Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
kazumat53
PDF, PPTX
149 views
【Gensparkで作成】画像生成AIの基盤モデルから実際のツールまで歴史を紐解いてみた
Gensparkスーパーエージェントモードで作成したスライドです。
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PDF
PCSJ/IMPS2021 講演資料:深層画像圧縮からAIの生成モデルへ (VAEの定量的な理論解明)
by
Akira Nakagawa
PPTX
JDLA_GAI Test2023.pptx
by
JDLAPR
PDF
SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜
by
SSII
PPTX
local launch small language model of AI.
by
Takao Tetsuro
PDF
[Developers Summit 2018] Microsoft AIプラットフォームによるインテリジェント アプリケーションの構築
by
Naoki (Neo) SATO
PDF
AIについて学んだこと ~ 生成AIとは? ~
by
iPride Co., Ltd.
PDF
画像生成AIのビジネス活用術をご紹介! 5つの活用シーンと具体的事例も併せて紹介します
by
otakai1201
PDF
Transformer 動向調査 in 画像認識(修正版)
by
Kazuki Maeno
PCSJ/IMPS2021 講演資料:深層画像圧縮からAIの生成モデルへ (VAEの定量的な理論解明)
by
Akira Nakagawa
JDLA_GAI Test2023.pptx
by
JDLAPR
SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜
by
SSII
local launch small language model of AI.
by
Takao Tetsuro
[Developers Summit 2018] Microsoft AIプラットフォームによるインテリジェント アプリケーションの構築
by
Naoki (Neo) SATO
AIについて学んだこと ~ 生成AIとは? ~
by
iPride Co., Ltd.
画像生成AIのビジネス活用術をご紹介! 5つの活用シーンと具体的事例も併せて紹介します
by
otakai1201
Transformer 動向調査 in 画像認識(修正版)
by
Kazuki Maeno
Similar to 【Gensparkで作成】画像生成AIの基盤モデルから実際のツールまで歴史を紐解いてみた
PDF
東北大学 先端技術の基礎と実践_深層学習による画像認識とデータの話_菊池悠太
by
Preferred Networks
PDF
Deep learningの概要とドメインモデルの変遷
by
Taiga Nomi
PDF
人工知能技術を用いた各医学画像処理の基礎 (2022/09/09)
by
Yutaka KATAYAMA
PPTX
人工知能を用いた医用画像処理技術
by
Yutaka KATAYAMA
PDF
拡散する画像生成.pdf
by
NTTDOCOMO-ServiceInnovation
PDF
AIの取り組み.pdf
by
KunihiroSugiyama1
PDF
【卒業論文】特徴付加型敵対的生成ネットワークによる ファッションデザイン画像生成(Fashion Design Generation based on G...
by
鬼木 渚沙
PDF
【CVPR 2020 メタサーベイ】Neural Generative Models
by
cvpaper. challenge
PDF
AIがAIを生み出す?
by
Daiki Tsuchiya
PDF
SPADE :Semantic Image Synthesis with Spatially-Adaptive Normalization
by
Tenki Lee
PPTX
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
PDF
前景と背景の画像合成技術
by
Morpho, Inc.
PDF
広告クリエイティブ制作におけるコンピュータビジョングラフィックデザイン CA Data Engineering & Data Analysis WS #9
by
Kazuhiro Ota
PDF
Considerations-on-GenerativeAI-and-Copyright.pdf
by
hirokiabe58
PDF
JSAI コミック工学SS 招待講演「機械学習で eBookJapan を加速できるか?」
by
Matsushita Laboratory
PPTX
音楽・エンターテインメント x AI (29 Aug 2017)
by
Yuki Abe
PDF
Data Science Workshop 「クリエイティブAI」で新たな価値を創造する
by
Masaya Mori
PDF
プランナー目線の生成AI妥協論.pdf
by
ssuser019994
PDF
生成モデルの Deep Learning
by
Seiya Tokui
PDF
TAI_GDEP_Webinar_1a_27Oct2020
by
ssuser5b12d1
東北大学 先端技術の基礎と実践_深層学習による画像認識とデータの話_菊池悠太
by
Preferred Networks
Deep learningの概要とドメインモデルの変遷
by
Taiga Nomi
人工知能技術を用いた各医学画像処理の基礎 (2022/09/09)
by
Yutaka KATAYAMA
人工知能を用いた医用画像処理技術
by
Yutaka KATAYAMA
拡散する画像生成.pdf
by
NTTDOCOMO-ServiceInnovation
AIの取り組み.pdf
by
KunihiroSugiyama1
【卒業論文】特徴付加型敵対的生成ネットワークによる ファッションデザイン画像生成(Fashion Design Generation based on G...
by
鬼木 渚沙
【CVPR 2020 メタサーベイ】Neural Generative Models
by
cvpaper. challenge
AIがAIを生み出す?
by
Daiki Tsuchiya
SPADE :Semantic Image Synthesis with Spatially-Adaptive Normalization
by
Tenki Lee
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
前景と背景の画像合成技術
by
Morpho, Inc.
