- E-commerce BigData Scale AI Journey
- BigData Scale Deep Learning Production System Use Case
- Deep Learning, Cloud PaaS, Microservices, DevOps, etc.
- E-Commerce AI Production System Strategy
I am …
•김훈동 Chief Partner
• 신세계 그룹 온라인 포털 SSG.COM BigData&AI Part Leader
• 스사모(Korea Spark User Group) 운영진
• BigData 분야 Microsoft MVP(Most Valuable Professional) 선정
2016년, 2017년
• AI 분야 Microsoft MVP(Most Valuable Professional) 선정
2018년
• http://hoondongkim.blogspot.kr
• https://www.facebook.com/kim.hoondong
과거 2015년 –prologue (서막)
• 튜링테스트 ( 인간 vs AI )
이미지 인식
정확도
9.
이미지인식 Deep Learning기술
- 유통에의 적용은? ( By Amazon )
• 뒤죽박죽처럼 보이는 사진 속 물건들은 아마존의 알고리즘에 의해 정교하게 배치된
것으로, 디지털 스캐너가 배치된 물건들을 정확하게 찾아준다.
창고에는
팔래토 상품만 저장?
Long Tail 상품들은?
10.
과거 2016년,2017년 -prologue (서막)
- AlphaGo & 엑소브레인
• 튜링테스트 ( 인간 vs AI )
• 다양한 분야에서 인간을 이기기 시작하면서 산업계가 주목하기 시작.
바둑
이세돌 9단 vs 알파고(구글)
1 : 4
장학퀴즈
vs 엑소브레인(ETRI 국산 AI)
350 : 510
시즌1 우승자,
시즌2 우승자,
수능시험 만점자,
두뇌게임 프로그램 우승자
11.
원순환 반응 ReinforcementLearning 기술
- 유통에의 적용은? (By Alibaba & Taobao)
• 개인화된 즉각적 반응으로 검색 페이지의 랭킹을 실시간으로…
• By Alibaba & Taobao
• https://arxiv.org/abs/1803.00710
실시간성…
개인화…
Training & Serving 이 동시에…
12.
현재 - 2018년9월 11일 현재.
AI vs 인간 대결에 대한 가설!
• 인간이 지지 않던 시절 = 인류가 태어나고 2016년 까지.
• 인간이 지기 시작하는 시절 = 2016년~2020년(or 2022년?)
• 인간이 항상 지는 시절 = 2020년? 2025년? (시간 문제…)
[전제] AI가 인간의 모든 분야를 앞도 할 순 없다. 즉, 특정 분야에만 해당!
[사실] But,인간보다 AI가 잘 하는 분야가 점점 많아질 것이며,
[직시] 해당 분야가 곧 위기 이며, 기회인 시점이 다가오고 있음.
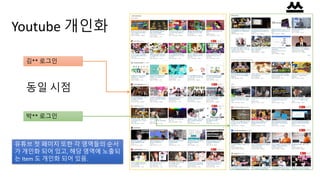
Google Did!
• 구글년도 별 주요 발표 내용
년도 Google 발표 기술 OpenSource 진영 기술
2003년 GFS Hadoop HDFS
2004년 MapReduce Hadoop MapReduce
2006년 Chubby Zookeeper
2006년 BigTable HBase
2010년 Pregel Neo4J, Spark Graph-X
2010년 Dremel Spark
2011년 Tenzing Hive, Spark SQL
2012년 Spanner, F1 RDB Sharding + Kafka + Redis : RDB 분산 Scale Out 및 동기화
시스템
2013년 Omega Docker(Mesos)
2014년 Word2Vec , DataFlow 외 다수 Word2Vec (NLP 요소 기술) , Beam 외 다수
2015년 Tensorflow , Borg 외 다수 Tensorflow (Deep Learning Framework), kubernetes 외 다수
2016년 AlphaGo, DeepQN, WaveNet 외 다수 복합문제를 해결하는 다수의 Deep Learning 방법론
2017년 ~ PathNet, Transformer 외 다수
Istio, knative , spinnaker 외 다수
Deep Learning 학습의 진화, 보다 고차원의 방법 외 다수
AI serving 에서 다시 주목 받는 K8S 의 Ecosystem 들…
BigData 기술
NoSQL 기술
분산 RDB 기술
MicroService &
DevOps &
Container&
Data Workflow 기술
Deep Learning &
AI 기술 & K8S
Ecosystems
Deep Learning 기술 이전에 BigData,
NoSQL, MicroService 등에 대한 Core 기
술 기반을 먼저 갖추었음.
20.
AI 시대의 발현!
1.BigData 기술 등장 (2003~2010년대)
2. NoSQL 기술 등장 (2007~2013년대)
3. Container & Microservice 기술 등장
(2014년대~)
4. Deep Learning 고도화 기술 등장
(2015년대~)
그리고…
5. 위 기술들의 융합
진화의 시작!
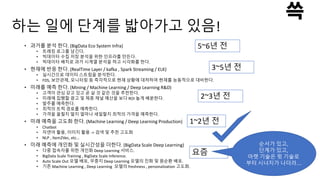
하는 일에 단계를밟아가고 있음!
• 과거를 분석 한다. (BigData Eco System Infra)
• 트래킹 로그를 남긴다.
• 빅데이타 수집 저장 분석을 위한 인프라를 만든다.
• 빅데이타 배치로 과거 시계열 분석을 하고 시각화를 한다.
• 현재에 반응 한다. (RealTime Layer / kafka , Spark Streaming / ELK)
• 실시간으로 데이터 스트림을 분석한다.
