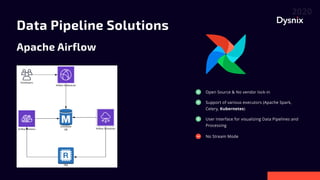
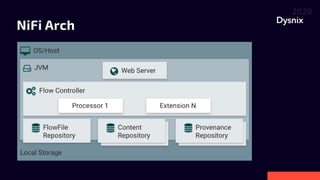
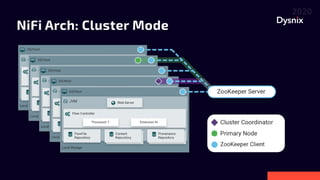
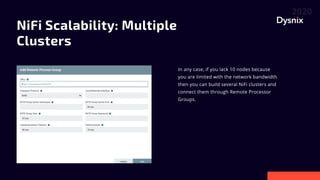
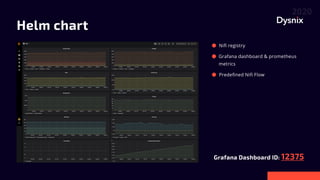
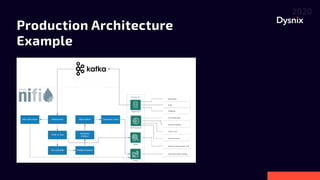
Daniel Yavorovych discusses the importance and challenges of real-time data processing in data pipelines, highlighting various solutions such as Google Cloud Dataflow, Apache Airflow, and Apache Nifi. He advocates for Nifi due to its scalability, flexibility, and user-friendly features like real-time data flow changes and a robust registry for managing shared resources. The talk emphasizes the necessity of technical expertise in building effective data flows and recommends using custom scripts when native processors are inadequate.