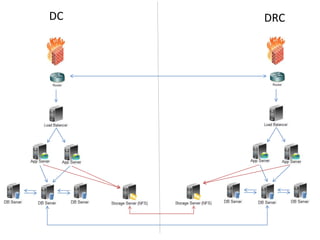
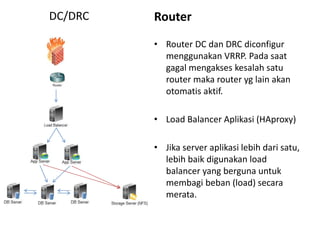
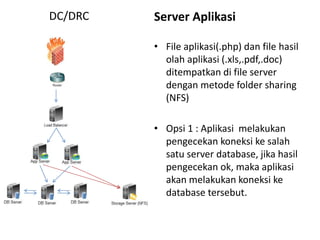
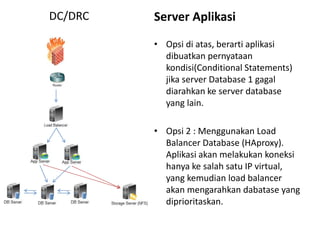
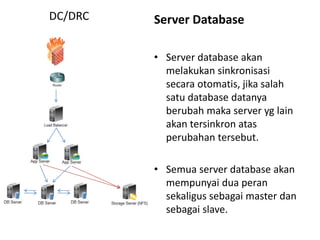
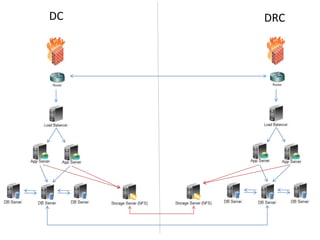
Dokumen ini membahas tentang Disaster Recovery Center (DRC) dan High Availability (HA) yang mencakup pengaturan router, load balancer, dan strategi pengelolaan server aplikasi dan database. Terdapat dua opsi untuk koneksi database yang memastikan kelangsungan operasi meskipun ada server yang gagal, serta implementasi sinkronisasi data otomatis di antara database server. Juga dijelaskan modul aplikasi pendukung untuk backup dan pemulihan data yang terjadwal dan manual.