• FDS, 보안관제, 모니터링 등 즉각적으로 현재 상황에 대처하여 현재를 능동적으로 대비한다.
• 미래를 예측 한다. (Mining / Machine Learning / Deep Learning R&D)
• 고객이 관심 갖고 있고 곧 살 것 같은 것을 추천한다.
• 미래에 집행할 광고 및 제휴 채널 예산을 보다 ROI 높게 배분한다.
• 발주를 예측한다.
• 최적의 트럭 경로를 예측한다.
• 가격을 올릴지 말지 얼마나 세일할지 최적의 가격을 예측한다.
• 미래 예측을 고도화 한다. (Machine Learning / Deep Learning Production)
• Chatbot
• 자연어 활용, 이미지 활용 -> 검색 및 추천 고도화
• NLP , Item2Vec, etc…
• 미래 예측에 개인화 및 실시간성을 더한다. (BigData Scale Deep Learning)
• 다중 접속자를 위한 개인화 Deep Learning 서비스.
• BigData Scale Training , BigData Scale Inference.
• Auto Scale Out 모델 배포, 무중지 Deep Learning 모델의 진화 및 원순환 배포.
• 기존 Machine Learning , Deep Learning 모델의 freshness , personalization 고도화.
5~6년 전
3~5년 전
1~2년 전
2~3년 전
요즘
순서가 있고,
단계가 있고,
아랫 기술은 윗 기술로
부터 시너지가 나더라….
24.
Production A/B Test에서 중요한 것!
Sample Data, Selected
Feature 정교한 모델
주1회 or 일1회
모두에게 적용하는 정교
한 단일 모델
최고 정확도
VS
더 많은 Data(or 전수 Data)
에 적용하는 Simple 모델
최신성
(매 시간 or 준실시간)
개인화 모델
덜 정확해도 빠르고,
다수에게, 실시간으로…
논문 쓸 때랑, Kaggle 할 때와 달라요!
25.
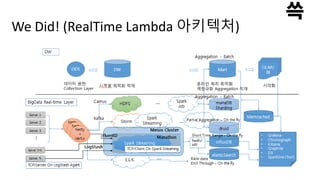
리얼타임 추천(원순환구조) +리얼타임 분석 By Netflix
Lambda Architecture
왜 Netflix 는 100만 달러 Competition 에서 우승한 알
고리즘을 사용하지 않는가?
26.
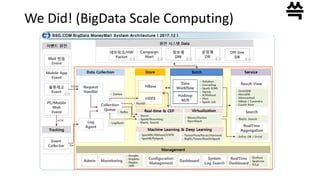
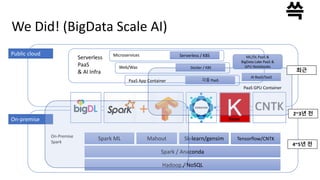
We Did! (BigDataScale AI)
Public cloud
Hadoop / NoSQL
Spark / Anaconda
Spark ML Mahout Sk-learn/gensim Tensorflow/CNTK
TensorflowOnSpark
Keras
On-Premise
Spark
On-premise
Serverless / K8SServerless
PaaS
& AI Infra
Microservices
Web/Was Docker / K8S
각종 PaaS
AI BaaS/SaaS
PaaS App Container
PaaS GPU Container
ML/DL PaaS &
BigData Lake PaaS &
GPU Notebooks
4~5년 전
2~3년 전
최근
27.
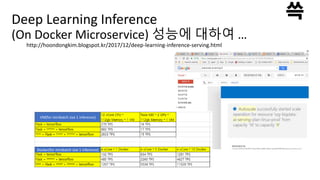
Deep Learning Inference
(OnDocker Microservice) 성능에 대하여 …
http://hoondongkim.blogspot.kr/2017/12/deep-learning-inference-serving.html
VM(for minibatch size 1 inference)
Docker(for minibatch size 1 inference)
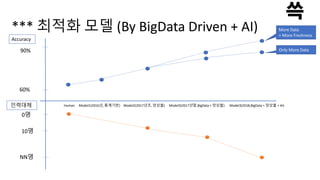
*** 최적화 모델(By BigData Driven + AI)
Human Model1(2016년, 통계기반) Model2(2017년초, 앙상블) Model3(2017년말,BigData + 앙상블) Model3(2018,BigData + 앙상블 + AI)
Accuracy
60%
90%
인력대체
NN명
0명
10명
More Data
+ More Freshness
Only More Data
32.
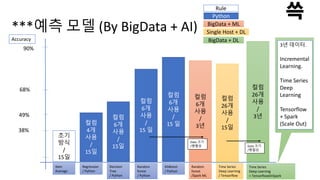
***예측 모델 (ByBigData + AI)
Item
Average
Accuracy
68%
90%
49%
38%
Regression
/ Python
Decision
Tree
/ Python
초기
방식
/
15일
컬럼
4개
사용
/
15일
컬럼
6개
사용
/
15일
Random
forest
/ Python
컬럼
6개
사용
/
15 일
Time Series
Deep Learning
+ TensorflowOnSpark
컬럼
26개
사용
/
3년
Random
forest
/Spark ML
컬럼
6개
사용
/
3년
Rule
Python
BigData + ML
XGBoost
/ Python
컬럼
6개
사용
/
15 일
3년 데이터.
Incremental
Learning.
Time Series
Deep
Learning
Tensorflow
+ Spark
(Scale Out)
Single Host + DL
BigData + DL
컬럼
26개
사용
/
15일
Time Series
Deep Learning
/ Tensorlfow
Data 크기
/병렬성 Data 크기
/병렬성
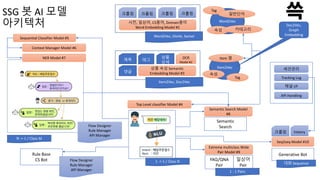
SSG 봇 AI모델
아키텍처
Top Level classifier Model #4
Sequential Classifier Model #5
사전, 일상어, CS용어, Domain용어
Word Embedding Model #1
크롤링 크롤링 크롤링 크롤링
1 -> 1 / Class N
