




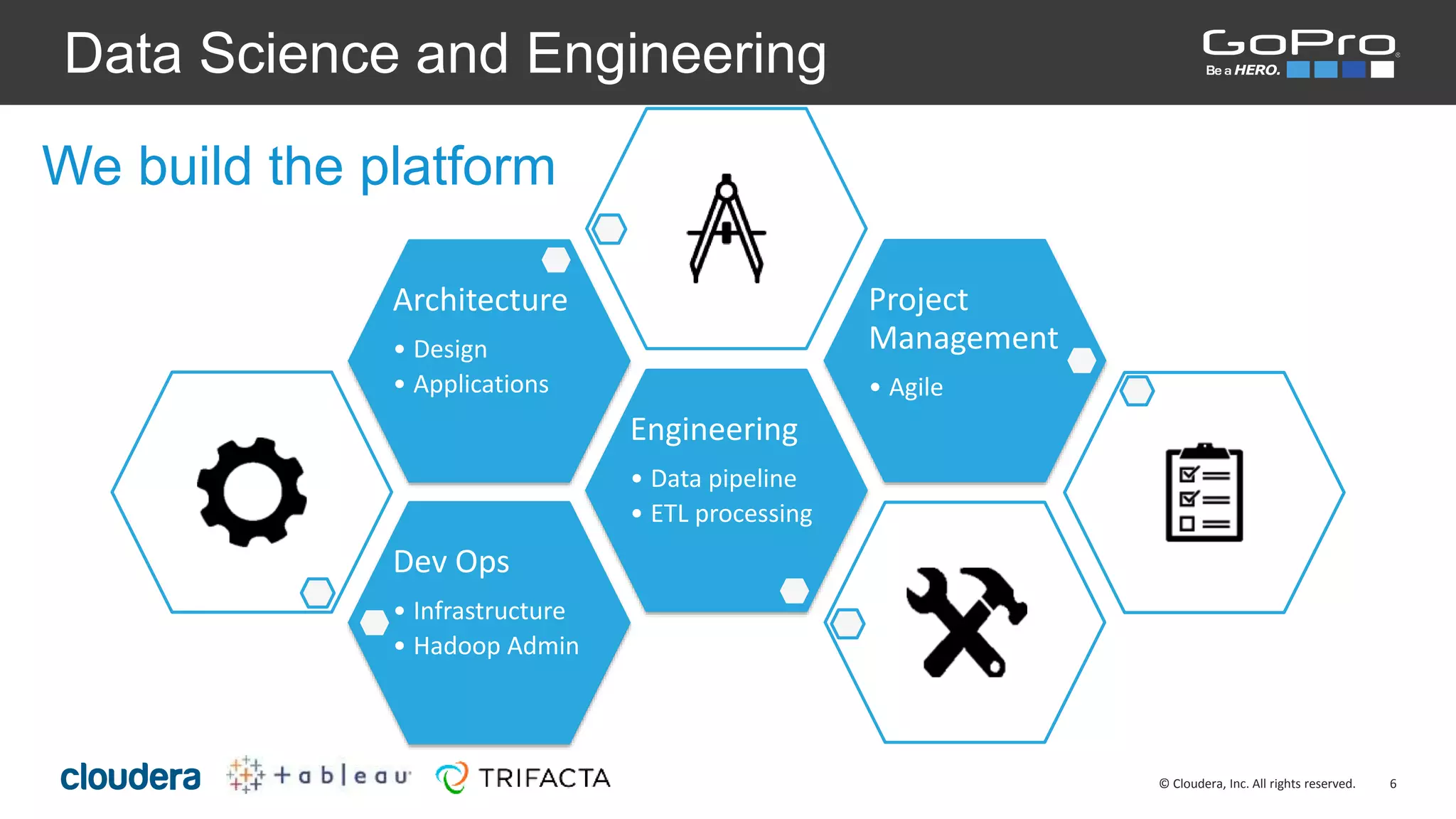


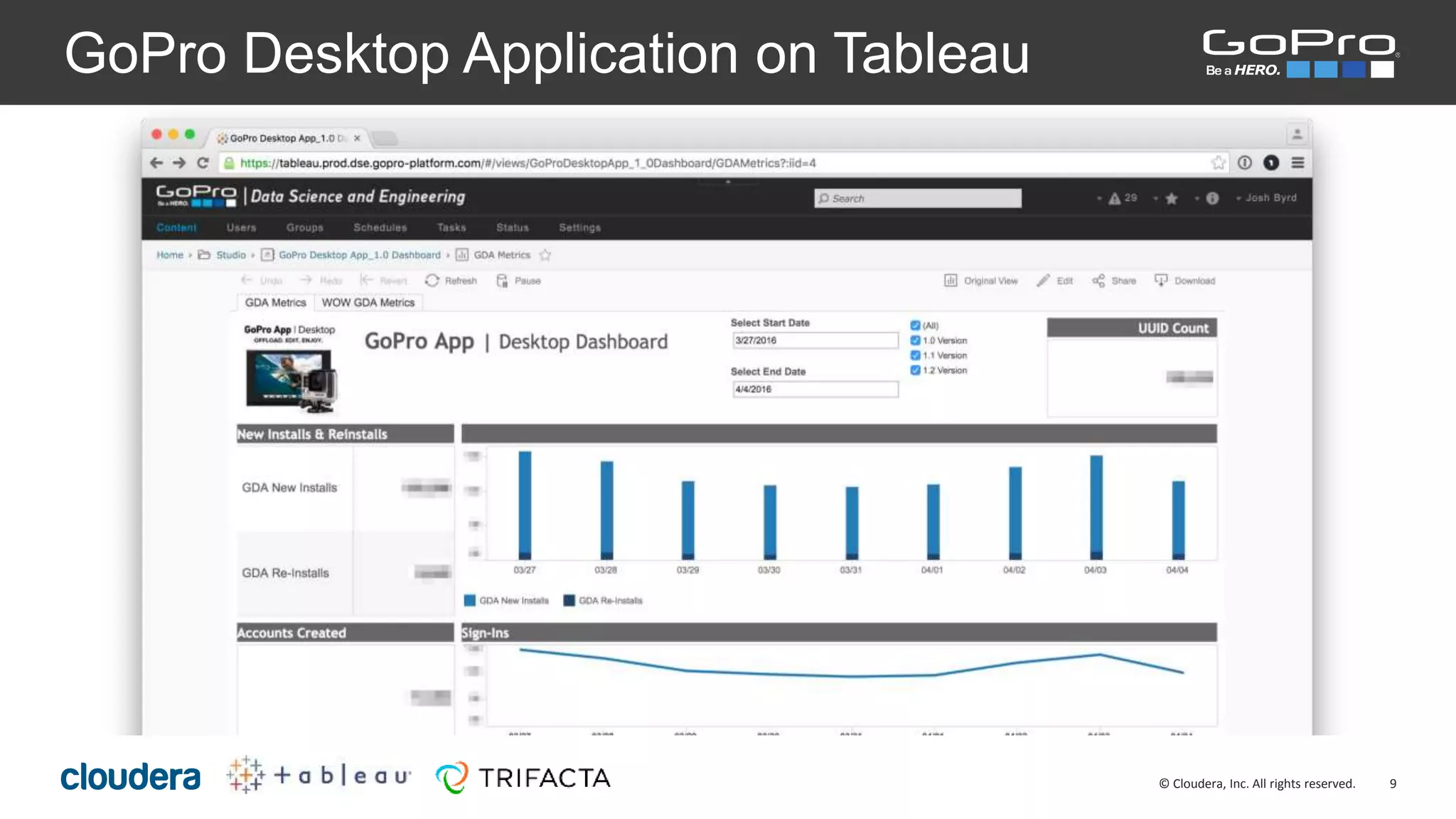