広告クリエイティブ制作におけるコンピュータビジョングラフィックデザイン CA Data Engineering & Data Analysis WS #9
by
Kazuhiro Ota
Considerations-on-GenerativeAI-and-Copyright.pdf
by
hirokiabe58
JSAI コミック工学SS 招待講演「機械学習で eBookJapan を加速できるか?」
by
Matsushita Laboratory
音楽・エンターテインメント x AI (29 Aug 2017)
by
Yuki Abe
Data Science Workshop 「クリエイティブAI」で新たな価値を創造する
by
Masaya Mori
プランナー目線の生成AI妥協論.pdf
by
ssuser019994
生成モデルの Deep Learning
by
Seiya Tokui
TAI_GDEP_Webinar_1a_27Oct2020
by
ssuser5b12d1
【Gensparkで作成】画像生成AIの基盤モデルから実際のツールまで歴史を紐解いてみた
1.
AI画像生成技術の全体像 AI画像生成技術の全体像 基盤モデルから生成段階までの技術まとめ 基盤モデル 学習プロセス 生成技術 クリエイティブAI AiHUBレベルの知識で理解する 画像生成AIの基礎から応用まで
2.
画像生成AIの概要と発展 画像生成AIの概要と発展 主要アーキテクチャの種類 GAN (敵対的生成ネットワーク): 生成器と識別器の競争で学習 VAE
(変分オートエンコーダ): 潜在空間で画像を圧縮・生成 拡散モデル (Diffusion Model): ノイズ除去プロセスで画像を生成 Transformer: 自己注意機構による画像生成 画像生成AIの発展タイムライン 画像生成AIとは テキストや画像のプロンプト入力から新しい画像を生成する技術。深層学 習と大量のデータセットを活用して、人間が描いたように見える画像を作 り出します。 深層学習 大量データ 生成能力 2014年 GANの登場 (Ian Goodfellow) 最初の敵対的生成ネットワークが発表 2017年 CycleGAN、Pix2Pixの開発 画像変換技術の大幅な進化 2020年 DALL-E (OpenAI)の登場 テキストから画像を生成する最初の大規模モデル 2021年 CLIP (OpenAI)の登場 テキストと画像の理解を橋渡しする技術 2022年 Stable Diffusionの公開 オープンソースの高品質画像生成モデル 2023年〜現在 Midjourney、DALL-E 3、多様なモデル 高品質化、カスタマイズ、実用化の時代へ 2 / 20
3.
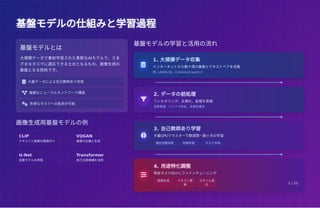
基盤モデルの仕組みと学習過程 基盤モデルの仕組みと学習過程 画像生成用基盤モデルの例 CLIP テキストと画像の関連付け VQGAN 画像の圧縮と生成 U-Net 拡散モデルの骨格 Transformer 自己注意機構を活用 基盤モデルの学習と活用の流れ 基盤モデルとは 大規模データで事前学習された柔軟なAIモデルで、さま ざまなタスクに適応できる土台となるもの。画像生成の 基盤となる技術です。 大量データによる自己教師あり学習 複雑なニューラルネットワーク構造
多様なタスクへの転用が可能 1. 大規模データ収集 インターネットから数十億の画像とテキストペアを収集 例: LAION-5B、CommonCrawlなど 2. データの前処理 フィルタリング、正規化、拡張を実施 品質管理、バイアス除去、多様性確保 3. 自己教師あり学習 大量GPUクラスターで数週間〜数ヶ月の学習 潜在空間学習 対照学習 マスク予測 4. 用途特化調整 特定タスク向けにファインチューニング 画像生成 テキスト理 解 スタイル適 応 3 / 20
4.
拡散モデル(Diffusion Model)の仕組み 拡散モデル(Diffusion Model)の仕組み 拡散モデルの特徴
高品質な画像生成 細部まで精密に生成可能 安定した学習プロセス GANより学習が安定している 多様な条件付け テキスト、画像など様々な条件で制御可能 潜在空間での効率的な処理 Stable Diffusionの基礎技術 拡散モデルの動作原理 ① 拡散過程 (Forward Diffusion) ノイズ追加 さらにノイズ 学習時、元画像に少しずつノイズを加え、最終的に完全なノイズにする過程 ② 逆拡散過程 (Reverse Diffusion) ノイズ除去 さらに除去 生成時、ランダムノイズから徐々にノイズを除去して画像を生成する過程 拡散モデルとは 画像にノイズを徐々に追加し、完全にランダムなノイズにする「拡散過 程」と、ノイズから元の画像を復元する「逆拡散過程」を学習した生成モ デル。現代の画像生成AIの中核技術です。 ノイズ追加 ノイズ除去 確率過程 条件付け (Conditioning) テキストや画像などの条件を与えることで、逆拡散過程を制御し、特定の内 容やスタイルの画像を生成 4 / 20
5.
