DEPRESSIVE AND NON-
DEPRESSIVETWEETS
CLASSIFICATION USING
MACHINE LEARNING
MODELS
Under Supervision of Mr. Arvind Kumar
Student Details:
Arpit kushwaha
2023PAI7302
M.Tech(CSAI)
2.
Introduction: The Needfor Early Detection
Depression: A Growing Issue
Depression is a prevalent mental health condition affecting
millions worldwide. Its impact on individuals, families, and
communities is significant, making early intervention
crucial for positive outcomes.
Social Media's Potential
Social media platforms provide a rich and readily accessible
source of data for mental health analysis. User-generated
content, such as tweets, can offer valuable insights into
emotional states and potential indicators of mental health
challenges.
3.
Motivation: Bridging theGap
Increasing Global
Prevalence
The global prevalence of
mental health disorders has
been on the rise,
emphasizing the need for
innovative detection and
intervention strategies.
Non-Invasive
Behavioral Analysis
Social media offers a non-
invasive approach to
behavioral analysis,
providing valuable data
without direct interaction or
intrusive methods.
Cost-Effective and Scalable Solutions
Machine learning techniques offer cost-effective and scalable
solutions for analyzing large datasets, potentially reaching a wider
population.
4.
Literature Survey: ExistingResearch
• Melancholy is a commonplace intellectual fitness condition that influences a sizeable wide variety of individuals global [1]
• It is characterized by continual emotions of disappointment, lack of hobby, and impaired functioning, main to a
considerable decline in universal properly-being and excellent of life [2].
• Timely detection and intervention are vital for the effective control and remedy of despair. Left untreated, depression can
cause severe impairments in private, social, and occupational functioning [3].
• The arrival of social media platforms has furnished an unparalleled opportunity to take a look at mental fitness
conditions, which includes depression, on a huge scale [4].
• Twitter, especially, has emerged as a precious source of information for information individuals’ mind and feelings. Twitter
customers frequently brazenly percentage their private studies, emotions, and feelings, making it feasible to explore and
perceive symptoms of melancholy via their public messages [5].
• Device getting to know techniques have validated titanic capability in routinely studying substantial volumes of textual
information and extracting meaningful insights [6,7].
• Natural language processing (NLP) algorithms, specifically, were leveraged to develop computational fashions able to
detecting despair signs and symptoms in consumer-generated content material, including tweets [8].
5.
Problem Statement: Challengesand Needs
1 Noisy Data
Extracting meaningful
depression signals from the
noisy and complex world of
social media poses a significant
challenge. Identifying relevant
patterns amidst irrelevant
information is crucial for
effective detection.
2 Robust and Scalable
Models
There's a need for models that
are robust enough to handle the
diversity and variability of social
media data, while also being
scalable to accommodate large
datasets and diverse user
populations.
3 Accurate Depression
Detection
The development of accurate
and reliable depression
detection models is paramount
to ensure effective intervention
and support for individuals in
need.
6.
Objectives: Aiming forEarly
Identification
Accurate Depression Detection
The primary objective is to develop highly accurate
models that can effectively detect depression from user
tweets, providing valuable insights into mental health
patterns.
Transformer-Based Models
This research investigates the potential of advanced
transformer-based models, known for their ability to
understand complex contextual relationships in language,
to enhance depression detection accuracy.
7.
Model Choice: Transformer-
BasedApproach
RoBERTa, DeBERTa & Some
ML Techniques
The study utilizes the RoBERTa
(Robustly Optimized BERT
Pretraining Approach)
transformer model, renowned for
its exceptional performance in
contextual language
understanding tasks.
Superior Accuracy
DeBERTa achieved the highest
accuracy (98) among various
models tested, showcasing its
potential for accurate depression
detection from social media data.
8.
Tools and Technologies:Building the Framework
Python Programming Language
The research utilizes Python as the primary
programming language, leveraging its extensive
libraries and frameworks for data analysis, model
development, and evaluation.
PyTorch and Scikit-learn Libraries
PyTorch, a popular deep learning library, provides the
foundation for training and evaluating transformer-
based models. Scikit-learn, a machine learning library,
facilitates various data processing and model
development tasks.
