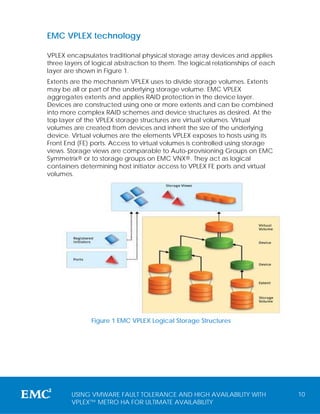
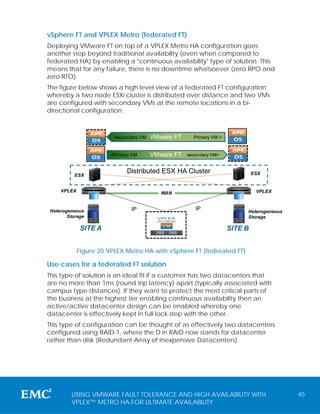
This white paper discusses the implementation of EMC VPLEX Metro technology in conjunction with VMware High Availability (HA) and Fault Tolerance (FT) to enhance continuous availability solutions across data centers. It explores design considerations, operational best practices, and the concept of 'federated availability' that combines the benefits of HA and FT to provide robust data protection and minimize downtime. The audience includes technology architects and storage administrators familiar with EMC and VMware solutions, aiming to implement advanced availability strategies over distance.