Stable Diffusionのアーキテクチャ Stable Diffusionの3つの主要コンポーネント 生成プロセスの流れ Stable
Diffusionのアーキテクチャ プロンプト入力 テキスト埋め込み ランダムノイズ ノイズ除去 潜在→画像 生成画像 Stable Diffusionは「潜在拡散モデル」を実装した画像生成AIで、効率的な計算のため潜在空間で処理を行います。 オープンソースで公開され、高品質かつ 多様な画像生成を可能にしました。 VAE (変分オートエンコー ダ) 画像の圧縮と復元を担当 Encoder 画像→潜在表現 Decoder 潜在表現→画像 画像サイズ:512×512 潜在表現:64×64×4 →計算量が1/64に軽減 U-Net (拡散モデル) ノイズ除去と画像生成の核心部 ノイズ予測器 各ステップで付加されたノイズを予測 Cross-Attention テキスト埋め込みと潜在表現を結合 ダウンサンプリング→アップサンプリング スキップ接続で特徴を保持 数十〜数百ステップの繰り返し処理 Text Encoder (CLIP) テキスト理解と条件付け CLIPテキストエンコーダ テキストを埋め込みベクトルに変換 OpenAI開発のCLIPモデル テキスト・画像の関連性を学習済み Transformerベースのアーキテクチャ 77トークンまでの入力をサポート 5 / 20
6.
主要な画像生成モデルの比較 主要な画像生成モデルの比較 DALL-E 3 OpenAI
(2023) 高精度テキスト理解 正確なレイアウト ChatGPTと連携 • GPT-4の強力なテキスト理解能力 • 複雑なプロンプトへの対応力 • 商用利用可能(制限あり) • 高度な安全フィルタ搭載 技術基盤 拡散モデル + 先進的言語理解 Midjourney Midjourney, Inc (V6 2024) 芸術的表現 高品質 Discord統合 • 美的センスに優れた画像生成 • 芸術性と創造性を重視 • 独自の画風とスタイル • コミュニティの強さ 技術基盤 独自のハイブリッドアーキテクチャ Stable Diffusion Stability AI (XL/3 2023-2024) オープンソース カスタマイズ性 ローカル実行 • 完全なカスタマイズと拡張性 • 無料で利用可能 • モデル改良の容易さ • 世界中の開発者コミュニティ 技術基盤 潜在拡散モデル + CLIP 現在、複数の強力な画像生成AIモデルが存在し、それぞれに特徴があります。各モデルの特性と優位点を把握することで、用途に応じた選択が可能になりま す。
7.
Imagen Google (2022- 2024) 高度なテキスト理解 高精細画像
鮮明な写実性 • T5-XXLによるテキスト処理 • 写実的な画像生成能力 • Google AIシステムとの統 合 • 特にGoogleドキュメント での活用 拡散モデル + 大規模言語モデル処理 Adobe Firefly Adobe (2023) 商用安全 Photoshop連携 クリエイター向け • ライセンス取得済みデータ で学習 • 商用利用に特化 • Adobe製品との緊密な統合 • デザイナーに最適化された UI 独自モデル + ライセンスコンテンツ学習 6 / 20
8.
追加学習(ファインチューニング)の仕組み ファインチューニングの基本プロセス 主要なファインチューニング技術 追加学習(ファインチューニング)の仕組み 既存モデル 少量の学習画像 特定パラメータ調整 カスタムモデル完成 特化した画像生成 LoRA Low-Rank Adaptation 低リソース
高速学習 軽量 • 元モデルの一部のみを更新 • 低ランク行列による効率化 • 数MB〜数十MBの小さなファイル • 複数LoRAの組み合わせ可能 DreamBooth Google Research (2022) 個人化 少数サンプル 高品質 • 3〜5枚の画像から学習可能 • 特定の被写体を詳細に学習 • 「固有名詞」とペアで学習 • モデル全体のチューニング Textual Inversion トークン埋め込み学習 超軽量 埋め込みのみ コンセプト学習 • 新しいトークン(埋め込み)だけを学習 • 数KBの非常に小さなファイル • 特定のスタイルやコンセプトを表現 • 「<新トークン>」で使用 ファインチューニングは、既存の基盤モデルを特定のスタイルやコンテンツに適応させる技術です。少量のデータで効率的に学習でき、個人化された画像生 成を可能にします。 ファインチューニングの利点 個人化 特定人物・キャラクターの学習 スタイル特化 特定の芸術様式・画風の学習 $ 低コスト 基盤モデルから効率的に派生 効率的 少量データでの特化学習 応用事例 キャラクター制作:既存のアニメキャラや創作キャラクターの一貫した生成 製品カタログ:特定ブランドの製品スタイルに合わせた画像生成 アバター作成:自分自身や特定人物の様々なシチュエーションでのアバター 商業デザイン:企業の特定ビジュアルアイデンティティに合わせた生成 芸術創作:特定アーティストのスタイルを学習した創作支援 7 / 20
9.
プロンプトエンジニアリングと画像生成プロセス プロンプトエンジニアリングと画像生成プロセス 効果的なプロンプト構造 基本要素 被写体 中心となる物体や人物 スタイル アート様式、画風
背景 シーン、場所の状況 照明 光源、時間帯 高度な指定 カメラ設定 焦点距離、シャッタースピード、レンズタイプ # 重み付け (重要な要素:1.2) のように指定、負の値で除外 品質修飾子 detailed, masterpiece, 8k, high-quality など プロンプト例: 美しい日本庭園にいる侍、刀を持つ、夕焼け、映画のワンシーン、シネマティック照明、ボケ味、 8k解像度、highly detailed, masterpiece 画像生成プロセスのフロー 1 プロンプト解析と埋め込み CLIPなどのテキストエンコーダがプロンプトを数値ベクトルに変換 2 潜在空間でのノイズ初期化 ランダムノイズを生成(Seed値で制御可能) 3 逆拡散ステップ実行 U-Netがプロンプトの指示に従いながら、徐々にノイズを除去 4 潜在表現からの画像復元 VAEデコーダが潜在表現から最終的な画像ピクセルを生成 生成パラメータの影響 Seed値 初期ノイズパターンを決定 CFG Scale プロンプト忠実度の強さ ステップ数 ノイズ除去の繰り返し回数 サンプラー ノイズ除去アルゴリズム プロンプトエンジニアリングとは、AIモデルが理解しやすい形で指示を与え、望ましい画像を生成するための技術です。 適切なプロンプト設計により、生 成される画像の品質、スタイル、構図などを細かく制御することができます。 8 / 20
10.
