Download as PDF, PPTX
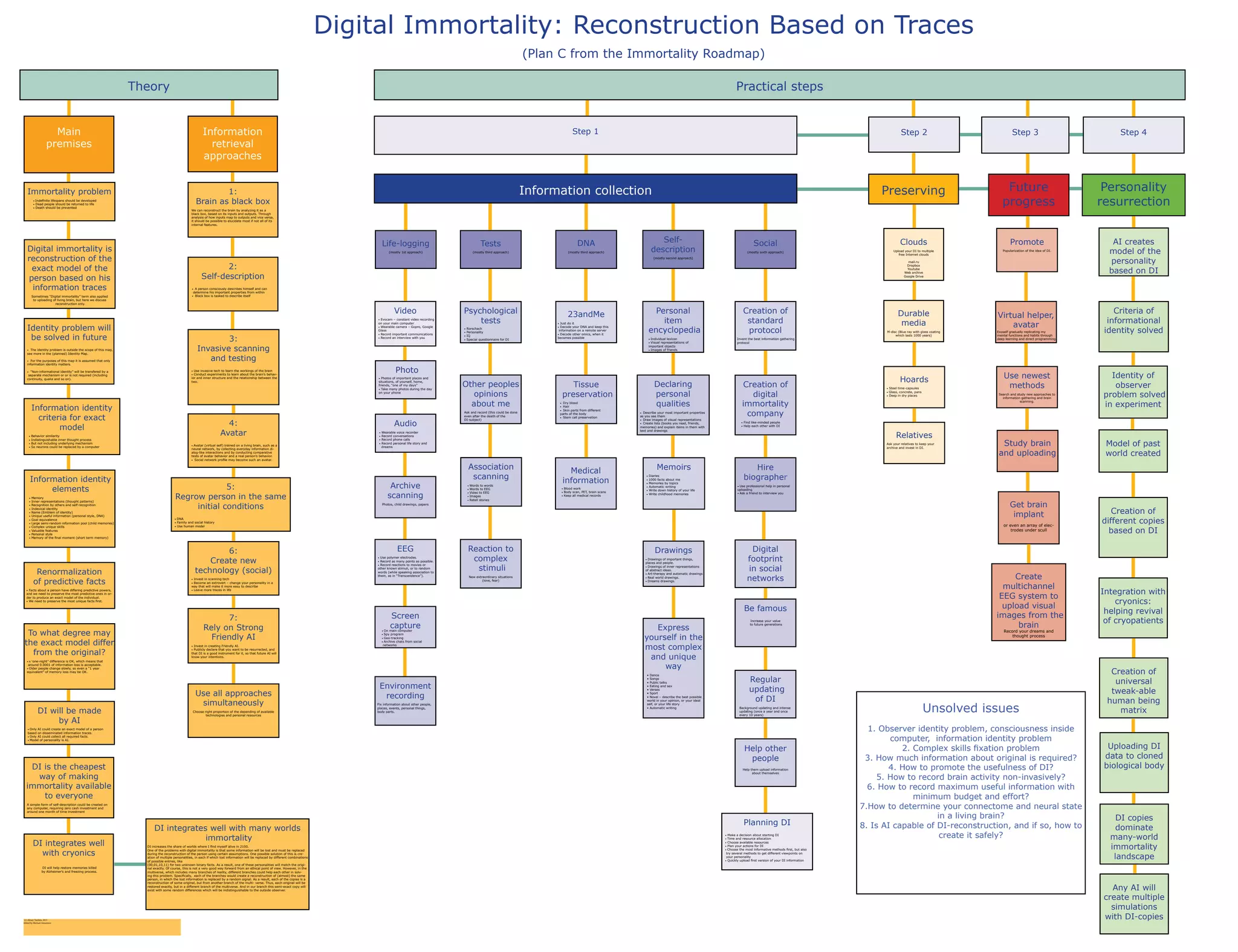

1) The document outlines an "Immortality Roadmap" with various approaches and methods for achieving "Digital Immortality" through comprehensively reconstructing a person based on collected information traces. 2) It details many specific techniques for information collection including constant video/audio recording, archiving documents and photos, DNA sequencing, medical scans, psychological tests, and more. 3) The goal is to gather enough identifiable information to allow reconstruction of the individual's personality and thought processes through an AI assistant or virtual avatar even after biological death. This could help solve problems like information loss during reconstruction.












































