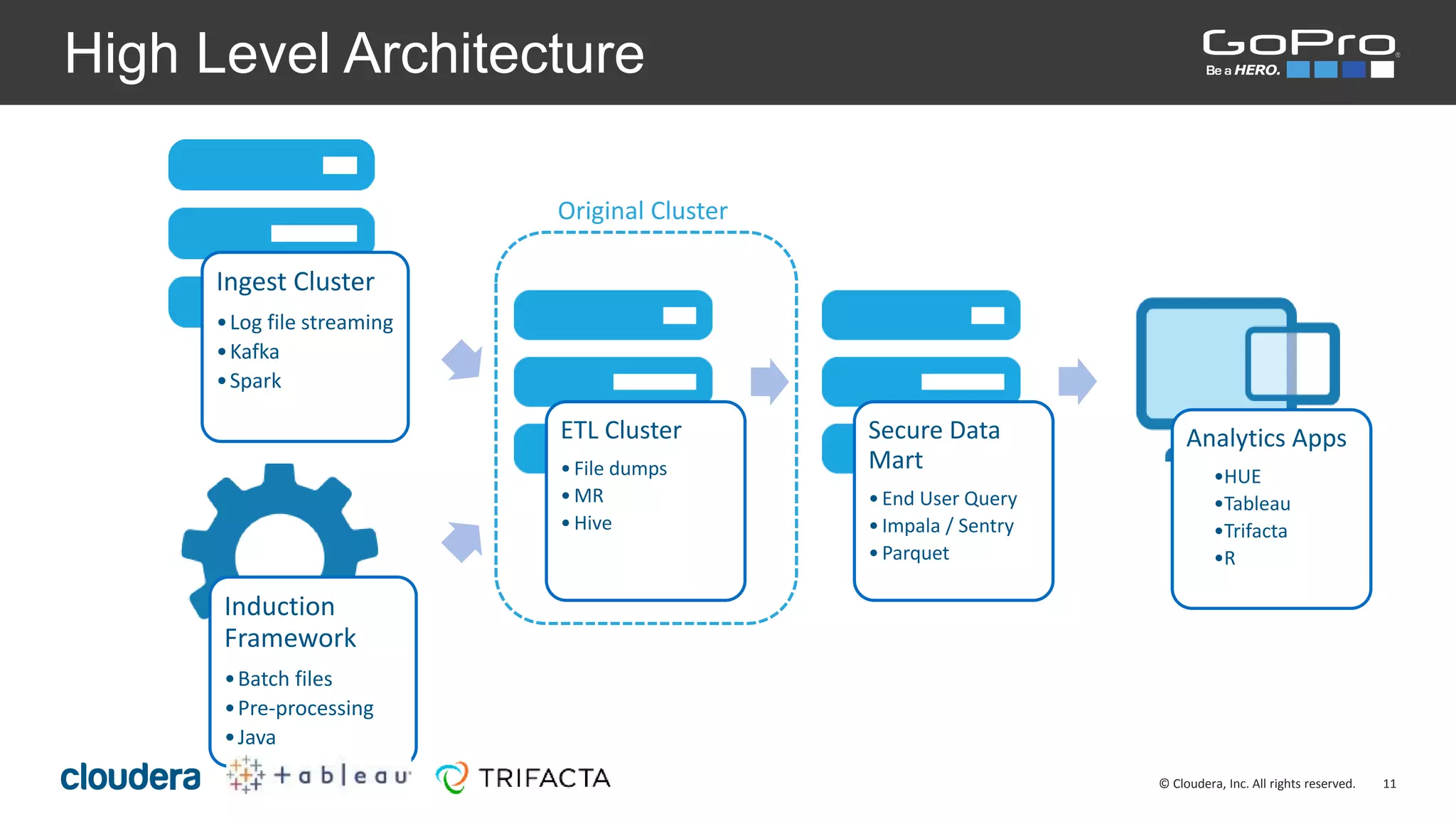
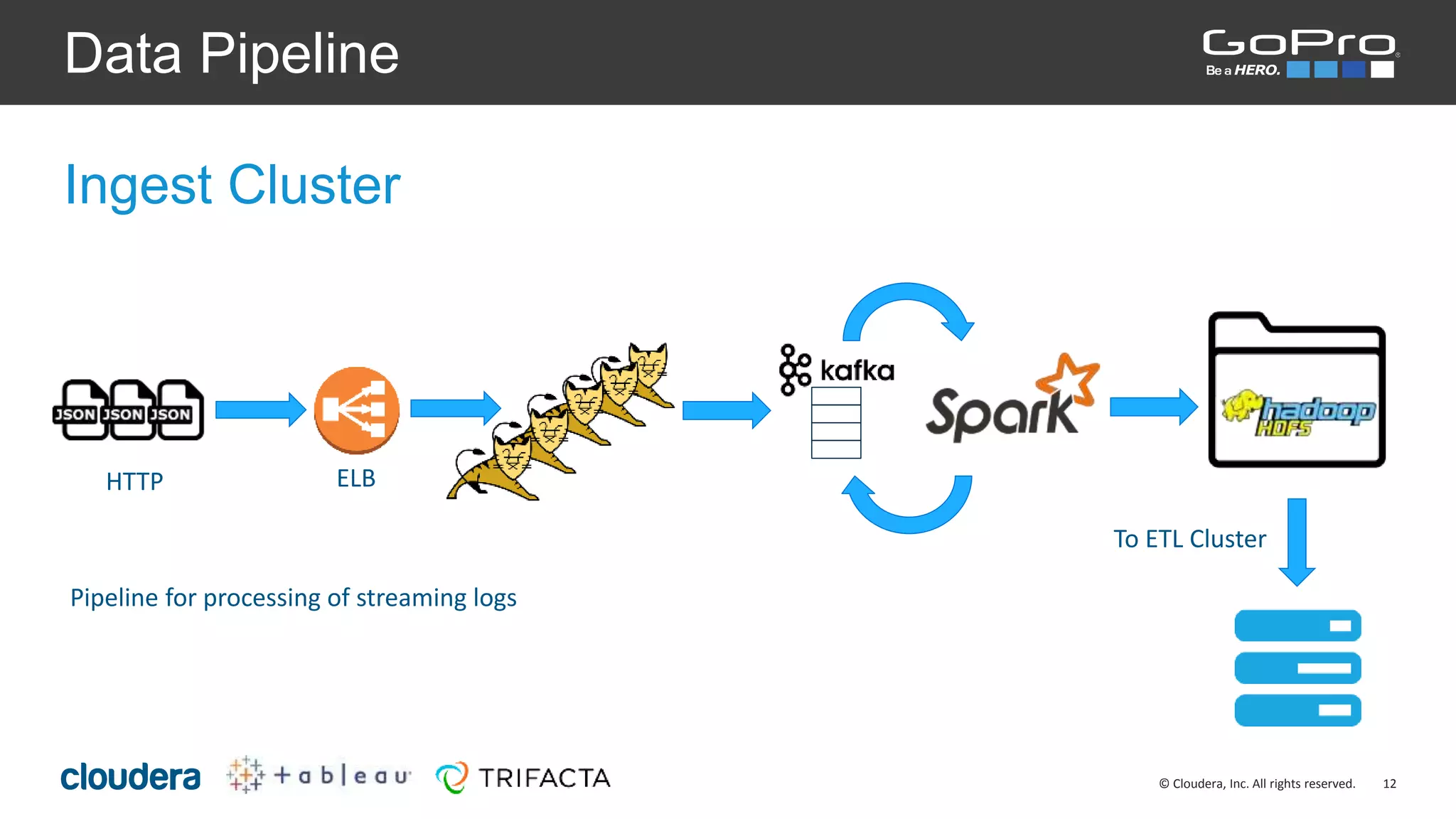
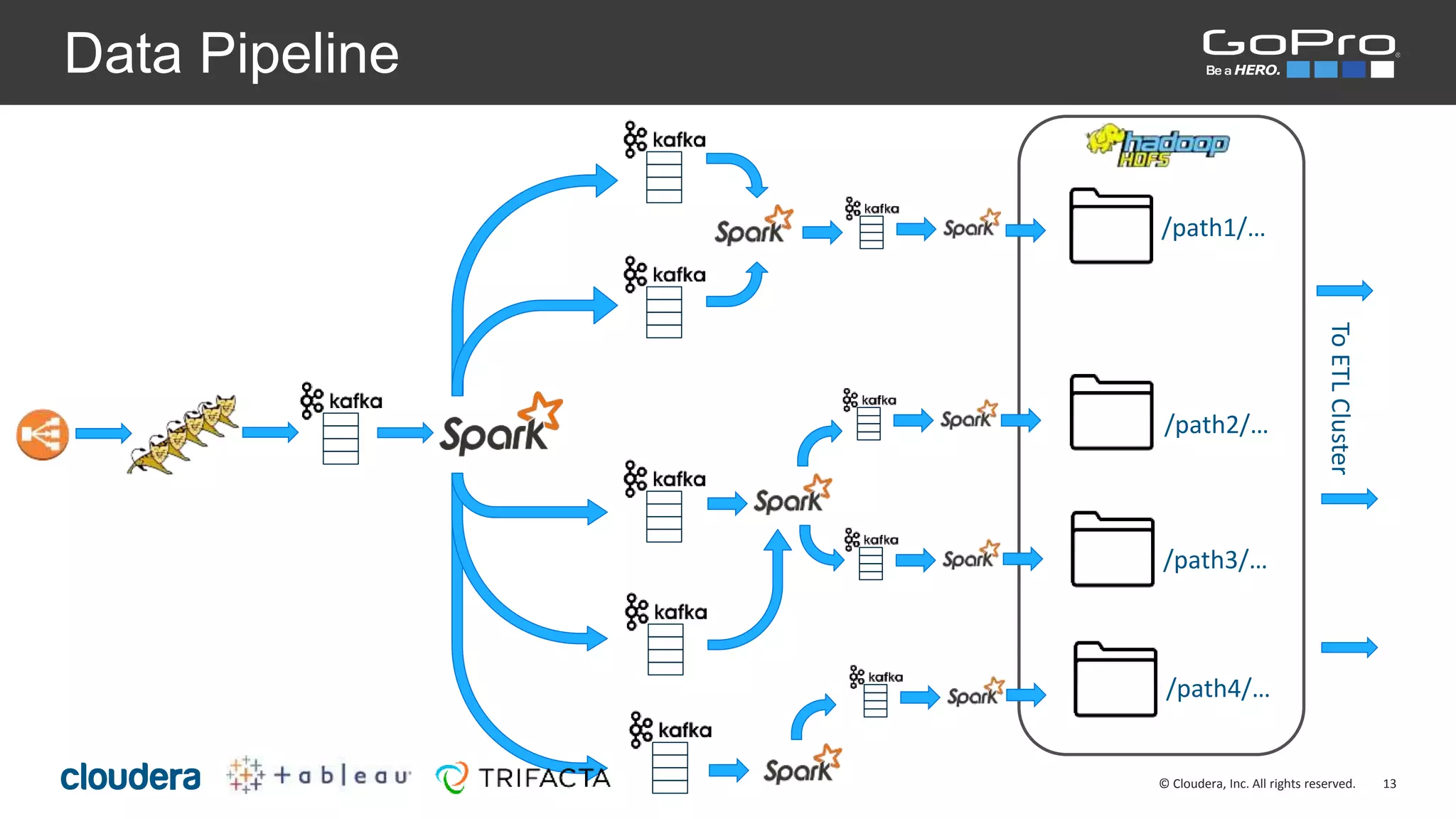
