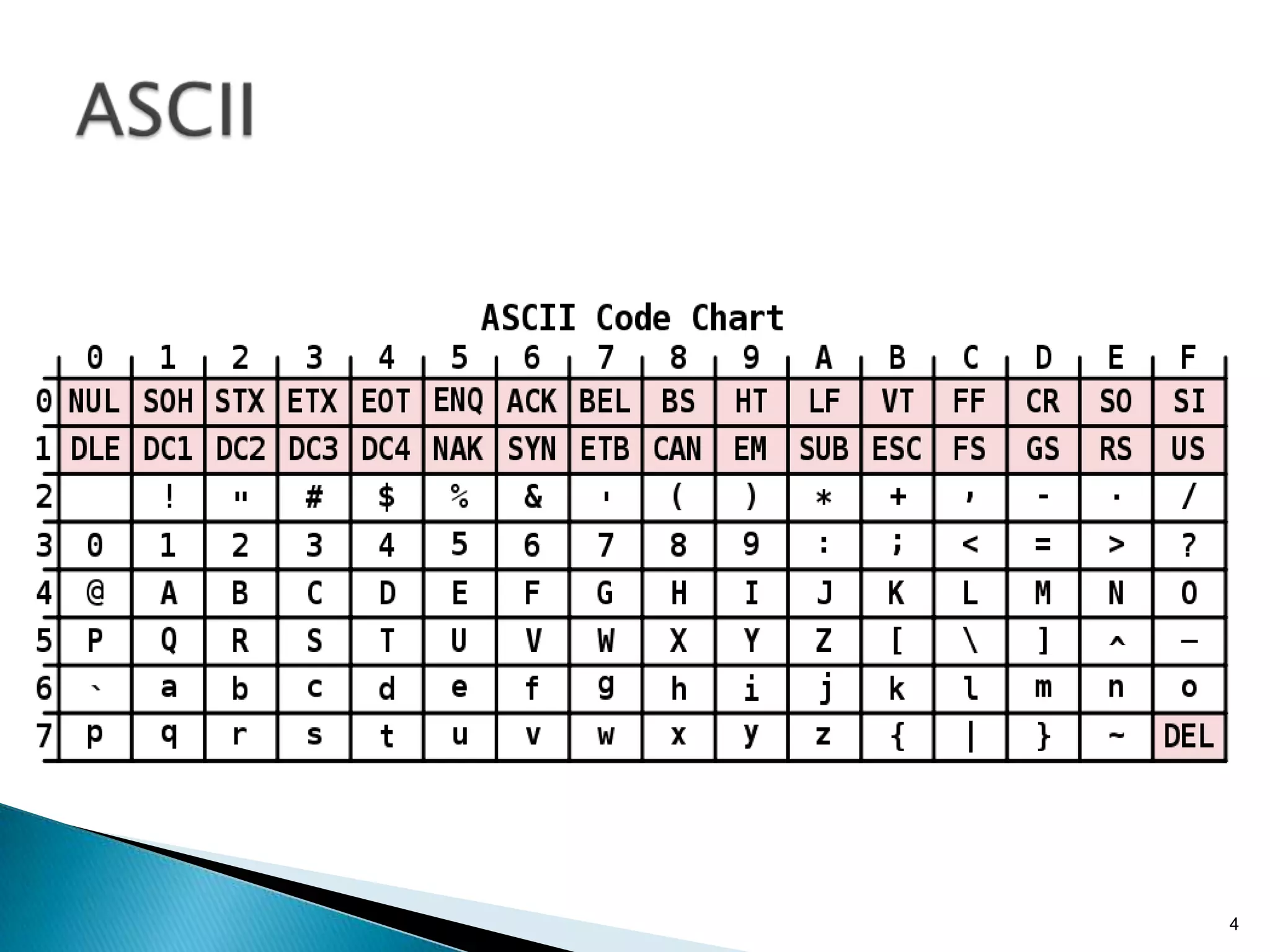
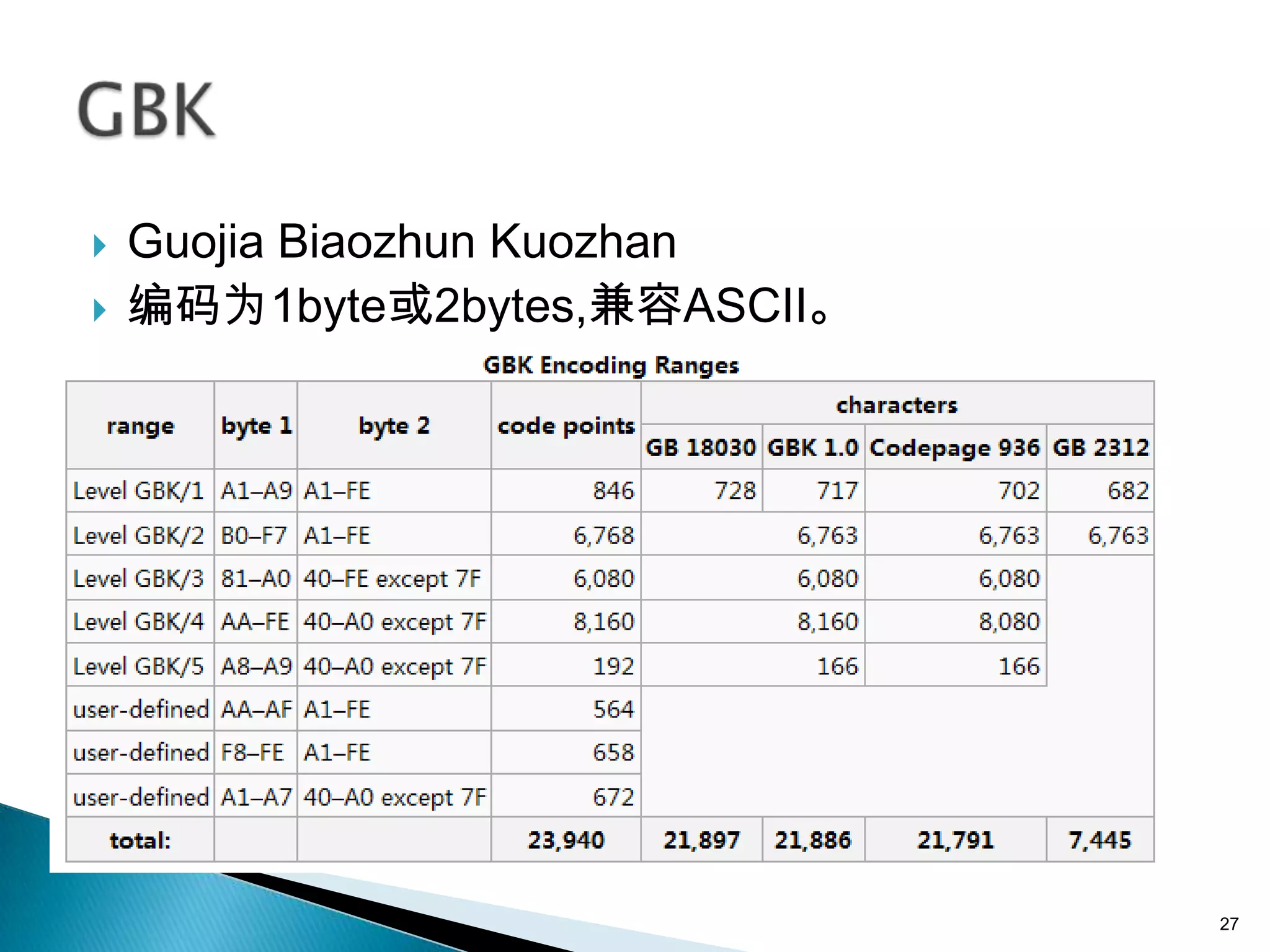
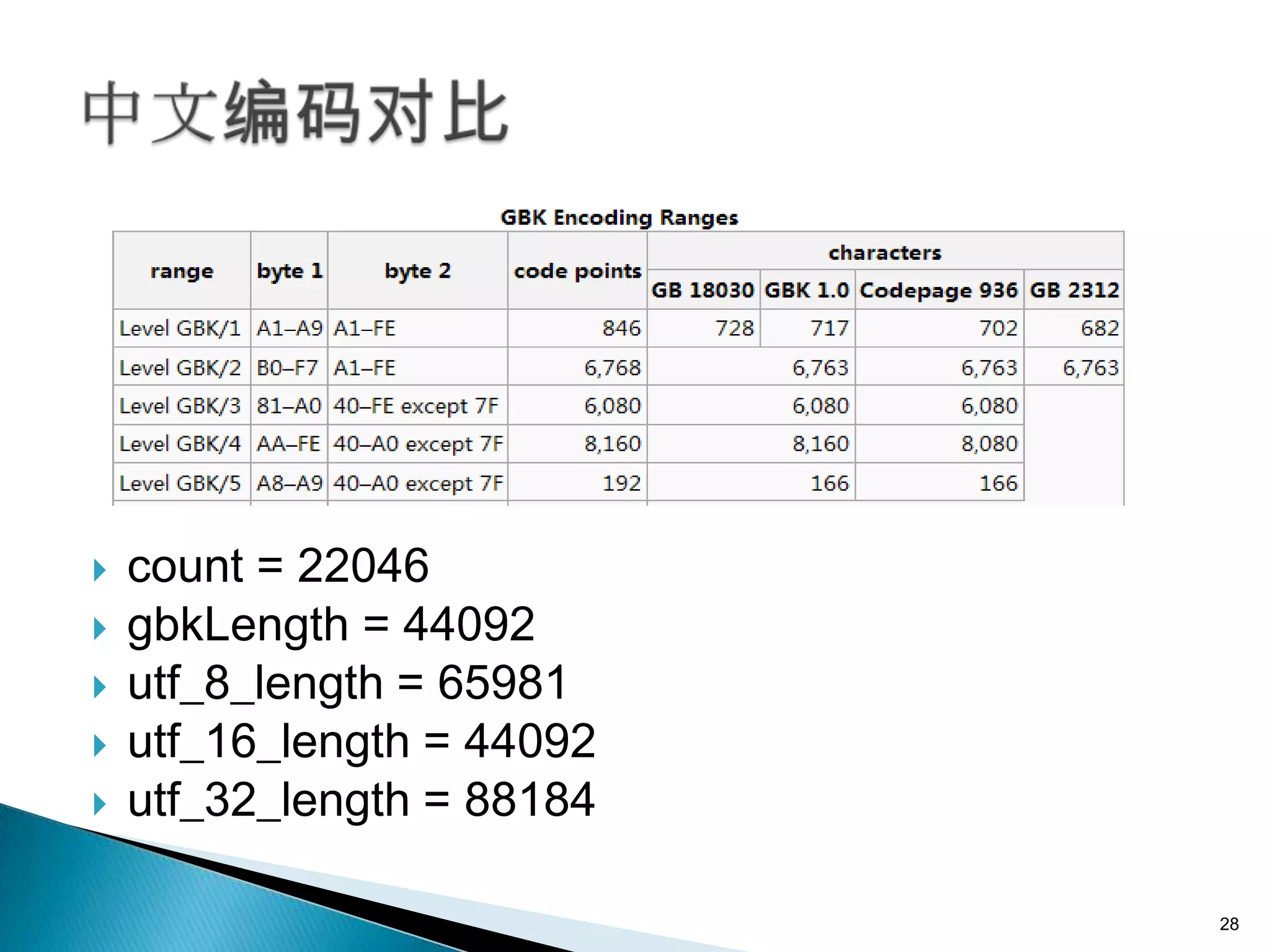