Context Manager Model #6
NER Model #7
Word2Vec, GloVe, Swivel
Flow Designer
Rule Manager
API Manager
세션관리
Tracking Log
채널 I/F
API Handling
상품 속성 Semantic
Embedding Model #3
제목 태그
상품
상세
OCR
Model #2
댓글
Item2Vec, Doc2Vec
Item2Vec
Word2Vec
속성 카테고리
Tag
Item 명
속성
Tag
일반단어
N -> 1 / Class M
Semantic
Search
Rule Base
CS Bot FAQ/QNA
Pair
Generative Bot
Flow Designer
Rule Manager
API Manager
일상어
Pair
Extreme multiclass Wide
Pair Model #9
Semantic Search Model
#8
Seq2seq Model #10
크롤링 history
대화 Sequence
1 : 1 Pairs
Doc2Vec,
Graph
Embedding
37.
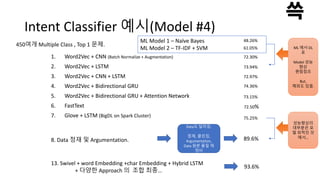
Intent Classifier 예시(Model#4)
1. Word2Vec + CNN (Batch Normalize + Augmentation)
2. Word2Vec + LSTM
3. Word2Vec + CNN + LSTM
4. Word2Vec + Bidirectional GRU
5. Word2Vec + Bidirectional GRU + Attention Network
6. FastText
7. Glove + LSTM (BigDL on Spark Cluster)
72.30%
73.94%
72.97%
74.36%
73.15%
72.50%
75.25%
450여개 Multiple Class , Top 1 문제.
8. Data 정재 및 Argumentation. 89.6%
Data도 달라짐.
정제, 클린징,
Argumentation,
Data 원본 품질 재
정비
성능향상의
대부분은 모
델 외적인 것
에서…
13. Swivel + word Embedding +char Embedding + Hybrid LSTM
+ 다양한 Approach 의 조합 최종…
93.6%
ML Model 1 – Naïve Bayes
ML Model 2 – TF-IDF + SVM
48.26%
61.05% ML 에서 DL
로
Model 성능
향상
퀀텀점프
But,
예외도 있음.
다 직접 개발하는것이 능사는 아니다!
집단 지성의 힘!
검증된 것들을 MashUp!
핵심경쟁력이 아닌 것은 빠르게 하는 것이 더 좋음….
(Over Engineering 방지)
(Open Source + Cloud PaaS)
요즘 가장 Hot 한 Develop 방식들이 추구하는 것들…
• No-Ops (or Dev Ops, Agile, Serverless, Microservices… 이게 목적이 되면 안됨. 수단일 뿐.)
• Scale (유연한 Scale Out, Scale Down, 유연성, 확장성)
• Low Cost (개인화와 최신성, 최신 기법 적용을 위해 필수적 요소)
• Performance (동접 성능, 모델 성능, 개발생산성)
40.
Low Cost 및접근 방법에 대하여
1 Docker ,
1시간에 얼마?
1달에 얼마?
1,000,000
Transaction 에 얼
마???
Tensorflow 자체는
여기 까지만 구동
가능
이 단계로 포팅하려면,
Deep Learning Output
그래프 노드 값을
Graph DB , Hash DB 등
으로 양방향 Index 화 해
야 하며, 고 난이도의
Engineering 작업이 수
반 됨.
이 단계로 되면, 알리바
바 Scale의 Front AI 서비
스가 매우 빠르고 매우
저렴하게 적용 가능.
딥러닝 모델러는 Graph
DB, Microservice 를 모
르고…,
NoSQL 개발자는
딥러닝을 모르고…
Or, CloudML (on GCP)
GPU VM > CPU VM > GPU Docker > K8S PaaS > Docker PaaS > Docker BaaS > Serverless Microservice
GPU on-premise
1 GPU VM ,
1 달에 얼마?
41.
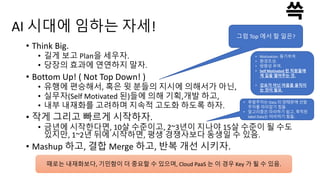
AI 시대에 임하는자세!
• Think Big.
• 길게 보고 Plan을 세우자.
• 당장의 효과에 연연하지 말자.
• Bottom Up! ( Not Top Down! )
• 유행에 편승해서, 혹은 윗 분들의 지시에 의해서가 아닌,
• 실무자(Self Motivated 된)들에 의해 기획,개발 하고,
• 내부 내재화를 고려하며 지속적 고도화 하도록 하자.
• 작게 그리고 빠르게 시작하자.
• 금년에 시작한다면, 10살 수준이고, 2~3년이 지나야 15살 수준이 될 수도
있지만, 1~2년 뒤에 시작하면, 평생 경쟁사보다 동생일 수 있음.
• Mashup 하고, 결합 Merge 하고, 반복 개선 시키자.
그럼 Top 에서 할 일은?
• Motivation. 동기부여.
• 환경조성.
• 방향성 부여.
• Self Motivated 된 직원들에
게 길을 열어주는 것.
• 강요가 아닌 마음을 움직이
는 것이 필요.
• 후발주자는 Data 의 양때문에 선발
주자를 따라잡기 힘듦
• 알고리즘은 따라하기 쉽고, 축적된
label Data는 따라하기 힘듦.
때로는 내재화보다, 기민함이 더 중요할 수 있으며, Cloud PaaS 는 이 경우 Key 가 될 수 있음.
42.
Thank You
• 기타문의는…
• http://hoondongkim.blogspot.kr
• https://www.facebook.com/kim.hoondong
Q & A








