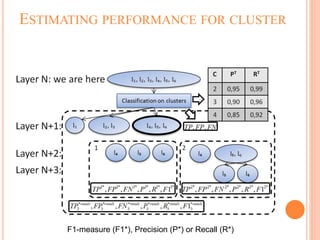
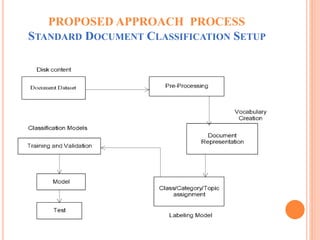
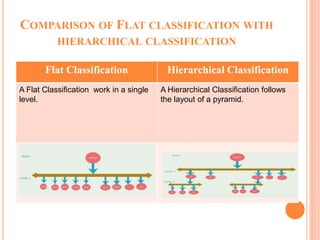
This document summarizes a student's master's thesis project on improving document classification using hierarchical clustering techniques. The student proposes using hierarchical clustering to build a classification hierarchy, then applying a machine learning classifier at each level to improve accuracy over flat classification methods. The document outlines the proposed approach, which involves clustering a training dataset to generate the hierarchy, then evaluating classification performance at different hierarchy levels. Experimental results are presented, followed by conclusions that generating a class hierarchy can improve multi-label text classification performance compared to single-level approaches.








![ALGORITHM FOR HIERARCHY BUILDING
1: function HIERARCHY(TrainSet; Labels;RootNode;Kmin;Kmax)
2: Pmin Performance Measure(TrainSet)
3: for I Kmin;Kmax do
4: C[i] do Clustering(TrainSet; Labels; I)
5: Dataset dataMetaLabeling(TrainSet; C)
6: Results[I] Performance Measure (Dataset)
7: end for
8:PerfEstimation;Kbest PerfEstimate(Results; C)
9: if PerfEstimation > Pmin then
10: addChildNodes(RootNode;C[Kbest])
11: for I 0;BestNumber do
12: Hierarchy(TrainSet;
13: C[Kbest][I];RootNode:Child(I))
14: end for
15: end if
16: end function
17:functionPERFORMANCEMEASURE(Dataset)
18: Train P art; Test P art split(Dataset)
19: return Performance(Train P art; Test P art)
20: end function
21: function PERFESTIMATE(Results; Clusters)
22: end function](https://image.slidesharecdn.com/mainppt-180313002151/85/Document-Classification-Using-Hierarchies-Clusters-Technique-11-320.jpg)