Download to read offline













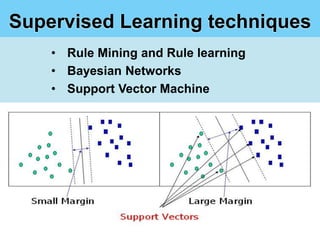


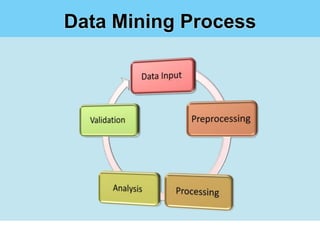

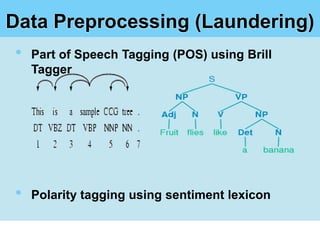
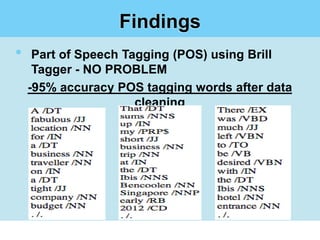



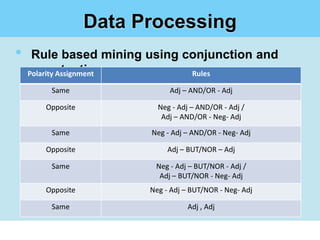
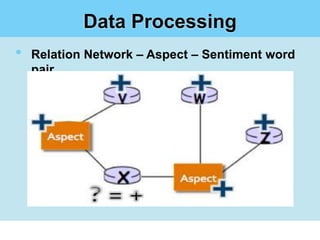
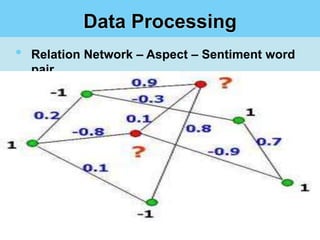









This document summarizes a student project on mining user opinions from hotel reviews. It discusses using data mining techniques like machine learning and sentiment analysis to analyze large amounts of online hotel review data and identify useful patterns. Specifically, it aims to predict review sentiment polarity, classify words by polarity in a sentiment lexicon, and detect relations between aspects and sentiments. The challenges include limitations of current sentiment lexicons and algorithms in capturing domain and context dependencies. The student proposes expanding existing lexicons using rule-based mining to help improve sentiment analysis accuracy.

























