![현재 - 2018년 9월 11일 현재.
AI vs 인간 대결에 대한 가설!
• 인간이 지지 않던 시절 = 인류가 태어나고 2016년 까지.
• 인간이 지기 시작하는 시절 = 2016년~2020년(or 2022년?)
• 인간이 항상 지는 시절 = 2020년? 2025년? (시간 문제…)
[전제] AI가 인간의 모든 분야를 앞도 할 순 없다. 즉, 특정 분야에만 해당!
[사실] But,인간보다 AI가 잘 하는 분야가 점점 많아질 것이며,
[직시] 해당 분야가 곧 위기 이며, 기회인 시점이 다가오고 있음.](https://image.slidesharecdn.com/ssgmachinelearningjourneyhoondongkim201809-181002220309/85/E-commerce-BigData-Scale-AI-Journey-12-320.jpg)


















![[AI & DevOps] BigData Scale Production AI 서비스를 위한 최상의 플랫폼 아키텍처](https://cdn.slidesharecdn.com/ss_thumbnails/msfuturenowaidevopsbestplatform-181117103331-thumbnail.jpg?width=640&height=640&fit=bounds)



![[225]yarn 기반의 deep learning application cluster 구축 김제민](https://cdn.slidesharecdn.com/ss_thumbnails/225yarndeeplearningapplicationcluster-161025031031-thumbnail.jpg?width=640&height=640&fit=bounds)