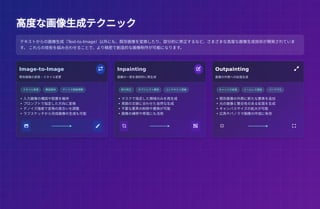
高度な画像生成テクニック 高度な画像生成テクニック Image-to-Image 既存画像の変換・スタイル変更 スタイル変換 構図維持
デノイズ強度調整 • 入力画像の構図や配置を維持 • プロンプトで指定した方向に変換 • デノイズ強度で変換の度合いを調整 • ラフスケッチから完成画像の生成も可能 Inpainting 画像の一部を選択的に再生成 部分修正 オブジェクト置換 コンテキスト認識 • マスクで指定した領域のみを再生成 • 周囲の文脈に合わせた自然な生成 • 不要な要素の削除や置換が可能 • 画像の補修や修復にも活用 Outpainting 画像の外側への拡張生成 キャンバス拡張 シームレス連結 パノラマ化 • 既存画像の外側に新たな要素を追加 • 元の画像と整合性のある拡張を生成 • キャンバスサイズの拡大が可能 • 広角やパノラマ画像の作成に有効 テキストからの画像生成(Text-to-Image)以外にも、既存画像を変換したり、部分的に修正するなど、さまざまな高度な画像生成技術が開発されていま す。 これらの技術を組み合わせることで、より精密で創造的な画像制作が可能になります。
11.
ControlNet 精密な条件付け制御 ポーズ制御 エッジ/深度制御 セグメンテーション ControlNetは拡散モデルに特定の条件付けを行い、画像生成 をより精密に制御する技術です。人物のポーズ、線画、深度 マップ、セグメンテーションマップなど、様々な条件付けが 可能で、これにより構図やレイアウトを正確に指定した画像 生成が実現します。 ポーズ
線画 深度マップ ノーマルマッ プ 超解像化 画質強化技術 高解像度化 ディテール強化 ノイズ除去 生成された画像の解像度を上げながら、ディテールを向上さ せる技術です。単純な拡大ではなく、AIが新たなディテールを 推測して追加します。ESRGAN、Real-ESRGANなどの超解像 モデルやStable Diffusion自体のupscaler機能を使用し、鮮 明で高品質な最終画像に仕上げることができます。 512×512 2048×2048 9 / 20
12.
モデルの「くりえみ」とAI画像生成 モデルの「くりえみ」とAI画像生成 くりえみ / KURIEMI
連続起業家 / モデル / タレント / CMO AIHUB株式会社 CMO PINYOKIO株式会社 CEO AI School代表 「SNSのフェチ天使」として自己プロデュースを得意とし、自身 のSNS構築や自社ブランドの美容品開発なども手掛ける多才なク リエイター。AI関連事業やバーチャルヒューマン領域に強い関心 を持ち、革新的なビジネスを展開。 61.5万フォロワー 127万フォロワー 「世の中にイノベーションを、革命を」 ー 職業、革命家 ー AI画像生成プロジェクト AiHUBでの活動と貢献 AIグラビア写真集 AiHUB所属の6人のクリエイターが"フェチ天 使"をコンセプトに独自の世界観で作り上げ た、生成AIとリアル写真が融合した新しいグラ ビア写真集。 AI生成画像 実写融合 新時代表現 Bachamo (バチャモ) 撮影いらずのファッションAI「Bachamo」は 世界観ごとデザインするAIモデルを創出。服を 着せるだけではなく、独自の世界観を表現。 ファッションAI 世界観デザイン コスト削減 くりえみ氏は連続起業家、モデル、タレントとして活躍しながら、AI技術とクリエイティブの融合を推進。AiHUB株式会社のCMOとして画像生成AI領域を リードし、AIと人間のクリエイティビティの新たな可能性を追求しています。 AI分野でのビジョン バーチャルヒューマンのスター創出 ライブコマースなどでのマネタイズ リアルとバーチャルの2軸展開 「数年後の当たり前」を先取り 2023年9月 AiHUB株式会社 CMOに就任 AIと人間のクリエイティビティが融合するハブを目指す 2023年9月 AI画像生成サービス「AiMe(アイミー) 」リリース クリエイターやアーティスト向け高品質AI画像生成サービス 2023年〜2024年 「AIくりえみ」学習モデル制作 AI天使(AiHUB所属アーティスト)とのコラボレーション 2024年 「AIアイドル生成講座」プロデュース Stable Diffusionなど画像生成AIの知識を活かした教育活動 2025年3月 ファッションAI「Bachamo」立ち上げ AiHUB、Pinyokio、Triple3の共同事業 10 / 20
13.
