Downloaded 19 times













![@wheresrhys
Liberalisation
Matt Chadburn
http://matt.chadburn.co.uk/notes/teams-as-services.html
“[...] follow the mechanics of free-
market economy. Teams are allowed
and encouraged to pick the best value
tools for the job at hand”](https://image.slidesharecdn.com/afieldguidetothefinancialtimesok-190328094915/75/A-field-guide-to-the-Financial-Times-Rhys-Evans-Financial-Times-17-2048.jpg)
























![@wheresrhys
GraphQL to the rescue
“GraphQL is a query language for
APIs [...] gives clients the power to
ask for exactly what they need [...]
not just the properties of one
resource but also smoothly follows
references between them”](https://image.slidesharecdn.com/afieldguidetothefinancialtimesok-190328094915/75/A-field-guide-to-the-Financial-Times-Rhys-Evans-Financial-Times-43-2048.jpg)




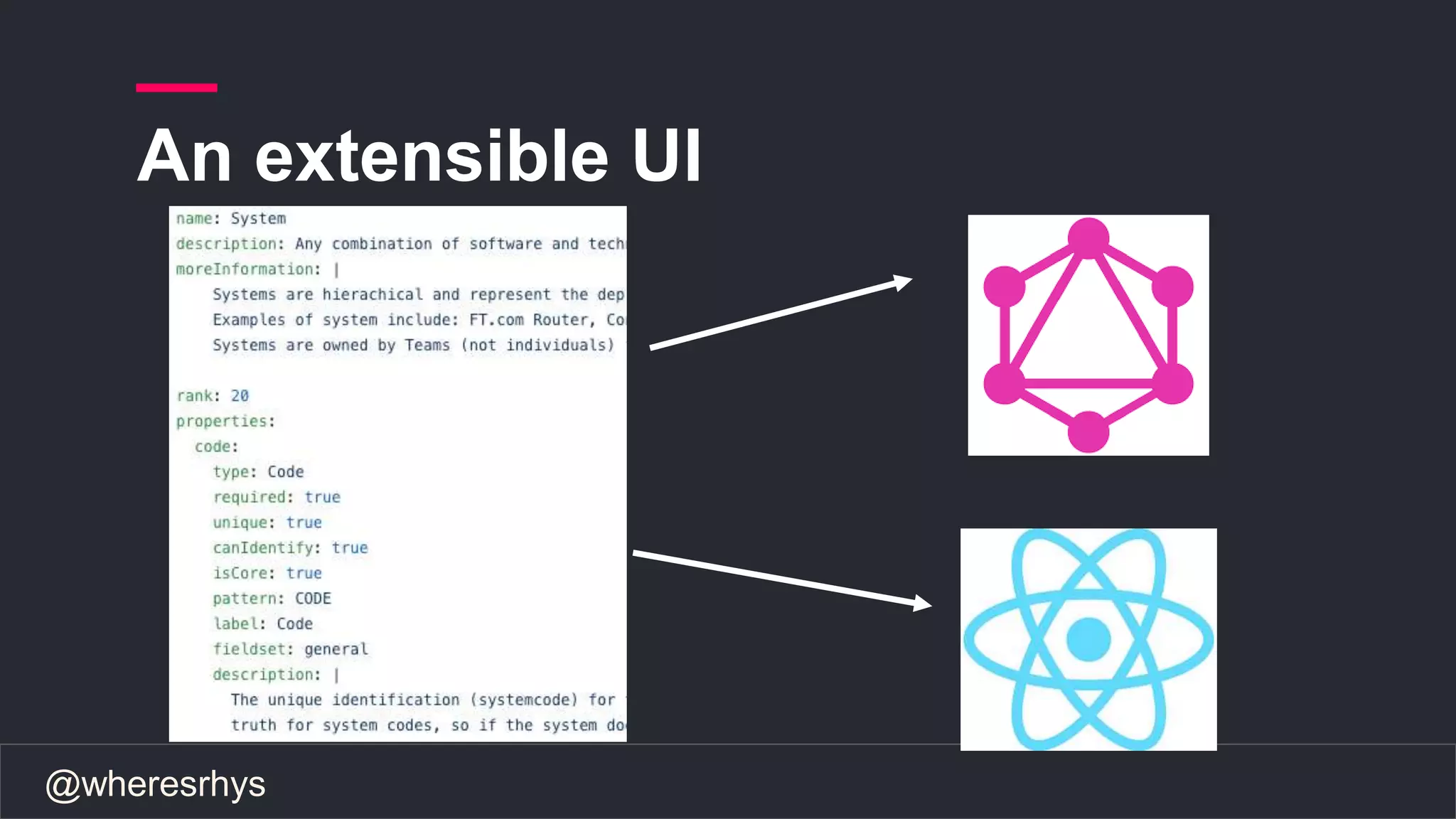
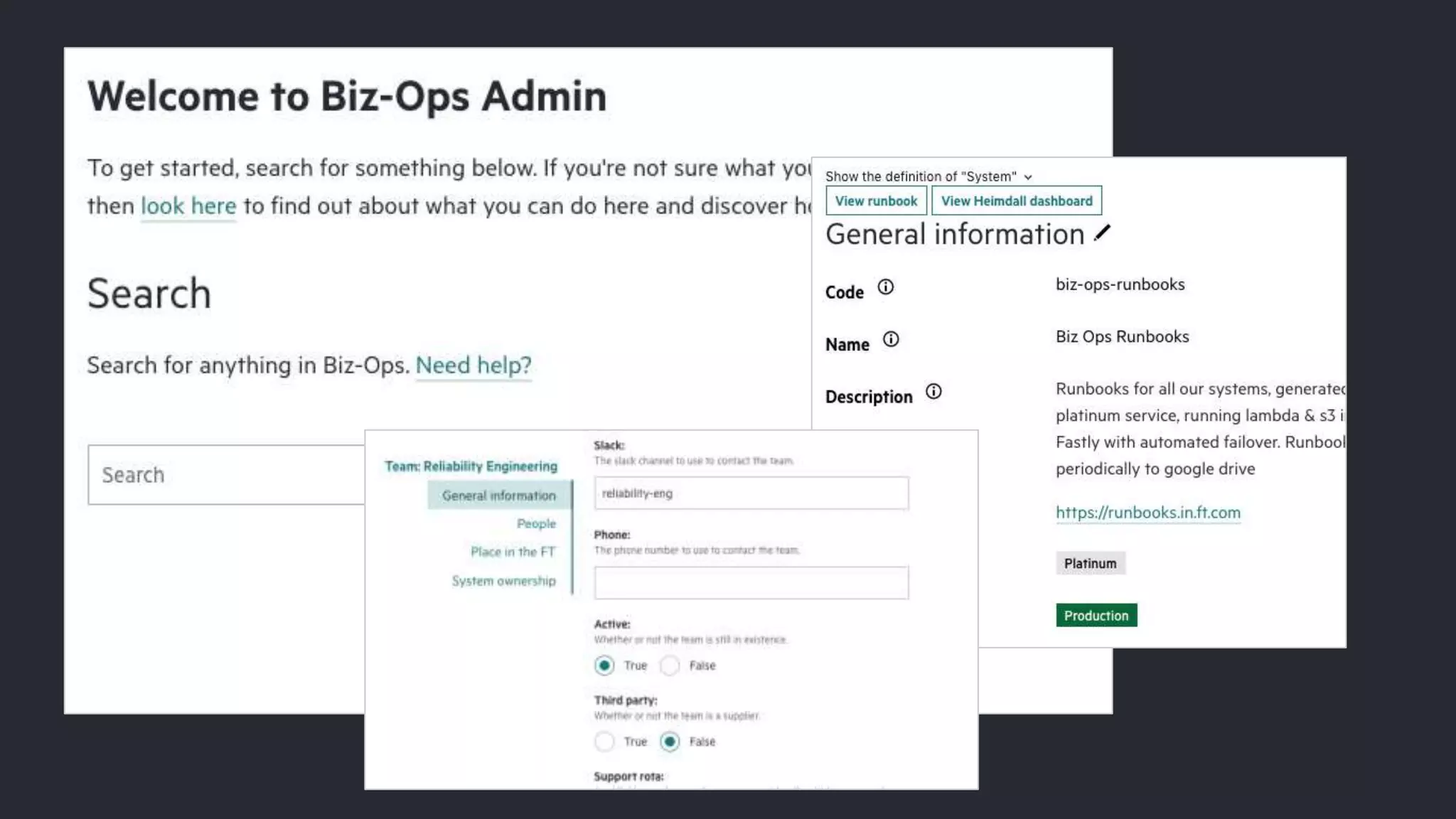
