![[235]루빅스개발이야기 황지수](https://cdn.slidesharecdn.com/ss_thumbnails/235-161025031044-thumbnail.jpg?width=640&height=640&fit=bounds)

![[MLOps KR 행사] MLOps 춘추 전국 시대 정리(210605)](https://cdn.slidesharecdn.com/ss_thumbnails/mlops-basic-210605064957-thumbnail.jpg?width=640&height=640&fit=bounds)







![[2017 AWS Startup Day] 스타트업이 인공지능을 만날 때 : 딥러닝 활용사례와 아키텍쳐](https://cdn.slidesharecdn.com/ss_thumbnails/20171102awsstartupday2017-with-171102040932-thumbnail.jpg?width=640&height=640&fit=bounds)





![[한국IBM] AI활용을 위한 머신러닝 모델 구현 및 운영 세션](https://cdn.slidesharecdn.com/ss_thumbnails/ibmdataai-trustedaiv1-190904082052-thumbnail.jpg?width=640&height=640&fit=bounds)






![[오컴 Clip IT 세미나] 머신러닝과 인공지능의 현재와 미래](https://cdn.slidesharecdn.com/ss_thumbnails/kthoccamseminar-180416013406-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2016 데이터 그랜드 컨퍼런스] 2 5(빅데이터). 유비원 비정형데이터 중심의 big data 활용방안](https://cdn.slidesharecdn.com/ss_thumbnails/2-5-161125005035-thumbnail.jpg?width=640&height=640&fit=bounds)




![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)