




















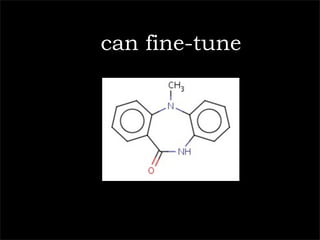
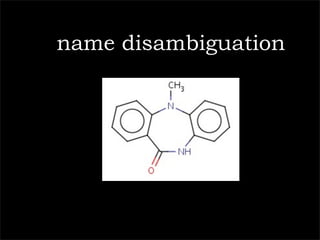
![10,11-dihydro-5-methyl-5H-dibenzo[b,e][1,4]diazepin-11-one](https://image.slidesharecdn.com/palgravepreso-110127073440-phpapp02/85/Digital-Science-31-320.jpg)







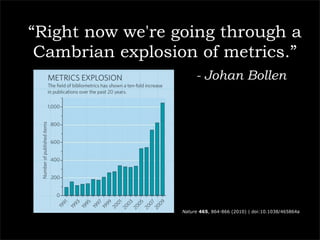



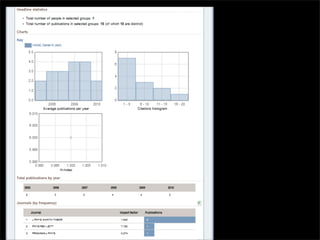











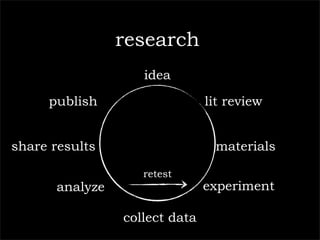
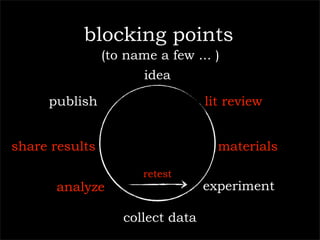
The document outlines a technology company's focus on enhancing scientific research through improved knowledge discovery and research management software applications. It highlights the need for better tools to address existing inefficiencies in data capture, citation metrics, and collaboration within the scientific community. The ultimate goal is to develop software that better understands scientific needs, thereby increasing research productivity and efficacy.























































