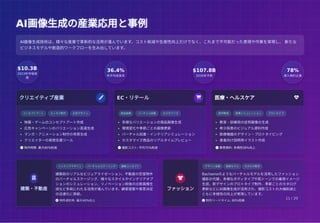
AI画像生成の産業応用と事例 AI画像生成の産業応用と事例 $10.3B 2023年市場規 模 36.4% 年平均成長率 $107.8B 2030年予測 78% 導入検討企業 クリエイティブ産業 コンセプトアート エンタメ制作
広告デザイン 映画・ゲームのコンセプトアート作成 広告キャンペーンのバリエーション高速生成 マンガ・アニメーション制作の背景生成 クリエイターの発想支援ツール 制作時間: 最大90%削減 EC・リテール 商品画像 バーチャル試着 カスタマイズ 多様なバリエーションの商品画像生成 環境変化や季節ごとの画像更新 バーチャル試着・インテリアシミュレーション カスタマイズ商品のリアルタイムプレビュー 撮影コスト: 平均75%削減 医療・ヘルスケア 医学教育 疾患シミュレーション プロトタイプ 教育・訓練用の症例画像の生成 希少疾患のビジュアル資料作成 医療機器のデザイン・プロトタイピング 患者向け説明用イラスト作成 教育資料: 多様性58%向上 建築・不動産 インテリアデザイン バーチャルステージング 建築コンセプト 建築前のリアルなビジュアライゼーション、不動産の空室物件 のバーチャルステージング、様々なスタイルやインテリアオプ ションのシミュレーション、リノベーション前後の比較画像生 成など多岐にわたる活用が進んでいます。顧客提案や意思決定 の迅速化に貢献。 物件成約率: 最大40%向上 ファッション デザイン支援 仮想モデル カタログ制作 Bachamoのようなバーチャルモデルを活用したファッション 撮影の代替、多様なボディタイプや肌トーンでの着用イメージ 生成、新デザインのプロトタイプ制作、季節ごとのカタログ 更新などにAI画像生成が活用され、撮影コストの大幅削減と ともに多様性の向上が実現しています。 制作リードタイム: 80%短縮 AI画像生成技術は、様々な産業で革新的な活用が進んでいます。コスト削減や生産性向上だけでなく、これまで不可能だった表現や作業を実現し、 新たな ビジネスモデルや創造的ワークフローを生み出しています。 11 / 20
14.
AI画像生成の課題と限界 AI画像生成の課題と限界 技術的課題 人体の解剖学的正確性 要改善 指の数や関節、身体比率などに不自然さが生じることがある テキスト・文字の生成
困難 画像内のテキストは読めない文字や不自然な配置になりやすい 複雑な構図・多人数シーン やや弱い 多くの要素や人物を含むシーンでは一貫性の維持が難しい 3D空間や遠近感の理解 改善中 複雑な遠近法や物理法則に矛盾が生じることがある 計算資源と学習の課題 計算コスト 高解像度の画像生成には強力なGPUが 必要。リアルタイム生成や高速処理に 限界がある メモリ要件 大規模モデルは数十GBのVRAMを必要 とし、消費者向けハードウェアでの実 行に制約がある データ依存性 学習データに含まれないコンセプトや 様式の生成は困難。バイアスの問題も 存在 生成時間 高品質な画像の生成に時間がかかり、 動画やリアルタイムアプリケーション への応用が制限される AI画像生成技術は急速に進化していますが、現在のモデルにはまだいくつかの技術的課題や限界が存在します。 これらの課題を理解することで、技術の適 切な利用や将来の発展方向性を見据えることができます。 倫理的・社会的課題 著作権問題:学習データに含まれる作品の権利関係や、生成画像の著作権帰属が 不明確 偽情報生成:実在しない写真やシーンの作成による虚偽情報拡散のリスク 不適切コンテンツ:悪意ある利用による不適切画像の生成可能性 アーティストへの影響:人間のクリエイターの仕事や価値への影響 今後の改善方向性 解像度向上 より高解像度での直接生成技術 効率化 生成速度と計算効率の向上 3D理解 3D空間と物理法則の一貫性向上 倫理ガイドライン 公平で透明性のある開発基準の確立12 / 20
15.
