Downloaded 30 times




![Enabling
Heterogeneous
Computing in
Java with
Graal
Juan Fumero,
Michel
Steuwer,
Christophe
Dubach
Introduction
API
Runtime Code
Generation
Data
Management
Results
Conclusion
Example in OpenCL
1 // create host buffers
2 i n t ∗A, . . . .
3 //Initialization
4 . . .
5 // platform
6 c l u i n t numPlatforms = 0;
7 c l p l a t f o r m i d ∗ p l a t f o r m s ;
8 s t a t u s = clGetPlatf ormIDs (0 , NULL, &numPlatforms ) ;
9 p l a t f o r m s = ( c l p l a t f o r m i d ∗) malloc ( numPlatforms∗ s i z e o f ( c l p l a t f o r m i d ) ) ;
10 s t a t u s = c lGetPlatform IDs ( numPlatforms , platforms , NULL) ;
11 c l u i n t numDevices = 0;
12 c l d e v i c e i d ∗ d e v i c e s ;
13 s t a t u s = clGetDeviceIDs ( p l a t f o r m s [ 0 ] , CL DEVICE TYPE ALL , 0 , NULL, &
numDevices ) ;
14 // Allocate space for each device
15 d e v i c e s = ( c l d e v i c e i d ∗) malloc ( numDevices∗ s i z e o f ( c l d e v i c e i d ) ) ;
16 // Fill in devices
17 s t a t u s = clGetDeviceIDs ( p l a t f o r m s [ 0 ] , CL DEVICE TYPE ALL , numDevices ,
devices , NULL) ;
18 c l c o n t e x t context ;
19 context = c l C r e a t e C o n t e x t (NULL, numDevices , devices , NULL, NULL, &s t a t u s ) ;
20 cl command queue cmdQ ;
21 cmdQ = clCreateCommandQueue ( context , d e v i c e s [ 0 ] , 0 , &s t a t u s ) ;
22 cl mem d A , d B , d C ;
23 d A = c l C r e a t e B u f f e r ( context , CL MEM READ ONLY|CL MEM COPY HOST PTR,
d a t a s i z e , A, &s t a t u s ) ;
24 d B = c l C r e a t e B u f f e r ( context , CL MEM READ ONLY|CL MEM COPY HOST PTR,
d a t a s i z e , B, &s t a t u s ) ;
25 d C = c l C r e a t e B u f f e r ( context , CL MEM WRITE ONLY, d a t a s i z e , NULL, &s t a t u s ) ;
26 . . .
27 // Check errors
28 . . .
5 / 26](https://image.slidesharecdn.com/gpusgraal-150708180913-lva1-app6892/85/Gpus-graal-5-320.jpg)
![Enabling
Heterogeneous
Computing in
Java with
Graal
Juan Fumero,
Michel
Steuwer,
Christophe
Dubach
Introduction
API
Runtime Code
Generation
Data
Management
Results
Conclusion
Example in OpenCL
1 const char ∗ s o u r c e F i l e = ” k e r n e l . c l ” ;
2 source = r e a d s o u r c e ( s o u r c e F i l e ) ;
3 program = clCreateProgramWithSource ( context , 1 , ( const char ∗∗)&source , NULL,
&s t a t u s ) ;
4 c l i n t b u i l d E r r ;
5 b u i l d E r r = clBuildProgram ( program , numDevices , devices , NULL, NULL, NULL) ;
6 // Create a kernel
7 k e r n e l = c l C r e a t e K e r n e l ( program , ” vecadd ” , &s t a t u s ) ;
8
9 s t a t u s = c l S e t K e r n e l A r g ( kernel , 0 , s i z e o f ( cl mem ) , &d A ) ;
10 s t a t u s |= c l S e t K e r n e l A r g ( kernel , 1 , s i z e o f ( cl mem ) , &d B ) ;
11 s t a t u s |= c l S e t K e r n e l A r g ( kernel , 2 , s i z e o f ( cl mem ) , &d C ) ;
12
13 s i z e t globalWorkSize [ 1 ] = { ELEMENTS};
14 s i z e t l o c a l i t e m s i z e [ 1 ] = {5};
15
16 clEnqueueNDRangeKernel (cmdQ, kernel , 1 , NULL, globalWorkSize , NULL, 0 , NULL,
NULL) ;
17
18 clEnqueueReadBuffer (cmdQ, d C , CL TRUE , 0 , d a t a s i z e , C, 0 , NULL, NULL) ;
19
20 // Free memory
6 / 26](https://image.slidesharecdn.com/gpusgraal-150708180913-lva1-app6892/85/Gpus-graal-6-320.jpg)
![Enabling
Heterogeneous
Computing in
Java with
Graal
Juan Fumero,
Michel
Steuwer,
Christophe
Dubach
Introduction
API
Runtime Code
Generation
Data
Management
Results
Conclusion
OpenCL example
1 k e r n e l void
vecadd (
2 g l o b a l i n t ∗a ,
3 g l o b a l i n t ∗b ,
4 g l o b a l i n t ∗c ) {
5
6 i n t i d x =
7 g e t g l o b a l i d (0) ;
8 c [ i d x ] = a [ i d x ] ∗
b [ i d x ] ;
9 }
• Hello world App ˜ 250 lines of
code (including error
checking)
• Low-level and specific code
• Knowledge about target
architecture
• If GPU/accelerator changes,
tuning is required
7 / 26](https://image.slidesharecdn.com/gpusgraal-150708180913-lva1-app6892/85/Gpus-graal-7-320.jpg)