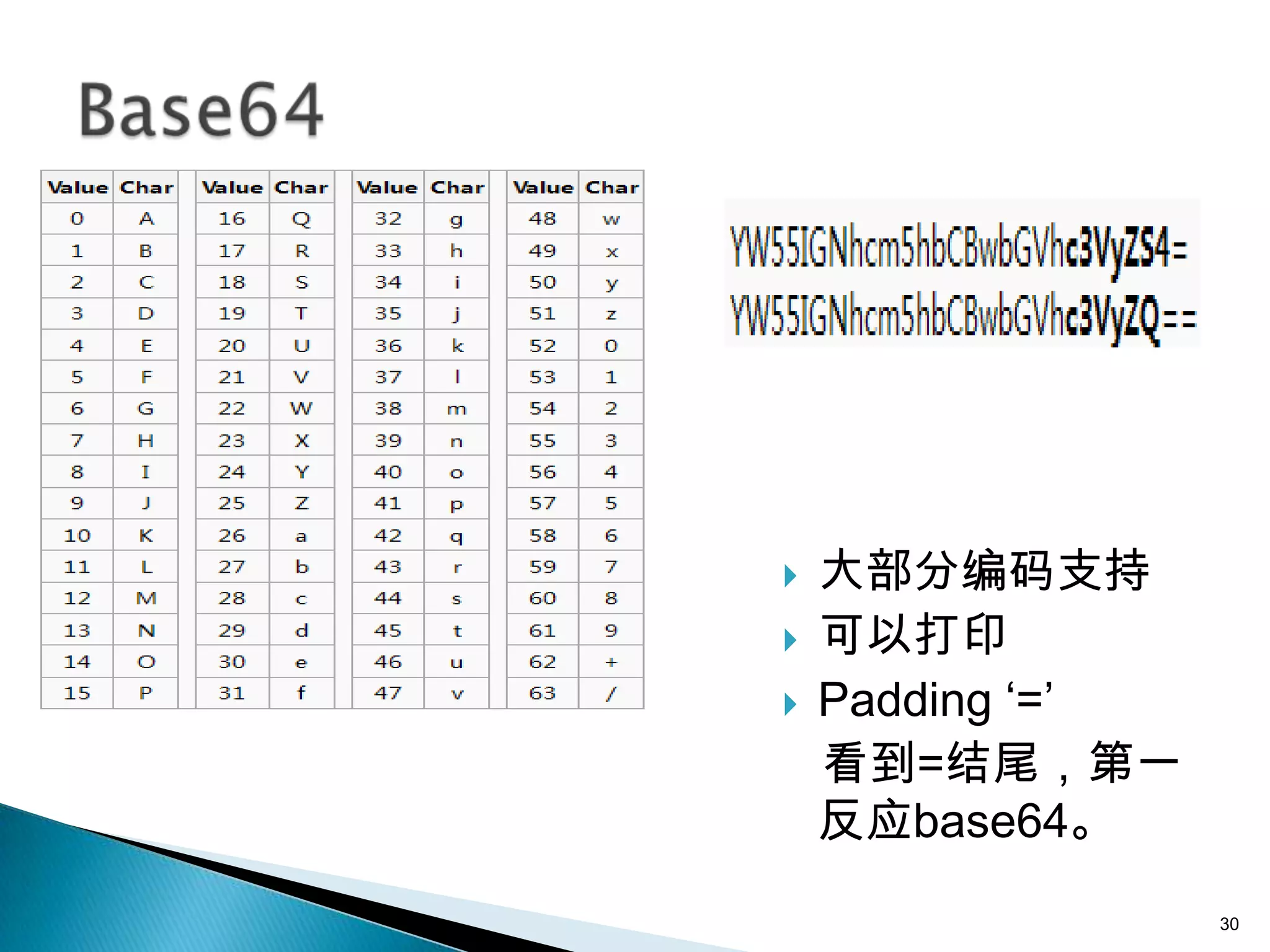
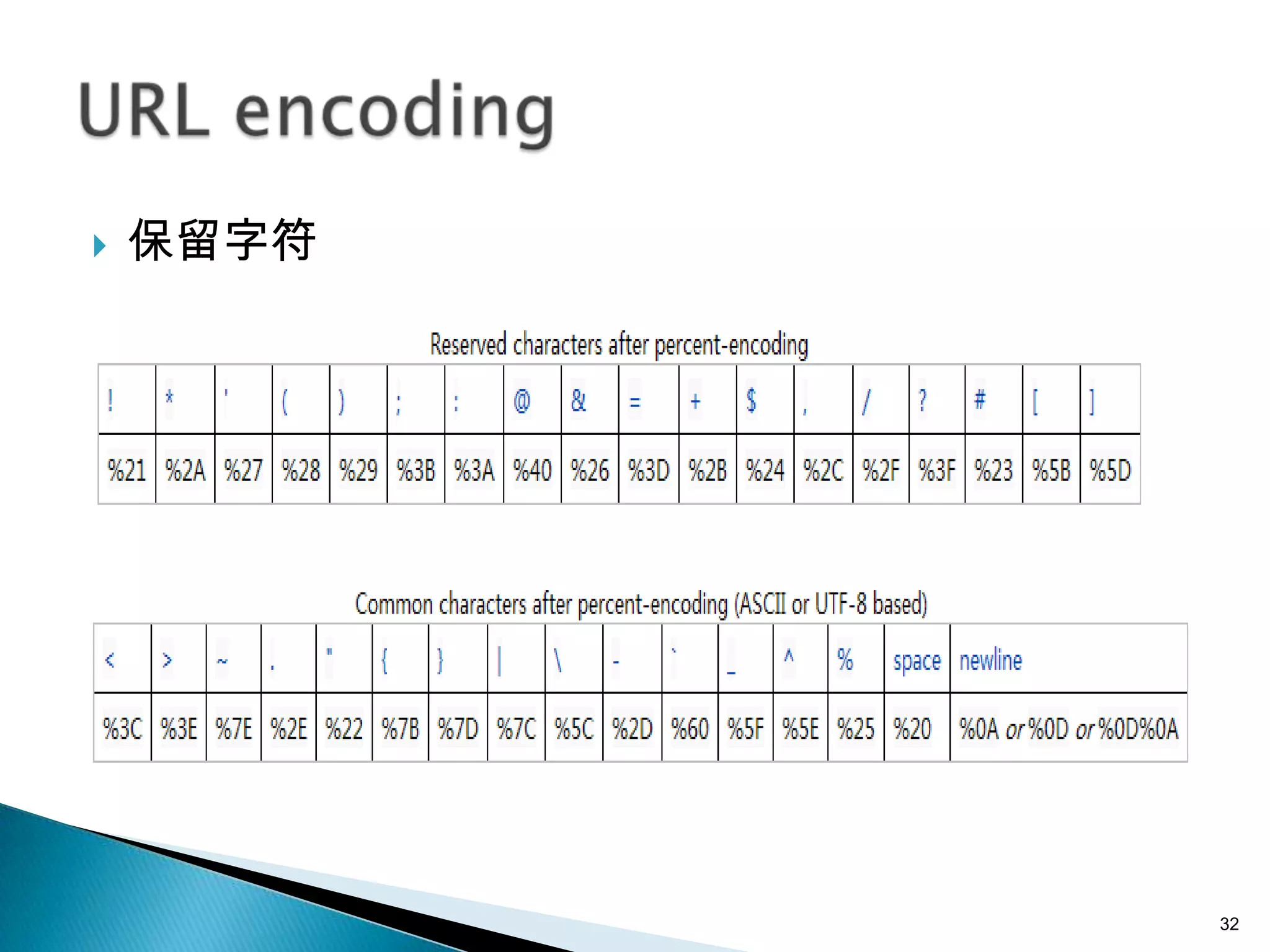
本文件讨论了字符编码的基本概念,包括ASCII、ISO-8859-1 和 Unicode 等不同编码标准及其特点。文件还深入探讨了字符串与字节之间的转换和编码兼容性问题,以及UTF-8、UTF-16等变长编码的实现方式和应用。通过示例说明了在处理多语言文本时的编码问题和最佳实践,强调了在字符串和字节转换时指定字符集的重要性。






![String -> Bytes -> String
encoding = US-ASCII
bytes[] =
61626364 // 16进制表示
97,98,99,100, // 无符号整型表示
oldString = abcd
newString = abcd
equals = true
String -> Bytes -> String
encoding = US-ASCII
bytes[] =
616263643F3F
97,98,99,100,63,63,
oldString = abcd信之
newString = abcd??