AI画像生成の将来展望と技術動向 AI画像生成の将来展望と技術動向 新興アプリケーション領域 VR/ARコンテンツ リアルタイムで環境に適応する没入型 コンテンツの自動生成
ゲーム開発 プレイヤーの行動に応じてリアルタイ ムでアセットを生成する動的ゲーム世 界 科学研究 複雑な分子構造のモデリングや宇宙現 象のシミュレーション可視化 自律ロボティクス 複雑な環境を視覚的に理解し対応する ロボットビジョンシステム バーチャルヒューマン くりえみ氏が推進する「リアルとバーチャルの2軸展開」型デジタルヒューマンが、エ ンターテイメントやコマースの新しい形として確立 次世代拡散モデル 高速サンプリング ワンショット生成 従来の何百ステップもの反復処理が不要な、1〜3ス テップで高品質画像を生成する次世代アルゴリズ ム。計算効率が劇的に向上し、モバイルデバイスで もリアルタイム生成が可能に。 ニューロシンボリックAI 論理的推論 物理法則適用 ディープラーニングとシンボリックAIを融合し、空間 関係や物理法則を理解した画像生成。自然で解剖学 的に正確な人物像や、物理的に整合性のある複雑な シーンを描画可能に。 連続的マルチモーダル クロスモーダル シームレス変換 テキスト、画像、音声、動画を連続的に変換・融合 できる統合AIシステム。音楽に合わせて変化する画 像生成や、会話から即座にビジュアル化するインタ ラクティブな体験を実現。 AI画像生成技術は急速な進化を続けており、次世代のモデルやアプローチが次々と登場しています。 将来的には創造的表現の可能性をさらに広げ、様々な 産業で新たな価値を創出することが期待されています。 技術発展の展望タイムライン 2024-2025 リアルタイム高解像度生成 計算効率の向上により、スマートフォンでも高品質な画像生成が可能に 2025-2026 3D・4D生成モデルの普及 テキストから直接3Dアセットや時間変化を含む4Dコンテンツの生成が一般化 2026-2027 マルチモーダル融合システム 画像・テキスト・音声・動画を統合的に扱うAIシステムの登場 2027-2030 創造的自律エージェント ユーザーの意図を深く理解し、独自の美的センスで自律的に創造する高度AIの出現 13 / 20
16.
クリエイティブワークフローへの統合 クリエイティブワークフローへの統合 デザインソフトウェアとの統合 Adobe Creative
Cloud FireflyがPhotoshop、Illustrator、Premiere Proに統合され、コンテンツ生成・編 集を効率化 Figma/Canva デザインツール内で直接AIによる画像生成・スタイル変更が可能に Blender/Unity/Unreal 3DCGやゲーム開発環境との連携によるテクスチャ・アセット生成の自動化 クリエイティブソフトウェアへの組み込みにより、プロセス内での切れ目のない利 用が進み、アイデア具現化からブラッシュアップまでを効率化 コンテンツ制作パイプライン アイデア発 想 コンセプト設 計 制作・実 装 各段階でAI画像生成を活用し、反復と実験の速度を劇的に向上 迅速な反復 数秒で複数バリエーションを生成し比 較検討 スタイル転送 一貫したビジュアルアイデンティティ の維持 コラボレーション チーム間のビジョン共有を視覚的に促 進 自動化 バリエーション生成やアセット更新の 効率化 「人間+AI」の共創により、クリエイターは低付加価値タスクから解放され、より創 造的な意思決定や戦略的デザインに集中可能に AI画像生成技術は単体で使用されるだけでなく、既存のクリエイティブツールやワークフローに統合されることで、より大きな価値を発揮します。 ここで は、現在進行中の統合事例と、クリエイティブプロセス全体を変革する可能性について探ります。 APIとカスタムソリューション エンタープライズAPI統合 OpenAI、Stability AI、Midjourneyなどが提供するAPIを活 用し、独自アプリケーションやワークフローに画像生成機能を 組み込み。 企業特有のブランドスタイルやデザイン言語に合 わせたカスタマイズが可能。 オンプレミスデプロイ Stable Diffusionなどオープンソースモデルによる社内展開 で、データセキュリティと独自ニーズに対応。 LoRAや DreamBoothによる企業固有のビジュアル資産を学習させた モデルのプライベート運用。 自律クリエイティブシステム バーチャルヒューマンや自律エージェントと連携した、継続的 なコンテンツ生成システム。 ユーザーやマーケット反応をフ ィードバックに取り入れ、最適化を行う自己学習型システムへ の発展。 「創造性の民主化とプロフェッショナルの拡張が同時に進行」 14 / 20
17.
倫理的配慮と責任あるAI画像生成 倫理的配慮と責任あるAI画像生成 著作権と知的財産 学習データ 生成コンテンツ
権利帰属 主要な課題: AIが学習に使用したクリエイターの作品に対する権利と、生成さ れた画像の著作権帰属 既存作品に酷似した画像生成によるオリジナル作品の価値低下 特定アーティストのスタイル模倣に関する同意取得のあり方 学習データに含まれるコンテンツのライセンス問題 "画像AIシステムの設計・使用は、クリエイターの権利を尊重し、適切な補償や帰属を確保する 方法で行われるべき" 現在の対応状況: Adobe Firefly: ライセンス済みコンテンツの みで学習 Midjourney: 商用利用に明確なライセンス提 供 透明性と開示 AI生成表示 デジタル透かし 出所開示 社会的要請: AI生成コンテンツの明示と、情報の真正性を確保するための透明 性確保 ディープフェイクや偽情報拡散のリスク軽減 AIによって生成されたメディアの識別と検証 メタデータや透かしによる生成コンテンツの追跡 プロセスの説明可能性と監査可能性の確保 C2PA (Content Provenance and Authenticity) Adobe、Microsoft、Twitterなどが推進する、コンテンツの出所と真正性を証明する技術標 準。 メタデータと暗号技術を用いて、コンテンツがどのように作成・編集されたかを記録。 AI生成コンテンツの開示がもたらす信頼性 透明性 信頼構築 誤解防止 AI画像生成技術の普及に伴い、著作権問題やコンテンツの真正性、プライバシー保護など様々な倫理的課題が浮上しています。 技術の健全な発展と社会的 受容のためには、透明性のある運用と責任あるガイドラインの確立が不可欠です。 責任あるAI画像生成のためのガイドライン 同意と権利保護 人物画像生成の際の本人同意 インフルエンサーやアーティストのスタイル学習時の許諾 くりえみ氏のように、モデル本人が自身の画像に関する権 利を管理する仕組み オプトアウト機能の提供 公平性とバイアス 多様な人種・性別・文化の公平な表現 学習データにおける偏りの検出と軽減 ステレオタイプ強化を防ぐ設計 多様なクリエイターによる評価と改善 規制と標準化 EU AI Actなど各国の規制枠組みへの対応 業界主導の倫理基準とベストプラクティス 国際的な標準化活動への参加 透明性と説明責任の確保 「創造的自由と社会的責任のバランスが持続可能なAI画像生成の鍵」 15 / 20
18.
