Download to read offline









![WIKIPEDIA PAGES AS CONCEPTS
Solar System
“The Solar System[a] consists
of the Sun and the
astronomical objects
gravitationally bound in orbit
around it, all of which formed
from the collapse of a giant
molecular cloud
approximately 4.6 billion
years ago…”
(http://en.wikipedia.org/wiki/Solar
_System)
Word Stem
Occ. Freq.
abstract
53
0.056
program
44
0.046
langu
33
0.035
spec
16
0.017
comput
12
0.013
conceiv
12
0.013
dat
12
0.013
bk = p(Wi | k) =
{Wi Î k}
N
å {W Î k}
i
i
βk : Per-concept word distribution](https://image.slidesharecdn.com/win20134toslideshare-131214095143-phpapp02/85/Exploring-Content-with-Wikipedia-11-320.jpg)




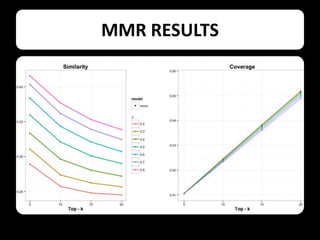
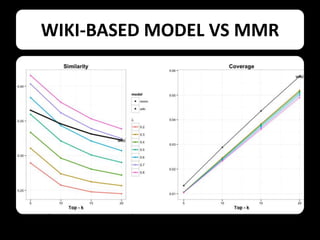


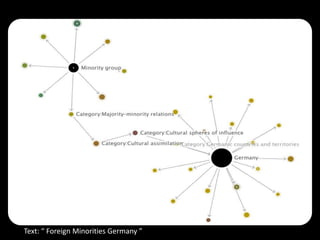
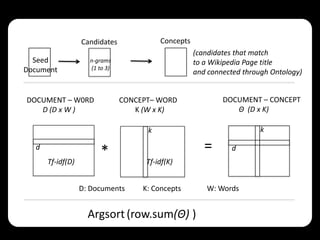
This document describes using collaborative knowledge bases like Wikipedia to support exploratory search tasks. It presents an approach that extracts concepts and their relationships from Wikipedia to build a concept network. Documents are then ranked based on their relationships to these concepts. An experiment ranks journal abstracts given a seed abstract, comparing the proposed Wikipedia-based approach to a maximal marginal relevance technique. The Wikipedia approach provided more diverse results while maintaining high relevance, showing potential for improving exploratory search.





































