equals = false
ASCII无法存储中文,直接解释为63(???),一般看到???,很多是编码问题。](https://image.slidesharecdn.com/encoding-120211085702-phpapp01/75/Encoding-8-2048.jpg)



![String -> Bytes -> String
encoding = ISO-8859-1
bytes[] =
61626364
97,98,99,100,
oldString = abcd
newString = abcd
equals = true
String -> Bytes -> String
encoding = ISO-8859-1
bytes[] =
616263643F3F
97,98,99,100,63,63,
oldString = abcd信之
newString = abcd??
equals = false](https://image.slidesharecdn.com/encoding-120211085702-phpapp01/75/Encoding-12-2048.jpg)
![String -> Bytes -> String
encoding = ISO-8859-1
bytes[] =
B1
177,
oldString = ±
newString = ±
equals = true](https://image.slidesharecdn.com/encoding-120211085702-phpapp01/75/Encoding-13-2048.jpg)


![ Unicode defines a code space of 1,114,112 code
points in the range
0x000000 to 0x10FFFF.
划分为17个Unicode plane.
Plane 0:Basic Multilingual Plane (BMP)
0000-FFFF
Plane 1-16: Supplementary Planes
[1-10]0000 – [1-10]FFFF
不是所有的bit排列都是有效代码点,有些Plane(p3-p13)
目前未分配代码点。
Supplementary Planes 一般程序测试的不充分,尽量
避免使用。其实一般也难以用到。^_^ (ascii art)](https://image.slidesharecdn.com/encoding-120211085702-phpapp01/75/Encoding-16-2048.jpg)



