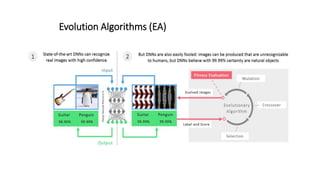
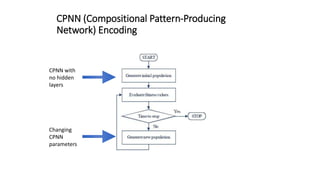
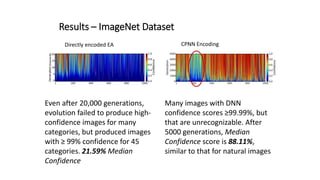
The document discusses the vulnerability of deep neural networks (DNNs) to be misled by unrecognizable images despite high confidence predictions, using trials with the MNIST and ImageNet datasets. It highlights the experimental setup involving various encoding methods, including direct and indirect encoding, and reports that the MNIST DNN was able to classify unrecognizable images with 99.99% confidence after only a few generations. For the ImageNet dataset, while many images achieved high confidence, some categories remained challenging to classify accurately even after extensive generations of evolution.




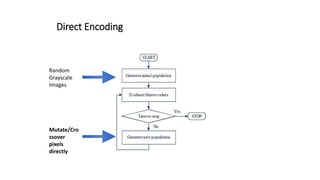
![Direct Encoding
Grayscale values for MNIST, HSV values for ImageNet.
Each pixel value is initialized with uniform random
noise within the [0, 255] range. Those numbers are
independently mutated.](https://image.slidesharecdn.com/deepneuralnetworksareeasilyfooled-230424162537-8ac6e351/85/Deep-Neural-Networks-Are-Easily-Fooled-pptx-5-320.jpg)














![[AI07] Revolutionizing Image Processing with Cognitive Toolkit](https://cdn.slidesharecdn.com/ss_thumbnails/ai07-170602095346-thumbnail.jpg?width=640&height=640&fit=bounds)






























![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