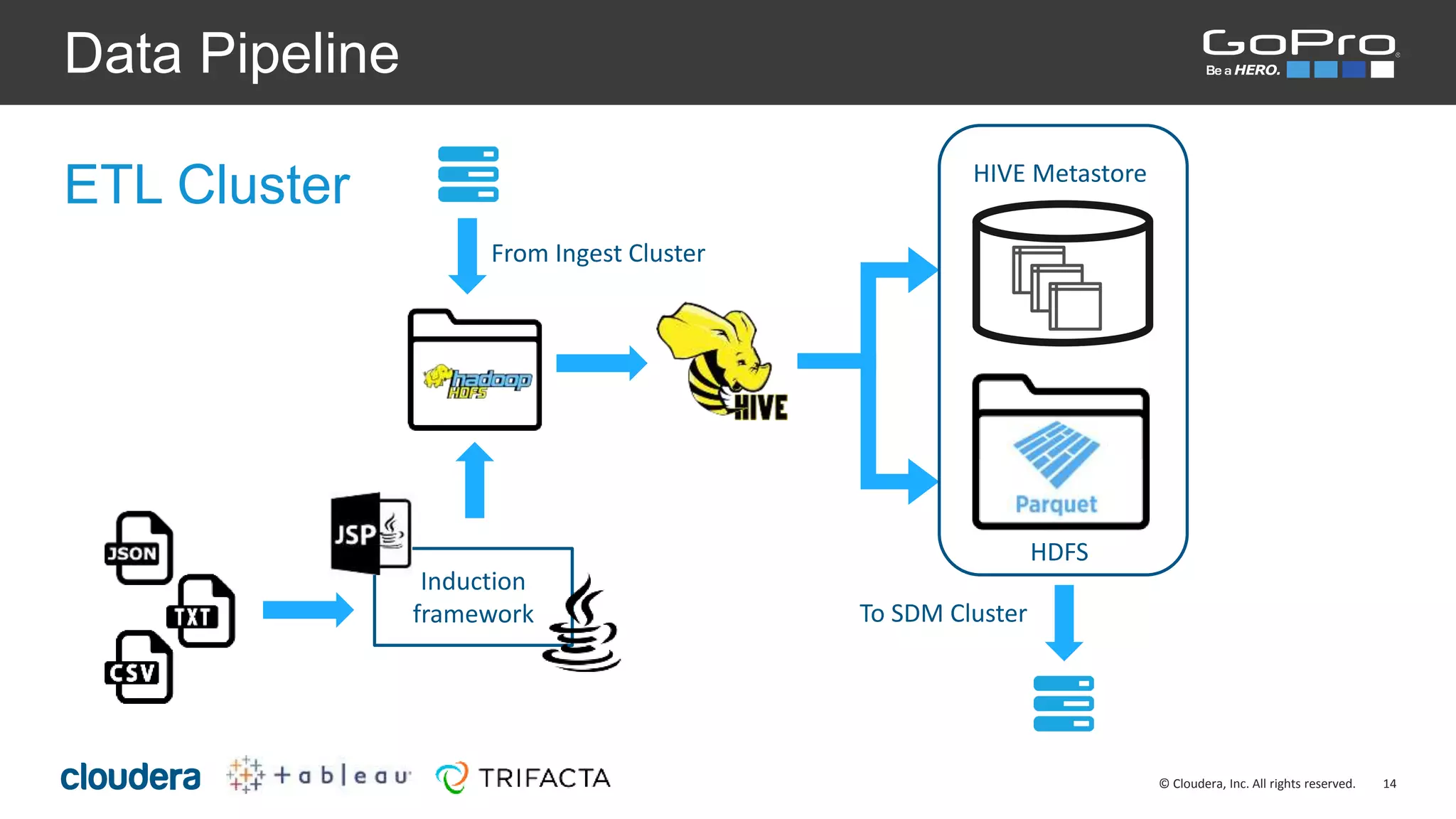
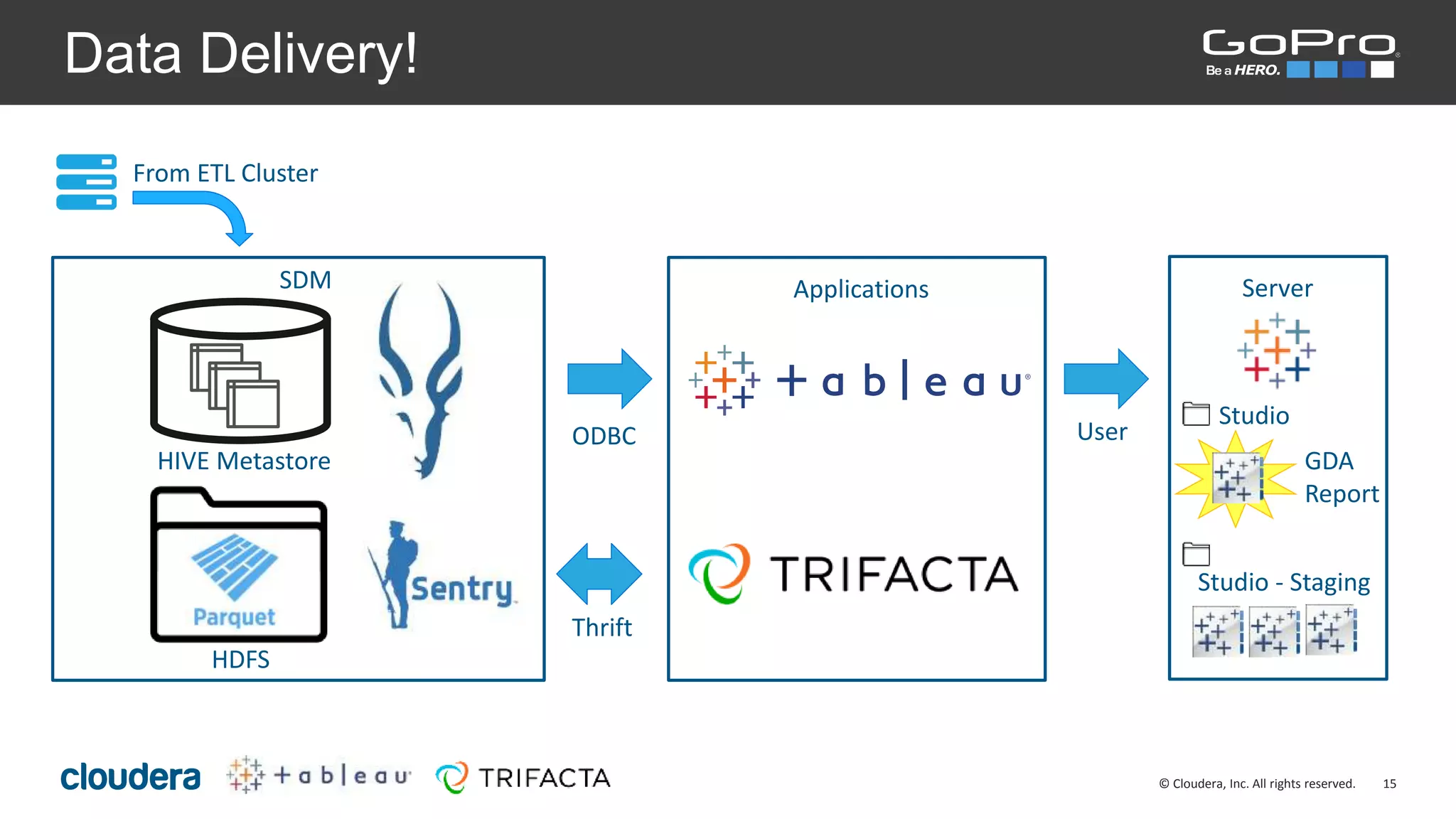