HuggingFace Transformers Library
The HuggingFace Transformers library provides a
comprehensive set of tools and pretrained transformer
models, streamlining the process of implementing and
using advanced models.
Sentiment140 Dataset
The study utilizes the Sentiment140 dataset, re-labeled
for depressive sentiment detection, providing a rich
source of annotated tweets for training and evaluating
depression detection models.
9.
Methodology: Training and
Evaluation
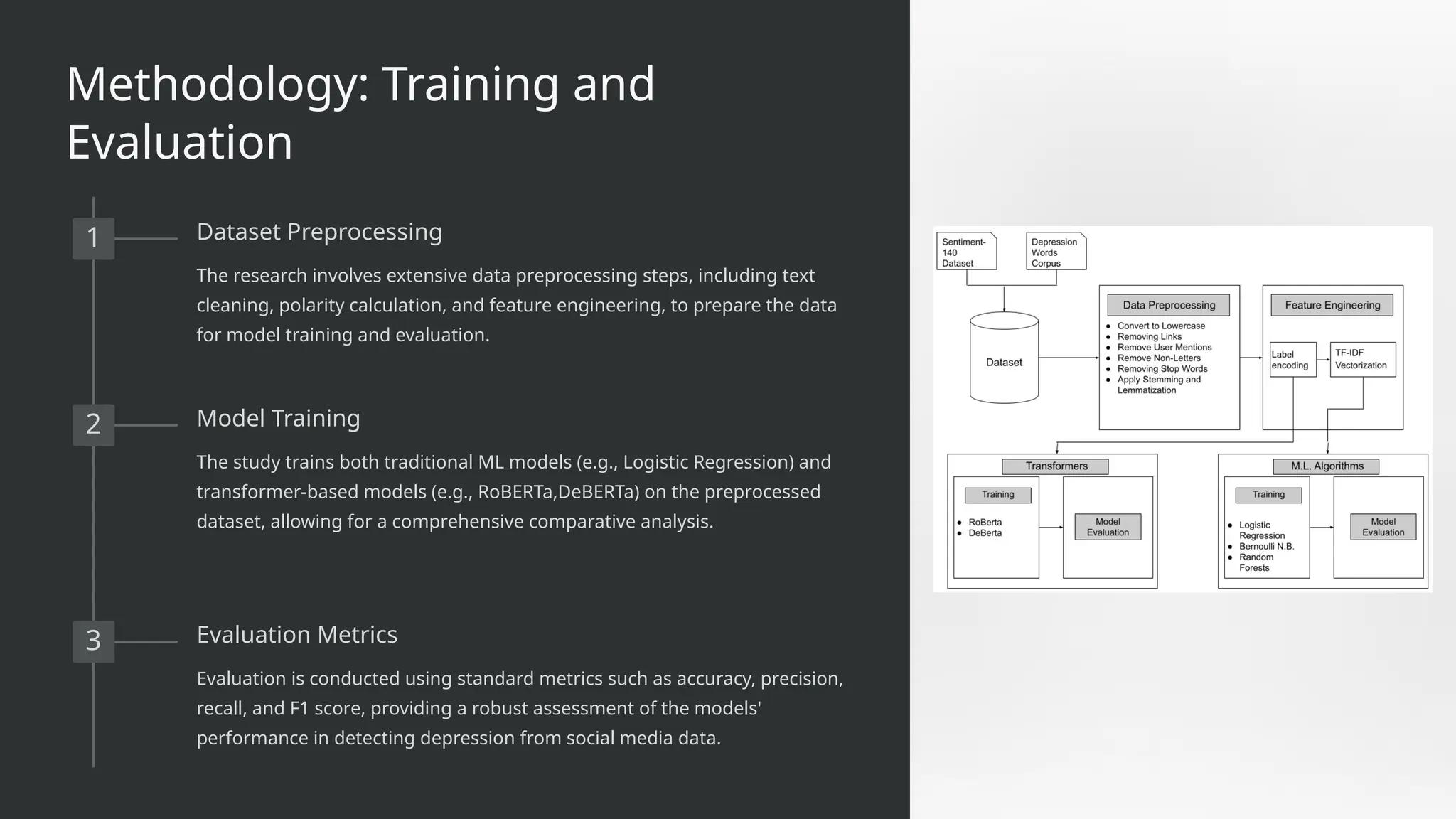
1Dataset Preprocessing
The research involves extensive data preprocessing steps, including text
cleaning, polarity calculation, and feature engineering, to prepare the data
for model training and evaluation.