AI画像生成を始めるための実践ガイド AI画像生成を始めるための実践ガイド 始め方ステップガイド おすすめリソースとツール クラウドサービス DALL-E
3 (OpenAI) Midjourney (Discord) Leonardo.AI Stable Diffusion Web Adobe Firefly 登録簡単 GPU不要 ローカルアプリ Stable Diffusion WebUI ComfyUI InvokeAI AUTOMATIC1111 Fooocus (初心者向け) 高度な制御 無料 学習リソース コミュニティサイト Civitai (モデル共有) Hugging Face AiHUBコミュニティ チュートリアル YouTube解説動画 Prompt Engineering Guide くりえみ氏のAI School プロンプトライブラリ PromptHero、Lexica、KreamAIなどのサイトで効果的なプロンプト例を参考にできます。プロ ンプトの構造やパラメータ設定を学べます。 AI画像生成技術を実際に使い始めるためのステップとリソースをご紹介します。初心者から上級者まで、 それぞれの段階に応じた学習パスとツールの選択 肢があります。 ステップ1: 基本理解を深める 基本的な用語や概念、各モデルの特徴を学習。AiHUBやオンラインチュートリアルで 基礎知識を身につけましょう。 ステップ2: クラウドサービスを試す DALL-E、Midjourney、Stable Diffusion Webなどのクラウドベースツールで手軽 に体験。プロンプト作成のコツを掴みます。 ステップ3: プロンプトエンジニアリングを学ぶ 効果的なプロンプト作成技術を習得。スタイル、構図、照明などの指定方法やパラメ ータ調整を実験しましょう。 ステップ4: ローカル環境のセットアップ より高度な制御や大量生成のため、Stable DiffusionをローカルPCにインストー ル。GPUが搭載されたPCがおすすめです。 ステップ5: カスタマイズと拡張 LoRAやTextual Inversionで独自モデルの学習。ワークフローに統合し、自分だけの 画像生成パイプラインを構築します。 実践Tips: 上達への近道 プロンプト管理 成功したプロンプトを記録・整理し、再利用可能なテンプレー トを作成。Seed値も記録して同じスタイルを再現できるよう にしましょう。 コミュニティ参加 Discord、Reddit、専門フォーラムなどのコミュニティに参加 して知識を共有。質問したり、作品を投稿して意見をもらいま しょう。 反復と比較 同じコンセプトで複数の設定やモデルを試し、結果を比較分 析。微調整を繰り返して、プロンプトとパラメータの影響を深 く理解しましょう。 「始めることは学ぶこと。実践から得られる知識が最も価値ある」 16 / 20
19.
AI画像生成の成功事例と実績 AI画像生成の成功事例と実績 企業の革新的事例 Bachamoのファッション革命 くりえみ氏らのAiHUB、Pinyokioなどが開発したAIファッションプラットフォ ーム「Bachamo」は撮影コストを90%削減しながら、ファッションの表現力 を拡大。単なる服の表示ではなく、世界観全体をデザインする新しいアプロー チを実現。 コスト削減
表現の拡張 環境負荷軽減 "服を着せるだけではなく、世界観ごとデザインするAIモデル" NVIDIAのOmniverse NVIDIAはAI画像・3D生成技術を統合したOmniverseプラットフォームによ り、自動車、建築、ゲーム開発の設計プロセスを変革。テキスト入力からの3D アセット生成により、プロトタイプ作成時間を75%短縮。 3D生成 シミュレーション デジタルツイン "テキストから3Dへの変換技術は設計ワークフローに革命をもたらした" クリエイティブ業界の変革事例 Netflixのコンセプトアート制作 Netflixの複数の制作チームがStable Diffusionをカスタマイズし、初期コンセ プトアートとビジュアル開発のプロセスを高速化。アイデア検討からビジュア ル具現化までの時間を80%短縮し、より多くの創造的可能性を探索。 制作効率化 視覚化支援 創造的探索 "AIツールは人間のクリエイターの想像力を拡張するパートナーとなっている" くりえみAIグラビア写真集 AiHUB所属の6人のクリエイターが「フェチ天使」をコンセプトに制作したAI グラビア写真集。実写とAI生成画像を融合させた新しい表現方法を確立し、デ ジタルコンテンツの新たな可能性を示した革新的プロジェクト。 ジャンル融合 新表現 スタイル確立 "生成AIとリアル写真の融合による新時代グラビアの誕生" AI画像生成技術は多様な分野で既に大きな成果を上げています。革新的なプロジェクトの実例を通して、 この技術がどのように実際のビジネスや創造的プ ロセスを変革しているかを見ていきましょう。 ビジネスインパクトと投資効果 65% 制作時間の削減 40% コスト削減 3.5倍 アイデア生成数の増加 85% 顧客満足度向上 「AI画像生成は単なるツールではなく、ビジネスモデルを変革する戦略的資産」 17 / 20
20.
