Download to read offline























![MORE USEFUL
EXAMPLE
Chad Windnagle - @drmmr763
$message = [
‘messageType => ‘sendEmail’,
‘email’ => [
‘to’ => ‘speakers@jdayflorida.com’,
‘from’ => ‘chad@chadwindnagle.com’,
‘subject => ‘Hello speakers!’,
‘body’ => ‘Please come to my session!’
]
];](https://image.slidesharecdn.com/getqueued-170225142331/85/Get-queued-28-320.jpg)

![MORE USEFUL
EXAMPLE
Chad Windnagle - @drmmr763
// get the message from the queued job
$jobData = json_decode($job->getData());
$messageType = $jobData[‘messageType’];
if ($messageType == ‘sendEmail’ {
// “to”, “from”, “subject”, & “body”
$this->sendEmail($jobData[‘email’]);
}
Service worker executes based on message type](https://image.slidesharecdn.com/getqueued-170225142331/85/Get-queued-30-320.jpg)






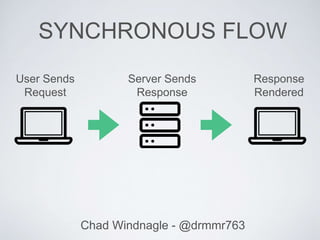
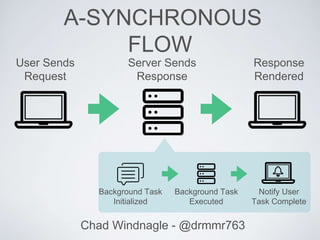
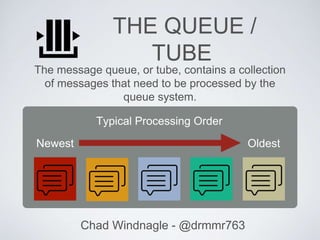
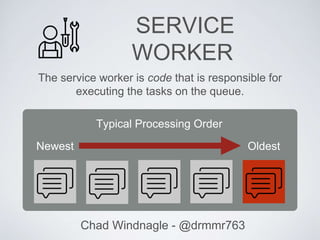
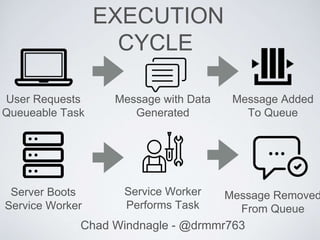
This document discusses using queues to improve asynchronous processing in web applications. It introduces queues and their components like messages, queues, and service workers. It then demonstrates how to implement a queue using Beanstalkd, including installing it, adding and getting messages from the queue, and executing tasks. Sample code is provided for a messaging system that queues email sending. The document encourages queueing long-running tasks like notifications, image processing, and API requests to improve performance.
























































