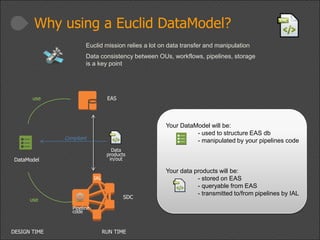
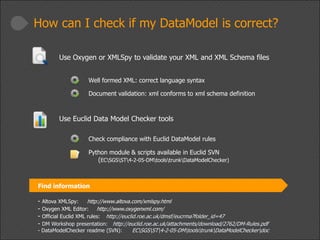
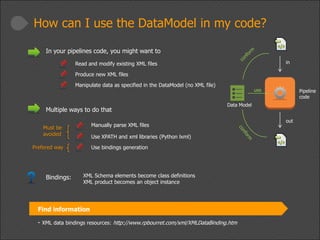
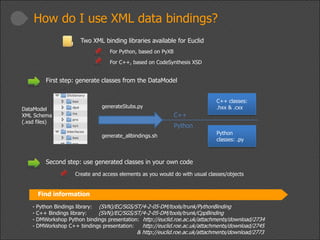
This document provides a high-level overview of the data modeling process for Euclid data modelers and developers, including available tools and resources. It outlines the importance of utilizing an XML-based data model, the structure and creation of data models, and best practices for coding with the data model. The presentation also emphasizes consistency and compliance with established Euclid XML rules and mentions upcoming episodes for deeper insights.