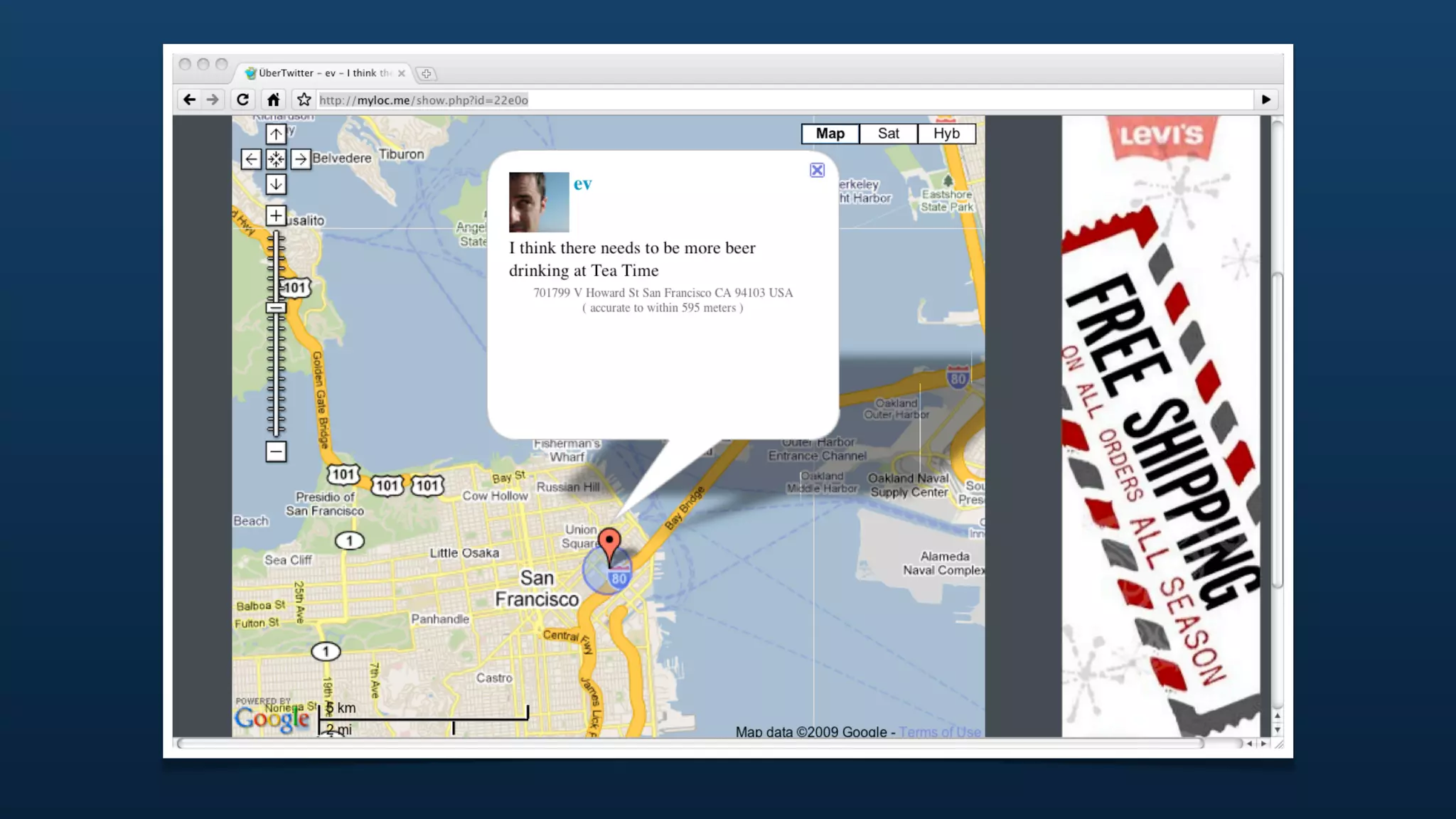






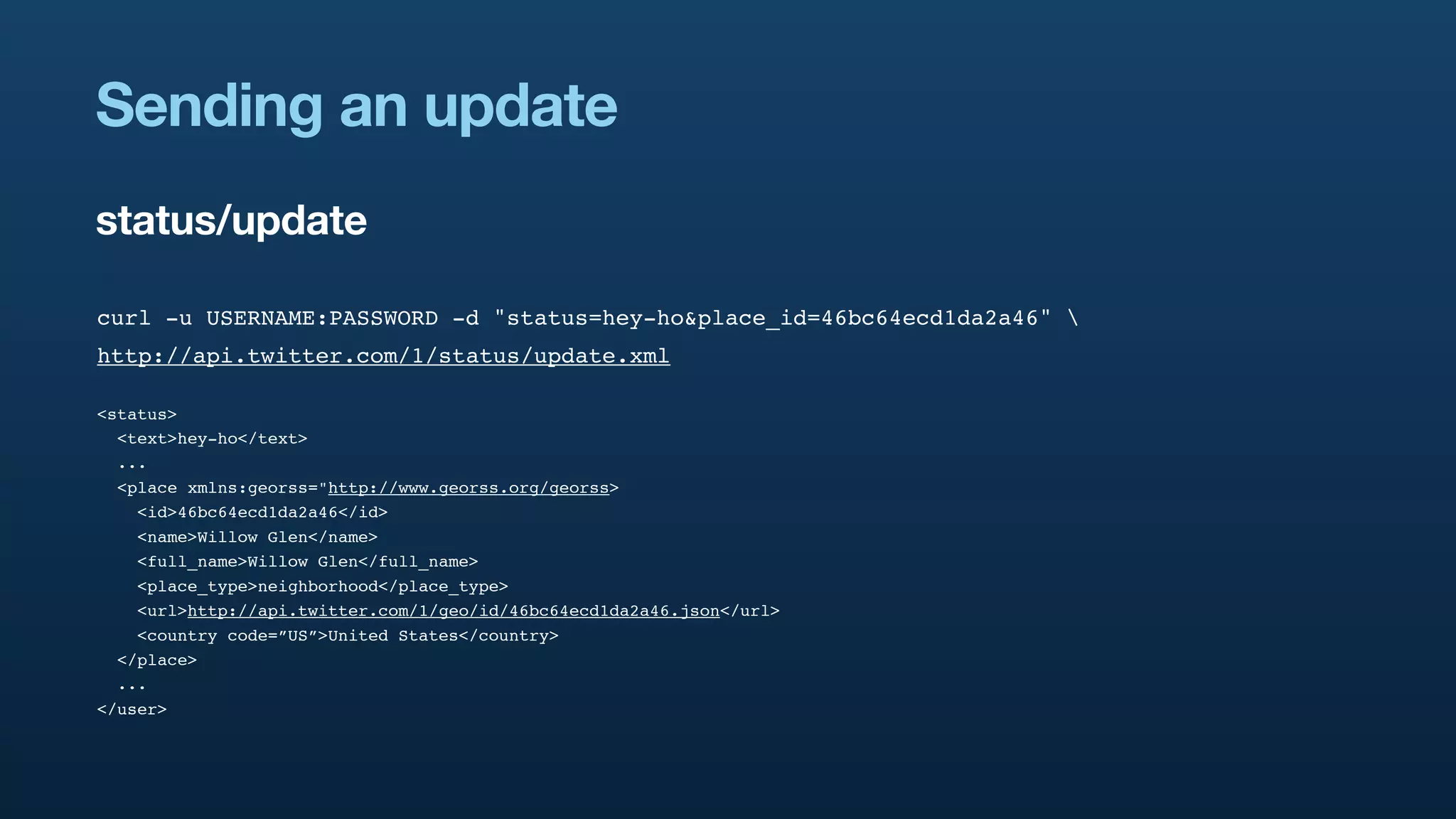
![{
"result": {
"places": [
{
"place_type":"neighborhood",
"country_code":"US",
"contained_within": [...]
"full_name":"Willow Glen",
"bounding_box": {
"type":"Polygon",
"coordinates": [[ Put some graphic to
explain what goes in the
[-121.92481908, 37.275903], [-121.88083608, 37.275903],
contained_within
[-121.88083608, 37.31548203], [-121.92481908, 37.31548203]
]]
},
"name":"Willow Glen",
"id":"46bc64ecd1da2a46",
"url":"http://api.twitter.com/1/geo/id/46bc64ecd1da2a46.json",
"country":""
},
...
]
}
}](https://image.slidesharecdn.com/real-time-geostreams-100330160937-phpapp01/75/Handling-Real-time-Geostreams-34-2048.jpg)














![GeoRSS / GeoJSON
‣ http://www.georss.org/ and http://geojson.org/
‣ <georss:point>37.3 -121.9</georss:point>
‣ {
“type”:”Point”,
“coordinates”:[-121.9, 37.3]
}](https://image.slidesharecdn.com/real-time-geostreams-100330160937-phpapp01/75/Handling-Real-time-Geostreams-56-2048.jpg)