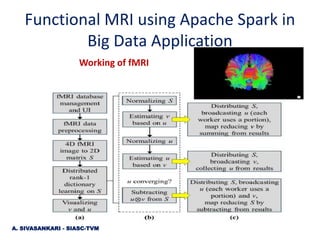
The document discusses the application of Apache Spark and GPUs in processing functional MRI (fMRI) data to enhance analysis in neuroimaging. It highlights the challenges of managing large datasets generated in healthcare and the improved efficiency offered by a newly developed PySpark-based pipeline, which is four times faster than existing methods. This advancement allows for better management of the complex, high-dimensional data associated with fMRI studies and provides a pathway for scalable data analysis in medical imaging.






















![[Review] High-performance medicine: the convergence of human and artificial i...](https://cdn.slidesharecdn.com/ss_thumbnails/reviewhigh-performancemedicine-190728142338-thumbnail.jpg?width=640&height=640&fit=bounds)























































