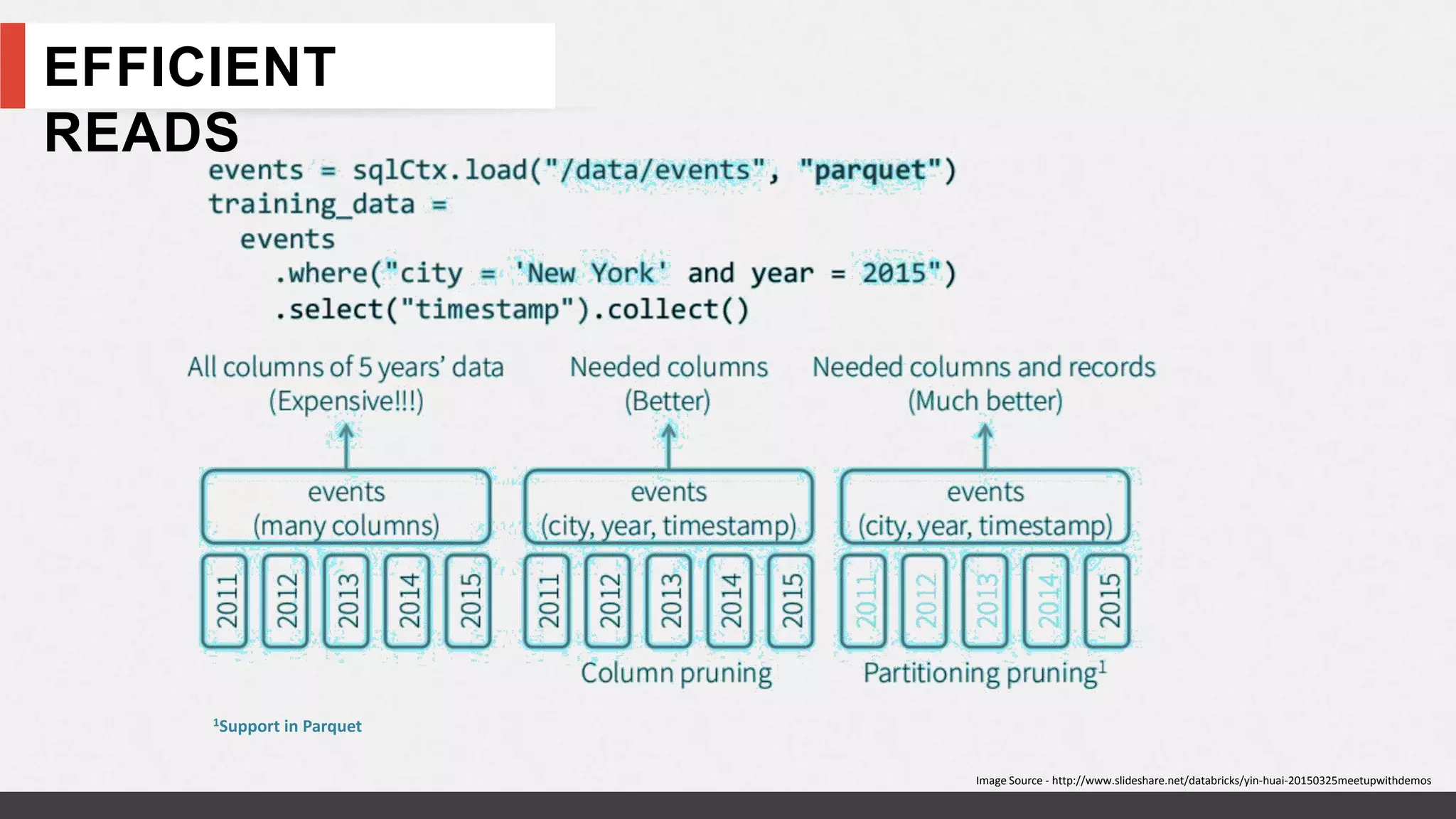
This document discusses using Apache Spark for interactive analytics on large datasets. It describes using Spark with HDFS for storage, Parquet file format, and processing data efficiently in Spark. The document includes a case study of real-time ad campaign performance tracking using Spark on datasets of 100TB in size. It also provides benchmarks comparing query performance of Spark to other systems.