Downloaded 18 times










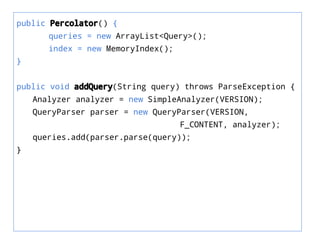





This document discusses how to build a percolator using ElasticSearch. A percolator allows queries to be registered and then determines if incoming documents match any of the stored queries. The key points are: - ElasticSearch has a built-in percolator that stores queries and checks for matches when documents are indexed. - As an alternative, a custom percolator can be built using ElasticSearch's MemoryIndex to hold a single document and search stored queries against it to find matches. - Sample code is provided to add queries, percolate documents by clearing the MemoryIndex, adding the document fields, and searching each query to find matches.


































































