





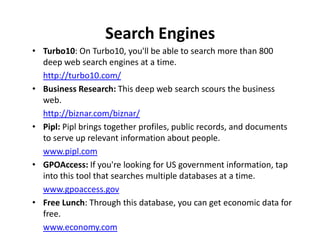

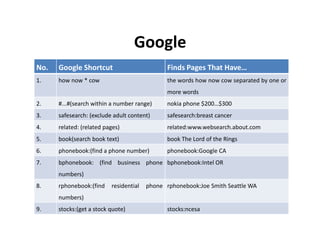
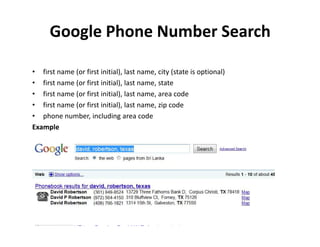

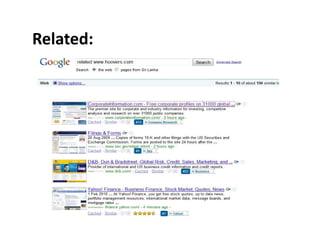
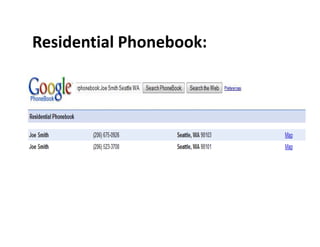



The document discusses the deep web, which contains over 500 times more content than the surface web that is indexed by search engines. It contains approximately 7,500 terabytes of data across 550 billion documents that standard search engines have difficulty accessing directly. The document also outlines methods for searching the deep web through federated search engines and databases that provide access to collections such as government and academic information.











































































