The document presents an overview of the Viola-Jones algorithm, which is used for object detection, particularly in classifying diseases from X-ray images. It details the algorithm's four main stages: Haar feature selection, integral image creation, AdaBoost training, and cascading classifiers, along with implementation guidelines using Python and OpenCV. Results include accuracy statistics for various diseases, demonstrating the practical application of the algorithm in medical image processing.
![Extracting Features and Classification
of Diseases in X-Ray Images Using
[Viola-Jones Algorithm]
Medical Image Processing
Syed Ebraiz Ali Chishti
P177001@nu.edu.pk](https://image.slidesharecdn.com/extractfeaturespresentations-180523012932/85/Extract-Features-and-Classification-of-Diseases-from-X-Ray-Images-Using-Viola-Jones-Algorithm-1-320.jpg?cb=1743672568)















![05/23/18 19
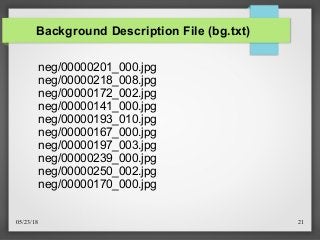
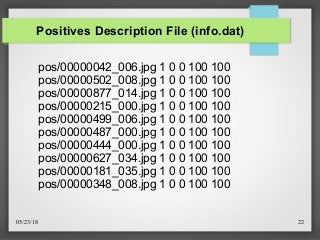
Code For Creating Description File
def create_pos_n_neg():
for file_type in ['neg','pos']:
for img in os.listdir(file_type):
if file_type == 'pos':
line = file_type+'/'+img+' 1 0 0 100 100n'
with open('info.dat','a') as f:
f.write(line)
elif file_type == 'neg':
line = file_type+'/'+img+'n'
with open('bg.txt','a') as f:
f.write(line)](https://image.slidesharecdn.com/extractfeaturespresentations-180523012932/85/Extract-Features-and-Classification-of-Diseases-from-X-Ray-Images-Using-Viola-Jones-Algorithm-19-320.jpg?cb=1743672568)

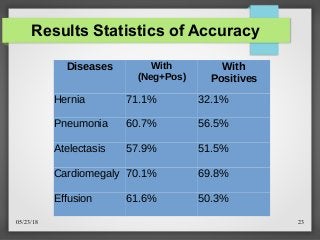
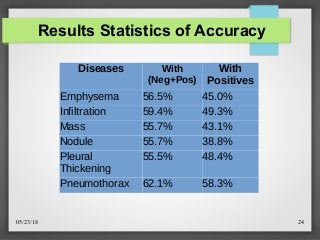
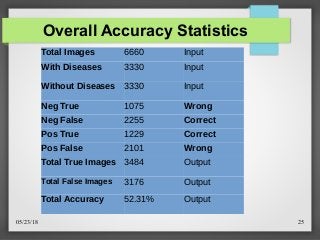
![05/23/18 26
References
Pythonprogramming.net. (2018). Python Programming Tutorials.
[online] Available at: https://pythonprogramming.net/haar-cascade-
object-detection-python-opencv-tutorial/ [Accessed 5 May 2018]
Docs.opencv.org (2018). Cascade Classifier Training — OpenCV
2.4.13.0 documentation [online] Available
at:https://docs.opencv.org/2.4.13/doc/user_guide/ug_traincascade.htm
l/ [Accessed 5 May 2018]
Youtube.com (2018). VIOLA JONES FACE DETECTION
EXPLAINED [online] Available at:https://www.youtube.com/watch?
v=_QZLbR67fUU/ [Accessed 22 May 2018]](https://image.slidesharecdn.com/extractfeaturespresentations-180523012932/85/Extract-Features-and-Classification-of-Diseases-from-X-Ray-Images-Using-Viola-Jones-Algorithm-26-320.jpg?cb=1743672568)












































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)