![Enabling
Heterogeneous
Computing in
Java with
Graal
Juan Fumero,
Michel
Steuwer,
Christophe
Dubach
Introduction
API
Runtime Code
Generation
Data
Management
Results
Conclusion
Example: Saxpy
1 // Computation function
2 ArrayFunc<Tuple2<Float , Float >, Float > mult = new
MapFunction<>(t −> 2.5 f ∗ t . 1 () + t . 2 () ) ;
3
4 // Prepare the input
5 Tuple2<Float , Float >[] i n p ut = new Tuple2 [ s i z e ] ;
6 f o r ( i n t i = 0; i < i np u t . l e n g t h ; ++i ) {
7 i n pu t [ i ] . 1 = ( f l o a t ) ( i ∗ 0.323) ;
8 i n pu t [ i ] . 2 = ( f l o a t ) ( i + 2 . 0 ) ;
9 }
10
11 // Computation
12 Flo at [ ] output = mult . apply ( i np u t ) ;
If accelerator enabled, the map expression is rewritten in lower
level operations automatically.
map(λ) = MapAccelerator(λ) =
CopyIn().computeOCL(λ).CopyOut()
14 / 26](https://image.slidesharecdn.com/gpusgraal-150708180913-lva1-app6892/85/Gpus-graal-14-320.jpg)
![Enabling
Heterogeneous
Computing in
Java with
Graal
Juan Fumero,
Michel
Steuwer,
Christophe
Dubach
Introduction
API
Runtime Code
Generation
Data
Management
Results
Conclusion
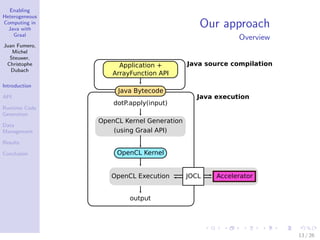
Our Approach
Overview
Ar r ayFunc
Map
MapThr eads
MapOpenCL
Reduce. . .
appl y( ) {
f or ( i = 0; i < si ze; ++i )
out [ i ] = f . appl y( i n[ i ] ) ) ;
}
appl y( ) {
f or ( t hr ead : t hr eads)
t hr ead. per f or mMapSeq( ) ;
}
appl y( ) {
copyToDevi ce( ) ;
execut e( ) ;
copyToHost ( ) ;
}
Funct i on
15 / 26](https://image.slidesharecdn.com/gpusgraal-150708180913-lva1-app6892/85/Gpus-graal-15-320.jpg)
![Enabling
Heterogeneous
Computing in
Java with
Graal
Juan Fumero,
Michel
Steuwer,
Christophe
Dubach
Introduction
API
Runtime Code
Generation
Data
Management
Results
Conclusion
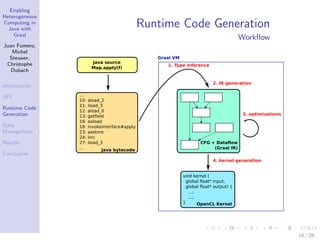
OpenCL code generated
1 double lambda0 ( f l o a t p0 ) {
2 double c a s t 1 = ( double ) p0 ;
3 double r e s u l t 2 = c a s t 1 ∗ 2 . 0 ;
4 return r e s u l t 2 ;
5 }
6 k e r n e l void lambdaComputationKernel (
7 g l o b a l f l o a t ∗ p0 ,
8 g l o b a l i n t ∗ p0 index data ,
9 g l o b a l double ∗p1 ,
10 g l o b a l i n t ∗ p 1 i n d e x d a t a ) {
11 i n t p0 dim 1 = 0; i n t p1 dim 1 = 0;
12 i n t gs = g e t g l o b a l s i z e (0) ;
13 i n t loop 1 = g e t g l o b a l i d (0) ;
14 f o r ( ; ; loop 1 += gs ) {
15 i n t p 0 l e n d i m 1 = p 0 i n d e x d a t a [ p0 dim 1 ] ;
16 bool cond 2 = loop 1 < p 0 l e n d i m 1 ;
17 i f ( cond 2 ) {
18 f l o a t auxVar0 = p0 [ loop 1 ] ;
19 double r e s = lambd0 ( auxVar0 ) ;
20 p1 [ p 1 i n d e x d a t a [ p1 dim 1 + 1] + loop 1 ]
21 = r e s ;
22 } e l s e { break ; }
23 }
24 }
17 / 26](https://image.slidesharecdn.com/gpusgraal-150708180913-lva1-app6892/85/Gpus-graal-17-320.jpg)
![Enabling
Heterogeneous
Computing in
Java with
Graal
Juan Fumero,
Michel
Steuwer,
Christophe
Dubach
Introduction
API
Runtime Code
Generation
Data
Management
Results
Conclusion
Investigation of runtime for BS
Black-scholes benchmark.
Float[] =⇒ Tuple2 < Float, Float > []
0.0
0.2
0.4
0.6
0.8
1.0
Amountoftotalruntimein%
Unmarshaling
CopyToCPU
GPU Execution
CopyToGPU
Marshaling
Java overhead
• Un/marshal data takes
up to 90% of the time
• Computation step
should be dominant
This is not acceptable. Can we do better?
18 / 26](https://image.slidesharecdn.com/gpusgraal-150708180913-lva1-app6892/85/Gpus-graal-18-320.jpg)





The document discusses enabling heterogeneous computing in Java using Graal. It presents an approach with three levels of abstraction: parallel skeletons API based on functional programming, a high-level optimizing library that rewrites operations for specific hardware, and OpenCL code generation and runtime for data management across heterogeneous architectures. The runtime analyzes Java bytecode, generates optimized OpenCL kernels, manages data transfer and execution to accelerate applications on accelerators like GPUs in a transparent manner to the programmer.



































