AI画像生成技術の総括と未来展望 AI画像生成技術の総括と未来展望 学んだ主要ポイント 基盤モデルから生成まで 拡散モデルとLLMの連携が現代のAI画像生成の中核
Stable Diffusionは潜在空間での処理で軽量化を実現 VAE、U-Net、Text Encoderの3要素による構成 プロンプトエンジニアリングが出力品質の重要な決定要素 クリエイティブと産業応用 Bachamoのようなファッション分野での先進的取り組み くりえみ氏のAIグラビア写真集など融合コンテンツの誕生 エンターテイメント、建築、医療など幅広い産業への浸透 制作コスト削減と表現の可能性拡大の両立 将来展望と変革の方向性 技術進化の展望 計算効率の飛躍 ワンショット生成やモバイルデバイスでのリ アルタイム処理の実現 3D/4D領域への拡張 テキストから直接3Dモデルや動画を生成す る技術の普及 クロスモーダル統合 テキスト、画像、音声、動画を横断する統合 生成システム 創造的AIエージェント 自律的に美的センスを持ち発展するAIクリエ イターの出現 社会・産業変革の方向性 クリエイター共存: AIがツールとなり人間の創造性を拡張する新しい関係性の構 築 権利と倫理: 著作権法の更新と透明性のある制作プロセスの標準化 教育変革: クリエイティブ教育にAIツールが組み込まれコンセプト重視へ バーチャルヒューマン産業: くりえみ氏が提唱する「リアルとバーチャルの2軸 展開」の本格化 ここまで見てきたAI画像生成技術の全体像を振り返り、主要なポイントを整理しましょう。 基盤モデルから応用まで、この技術が今後どのように発展し、 私たちの創造活動やビジネスを変革していくのかを展望します。 創造の次なるステージへ AI画像生成技術は、単なるツールではなく創造プロセス全体を再定義するパラダイムシフトをもたらしています。 技術的な進化と社会的な受容が進む中 で、私たちは「人間とAIの共創」という新しい創造のステージに立っています。 「AIが創る未来は、それを使う私たちの想像力と責任感によって形作られる」 18 / 20
21.
さらに学びを深めるためのリソース さらに学びを深めるためのリソース オンラインコースとコミュニティ 学習コース AI
School by くりえみ Stable Diffusionを中心としたAI画像生成の実践講座 Practical Deep Learning for Coders 深層学習の基礎から応用までのハンズオン講座 Creative Applications of Deep Learning クリエイティブな生成AIアプリケーション開発の講座 コミュニティ Stable Diffusion Discord 最新モデルやテクニックを共有する活発なコミュニティ r/StableDiffusion ノウハウやプロンプト共有のサブレディット AiHUBコミュニティ 日本語での画像生成AI情報交換の場 技術資料と書籍 技術文書 Latent Diffusion Models Stable Diffusionの基礎となる論文 arXiv:2112.10752 Hugging Face Diffusers 拡散モデルの実装とAPIドキュメント The Illustrated Stable Diffusion ビジュアルでわかる技術解説 実践ツール モデル収集サイト Civitai Hugging Face Models プロンプトアシスタント PromptHero Lexica.art ComfyUI ノードベースの高度なUI。複雑なワークフローを視覚的に構築可能 AiMe(AiHUB) クリエイター向けの高品質AI画像生成サービス AI画像生成技術を更に探求するための厳選リソースをご紹介します。基礎知識の構築から実践的なスキル向上まで、 様々なレベルに対応した学習材料が揃 っています。 くりえみ氏によるAI関連リソース AI School 画像生成AIの活用法からビジネス応用まで学べる実践アカデミ ー 初心者向け 実践的 AiHUB株式会社 くりえみ氏がCMOを務めるAI画像生成に特化した企業 企業連携 最新技術 Bachamo AI技術を活用したファッションプラットフォーム 応用事例 実ビジネス 「学びは実践から。最先端のAI技術を使いこなしましょう」 19 / 20
22.
ありがとうございました ありがとうございました AI画像生成技術の全体像 基盤モデルと拡散技術が実現したAI画 像生成の仕組みを理解する プロンプトエンジニアリングとファイ ンチューニングで創造力を拡張する くりえみ氏らが牽引する革新的ビジネ スの事例から未来を展望する AiHUBレベルの知識で学ぶAI画像生成技術 基盤モデル 拡散モデル ファインチューニング
応用事例 未来展望 この資料を通して、AI画像生成の基盤技術から実用例まで幅広く学んでいただきました。 創造の可能性を広げる新たな 技術革命の一部として、 今後もAI画像生成技術の発展と応用に注目していきましょう。 新たな創造への扉を開く AI技術と人間の創造性が融合する未来へ 20 / 20
Download






















![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Developers Summit 2018] Microsoft AIプラットフォームによるインテリジェント アプリケーションの構築](https://cdn.slidesharecdn.com/ss_thumbnails/20180215developerssummitmicrosoftaiplatform-180218215607-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)








