Downloaded 18 times






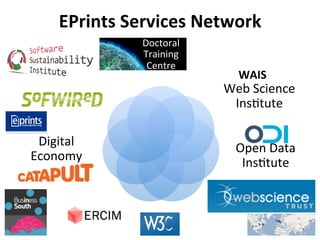





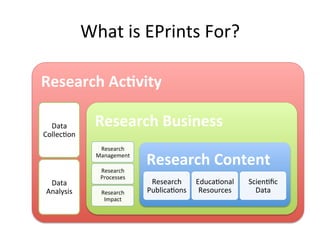









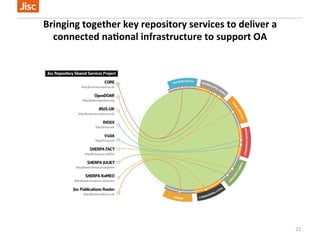





The document discusses the evolution and future direction of Eprints services, highlighting its role in supporting open access and repository activities at the University of Southampton. It outlines current developments, including software improvements and increased integration with external services, and emphasizes the importance of adapting to changing research needs and mandates. Eprints aims to continue evolving as a crucial infrastructure for research management, data collection, and compliance with open access policies.

















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





