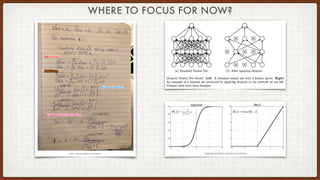
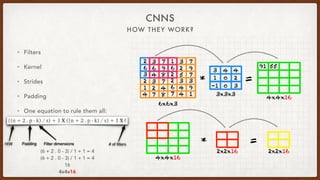
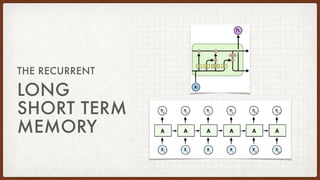
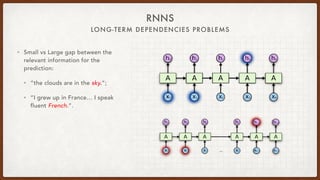
The document discusses various aspects of natural language processing (NLP) using deep learning techniques, covering topics such as vector representations of words, shallow and deep neural networks, convolutional networks, and long-short term memory networks. It provides insights into how these algorithms work, their architectures, and practical applications like sentiment analysis. Additionally, it mentions the automation of infrastructure management using Terraform in cloud environments.



![WHAT IS IN THERE FOR YOU?
AGENDA
• The Basics
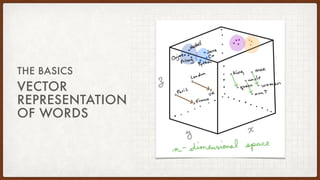
• Vector Representation of Words
• The Shallow
• [Deep] Neural Networks for NLP
• The Deep
• Convolutional Networks for NLP
• The Recurrent
• Long-short Term Memory for NLP
• Where do we go from here?
• Automation of AWS GPUs with Terraform](https://image.slidesharecdn.com/deeplearningfornlp-180306055557/85/Deep-Learning-for-Natural-Language-Processing-3-320.jpg)


![[DEEP]
NEURAL
NETWORKS
THE SHALLOW](https://image.slidesharecdn.com/deeplearningfornlp-180306055557/85/Deep-Learning-for-Natural-Language-Processing-8-320.jpg)