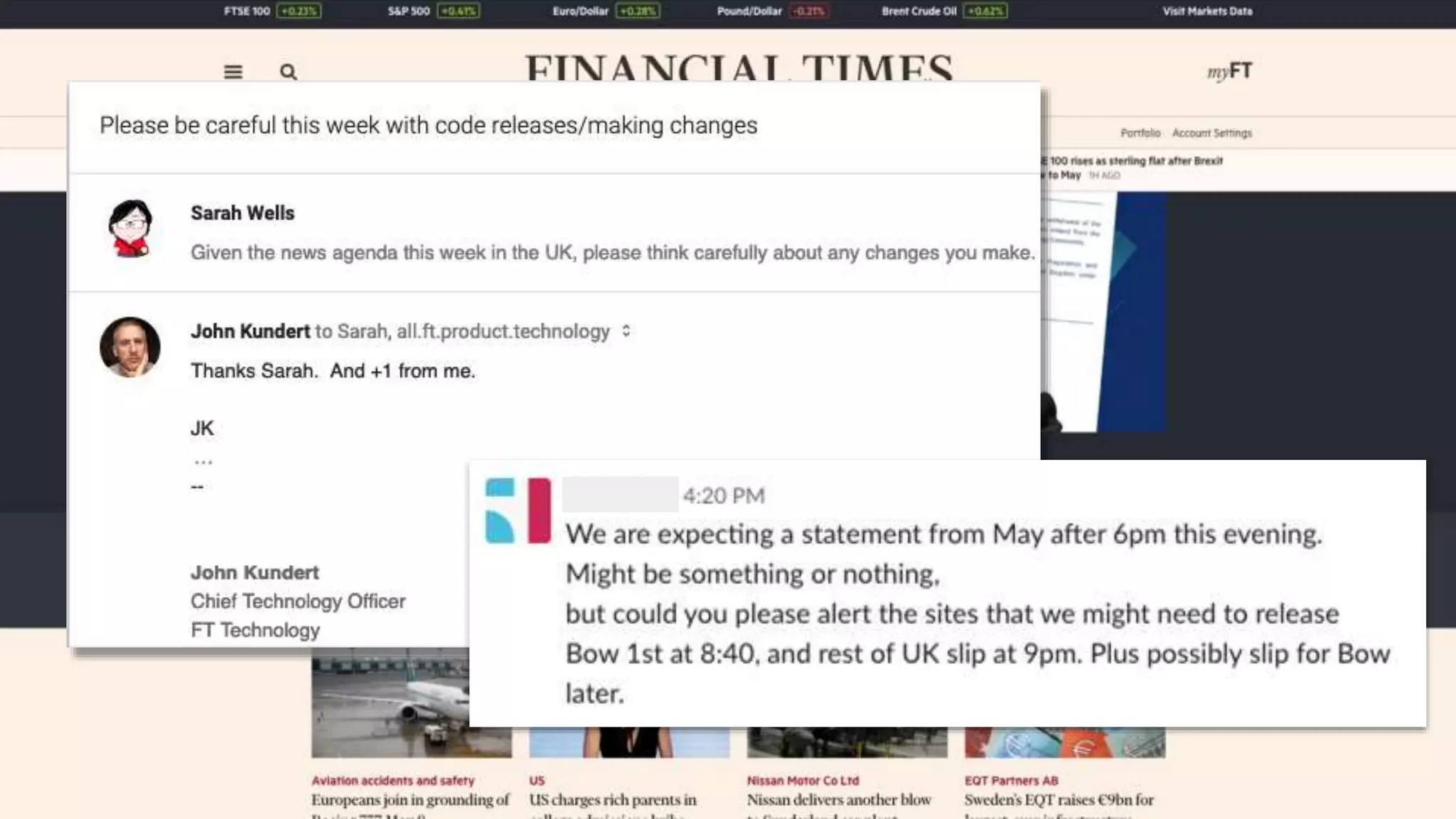
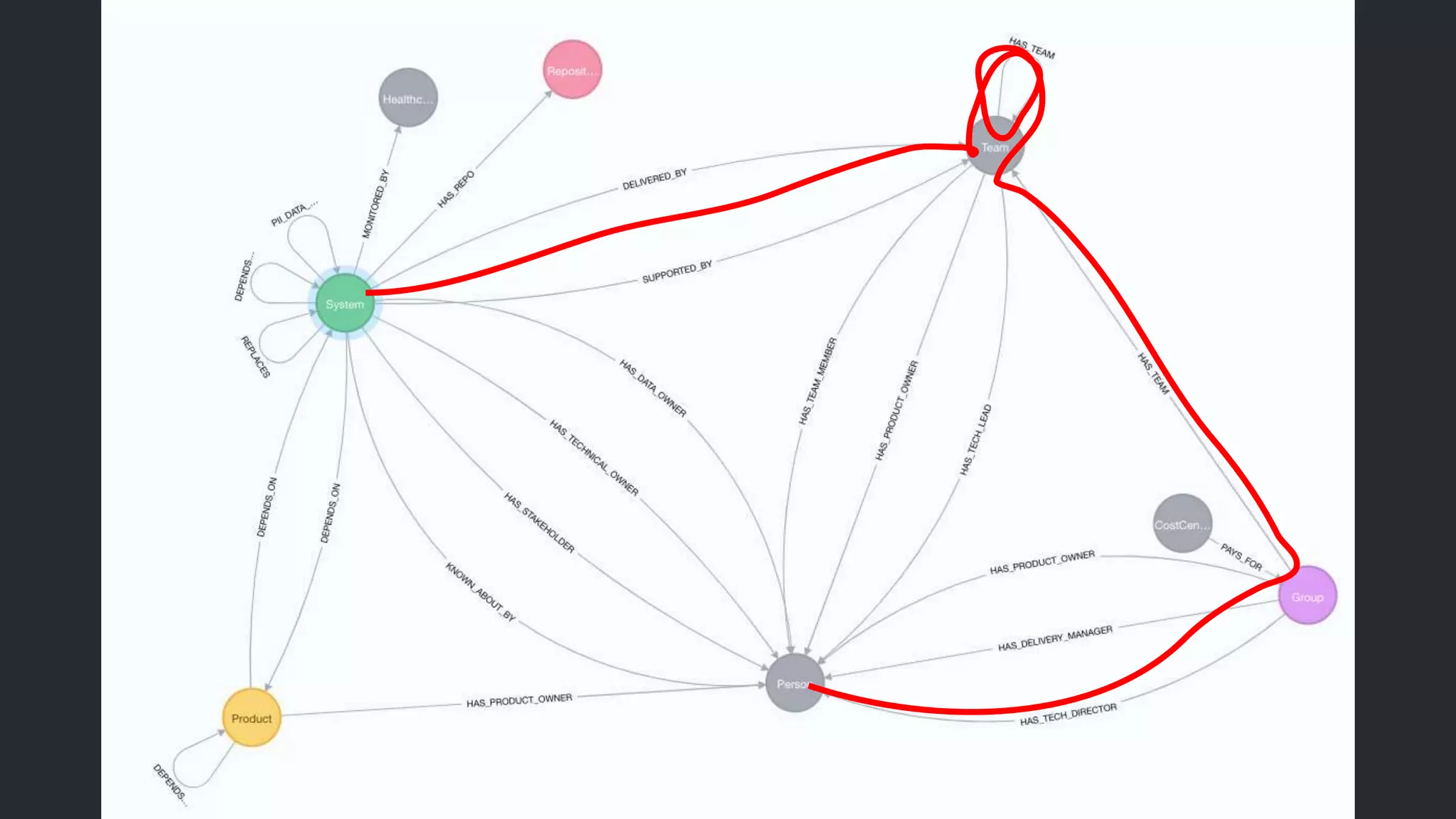
The document discusses the need for a field guide at the Financial Times to manage their expanding technology landscape, particularly focusing on organizing information about tech ownership and status using Neo4j and GraphQL. It highlights challenges faced with previous systems that lacked flexibility and connectivity, emphasizing the importance of modern tools for effective operations and data management. The guide aims to improve reliability, automate processes, and enhance user experience in navigating complex tech relationships.






































![Resilience: the key requirement of a [big] [data] architecture - StampedeCon...](https://cdn.slidesharecdn.com/ss_thumbnails/resiliencethekeyrequirementofabigdataarchitecture-stampedecon2015-150717135240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)















