2 Model Training
The study trains both traditional ML models (e.g., Logistic Regression) and
transformer-based models (e.g., RoBERTa,DeBERTa) on the preprocessed
dataset, allowing for a comprehensive comparative analysis.
3 Evaluation Metrics
Evaluation is conducted using standard metrics such as accuracy, precision,
recall, and F1 score, providing a robust assessment of the models'
performance in detecting depression from social media data.
10.
DistilBERT and DeBERTa
DistilBERTDeBERTa
• DeBERTa is an improved version of BERT, trained with
more data and without the next sentence prediction task.
• It uses dynamic masking and larger batch sizes for better
contextual understanding.
• This model excels in NLP tasks like sentiment analysis and
question answering.
• DistilBERT is a smaller, faster, and lighter version of BERT,
retaining 97% of its performance.
• It is trained using knowledge distillation, making it six
times faster than BERT.
• With fewer parameters, it is ideal for real-time
applications and edge devices.
Results: Insights and
Findings
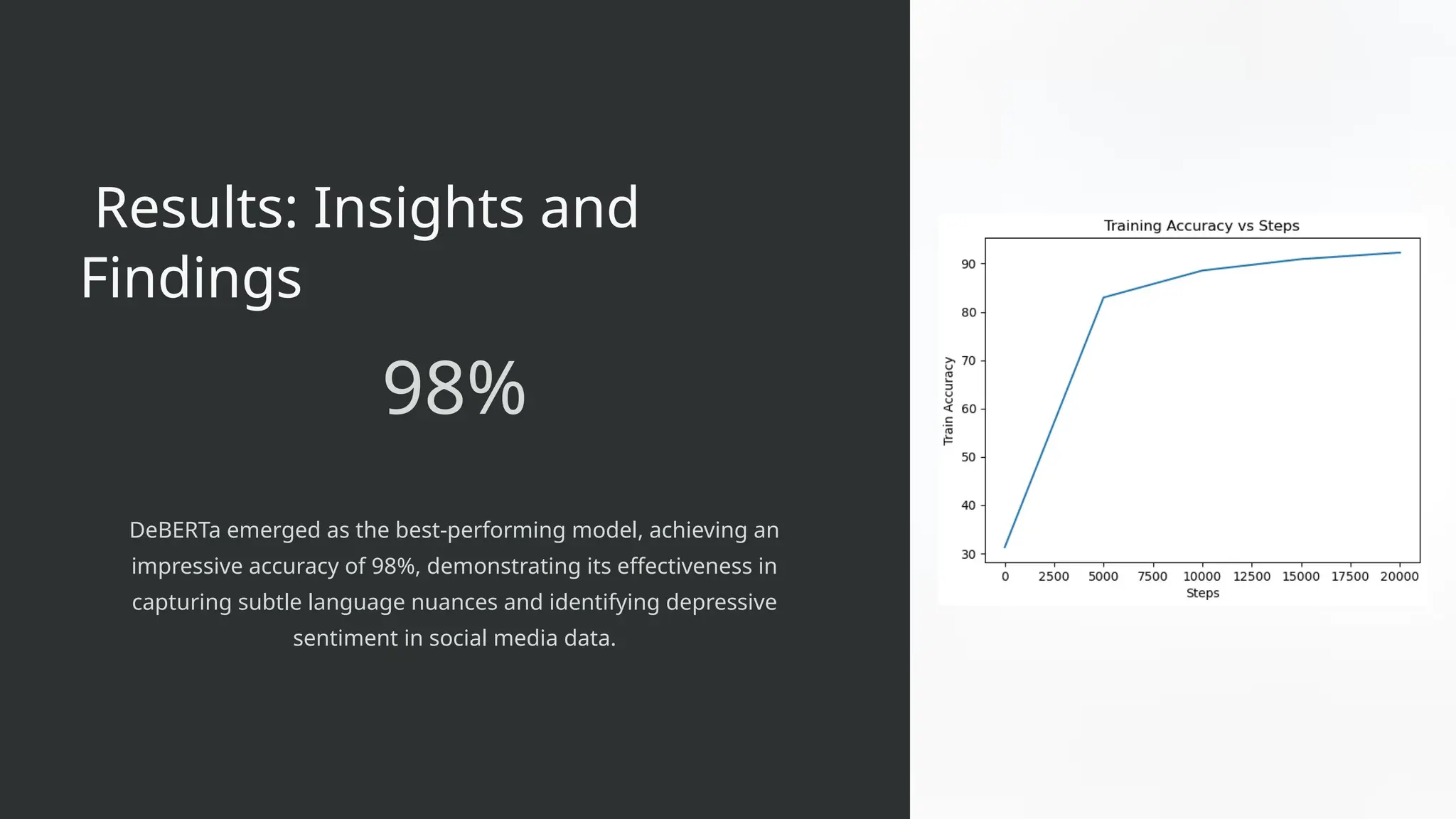
98%
DeBERTaemerged as the best-performing model, achieving an
impressive accuracy of 98%, demonstrating its effectiveness in
capturing subtle language nuances and identifying depressive
sentiment in social media data.
13.
Conclusion and FutureWork
Conclusion:
• Successfully classified depressive and non-depressive tweets using machine learning models.
• Identified the best-performing model based on evaluation metrics like accuracy and F1-score.
• Demonstrated the potential of such models in mental health monitoring applications.
Future Work:
• Expand the dataset to improve model generalization and accuracy.
• Incorporate advanced NLP techniques such as BERT or GPT-based models for better understanding of context.
• Explore multilingual capabilities for global applicability.
• Address ethical considerations, such as privacy and misuse of data.
14.
References
• WHO, GlobalHealth Estimates for Mental Disorders, 2017.
• American Psychiatric Association, DSM-IV Manual, 1994.
• Nesi, J., The Impact of Social Media on Youth Mental Health, 2020.