![ String -> Bytes -> String
encoding = UTF-16BE
bytes[] =
0061006200630064
0,97,0,98,0,99,0,100,
oldString = abcd
newString = abcd
equals = true
String -> Bytes -> String
encoding = UTF-16LE
bytes[] =
6100620063006400
97,0,98,0,99,0,100,0,
oldString = abcd
newString = abcd
equals = true](https://image.slidesharecdn.com/encoding-120211085702-phpapp01/75/Encoding-20-2048.jpg)
![String -> Bytes -> String
encoding = UTF-16BE
bytes[] =
00610062006300644FE14E4B
0,97,0,98,0,99,0,100,79,225,78,75,
oldString = abcd信之
newString = abcd信之
equals = true
21](https://image.slidesharecdn.com/encoding-120211085702-phpapp01/75/Encoding-21-2048.jpg)





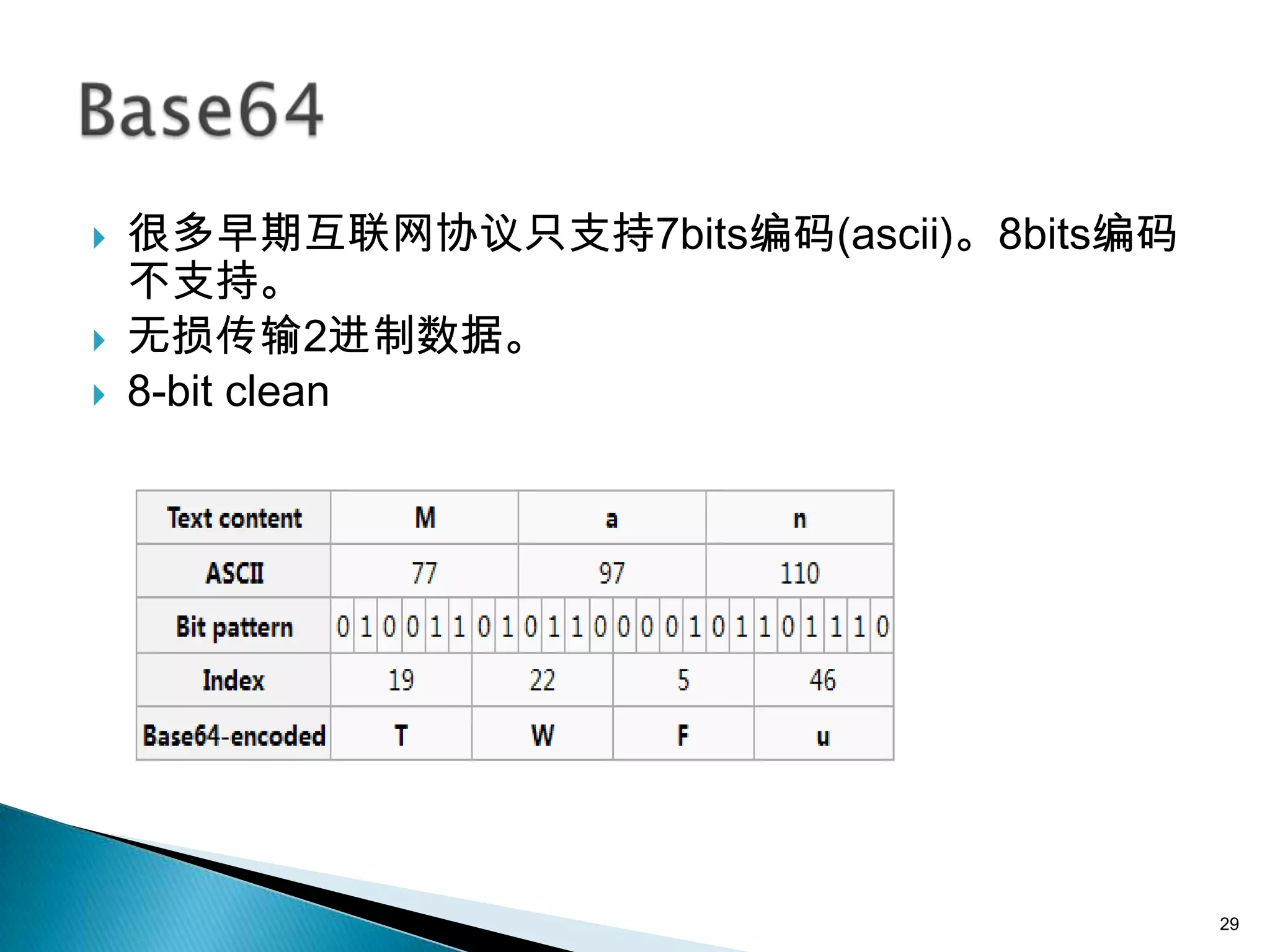


![ 所有涉及字符串和bytes互转的地方,指定charset,
以增强可移植性。
public String(byte bytes[])
public byte[] getBytes()
如果不指定,则使用默认编码集,这个对于可移植性
是个坑。
Charset.defaultCharset().name();
34](https://image.slidesharecdn.com/encoding-120211085702-phpapp01/75/Encoding-34-2048.jpg)











































![[圣思园][Java SE]Io 3](https://cdn.slidesharecdn.com/ss_thumbnails/io3-110811050226-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