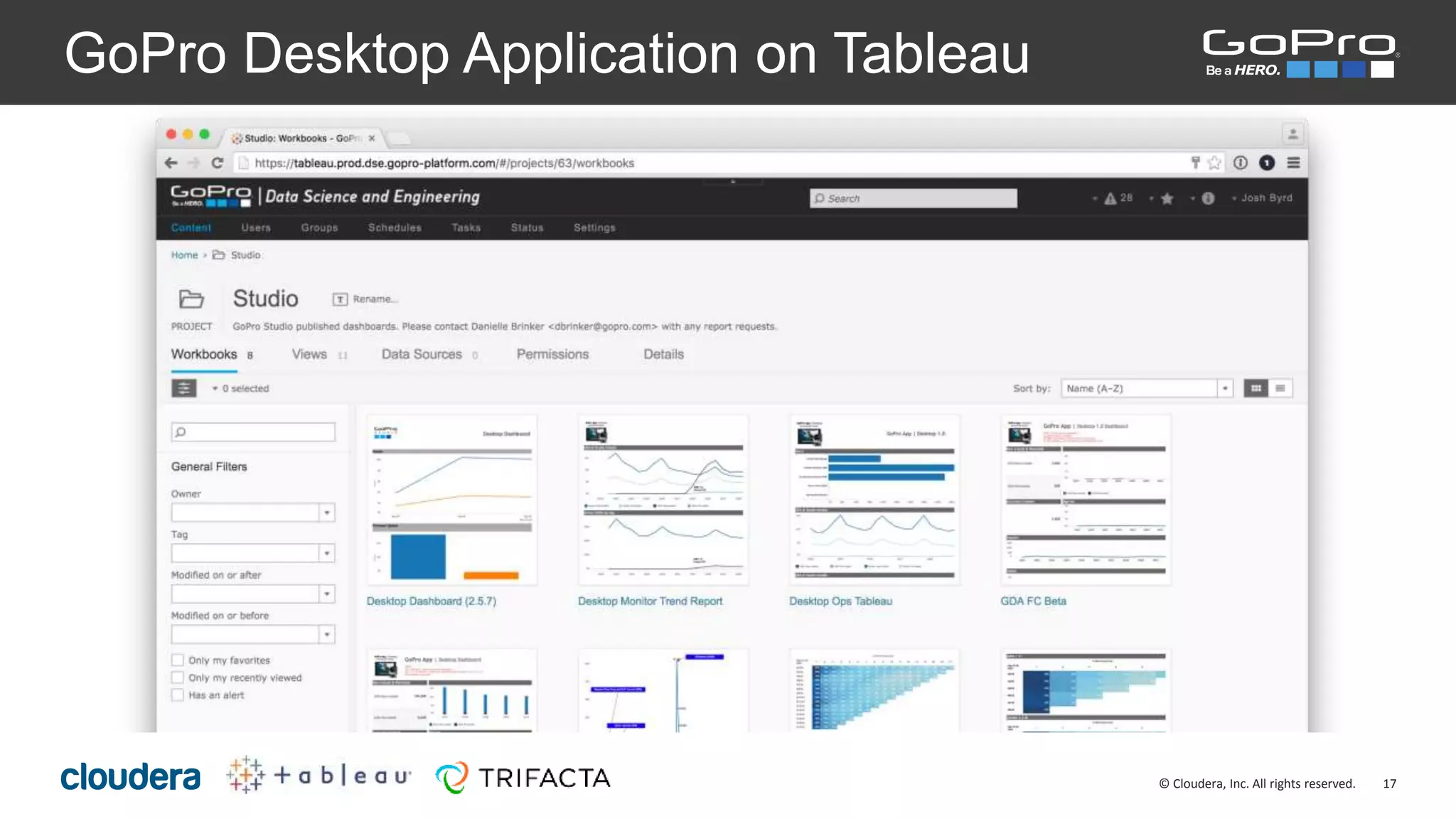




The document discusses the roles of Josh Byrd and David Winters at GoPro, focusing on their expertise in data architecture and engineering. It outlines GoPro's data processing needs and their infrastructure, including the use of tools like Spark and Kafka for real-time data ingestion and analysis. The document also highlights their commitment to quality and integrity in their data operations.























































