• Bokolo, B.G. & Liu, Q., Deep Learning-Based Depression Detection from Social Media, 2023.
• Coppersmith, G. et al., Quantifying Mental Health Signals in Twitter, 2014.
• Hassani, H. et al., Text Mining in Big Data Analytics, 2020.
• Aggarwal, C.C., Neural Networks and Deep Learning, 2018.
• Motlagh, F.G., NLP Models for Medical Terms Detection in Twitter, 2022.
• De Choudhury, M. et al., Predicting Depression via Social Media, 2013.
Russell, S.J., Artificial Intelligence: A Modern Approach, 2010.
•



![Literature Survey: Existing Research
• Melancholy is a commonplace intellectual fitness condition that influences a sizeable wide variety of individuals global [1]
• It is characterized by continual emotions of disappointment, lack of hobby, and impaired functioning, main to a
considerable decline in universal properly-being and excellent of life [2].
• Timely detection and intervention are vital for the effective control and remedy of despair. Left untreated, depression can
cause severe impairments in private, social, and occupational functioning [3].
• The arrival of social media platforms has furnished an unparalleled opportunity to take a look at mental fitness
conditions, which includes depression, on a huge scale [4].
• Twitter, especially, has emerged as a precious source of information for information individuals’ mind and feelings. Twitter
customers frequently brazenly percentage their private studies, emotions, and feelings, making it feasible to explore and
perceive symptoms of melancholy via their public messages [5].
• Device getting to know techniques have validated titanic capability in routinely studying substantial volumes of textual
information and extracting meaningful insights [6,7].
• Natural language processing (NLP) algorithms, specifically, were leveraged to develop computational fashions able to
detecting despair signs and symptoms in consumer-generated content material, including tweets [8].](https://image.slidesharecdn.com/depressive-and-non-depressive-tweets-classification-using-machine-learning-models-250518221638-16eb6252/75/DEPRESSIVE-AND-NON-DEPRESSIVE-TWEETS-CLASSIFICATION-USING-MACHINE-LEARNING-MODELS-pptx-4-2048.jpg)