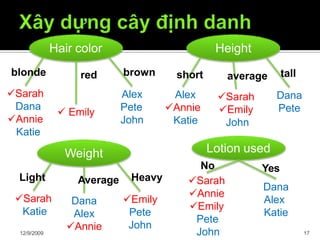
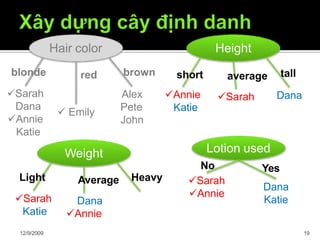
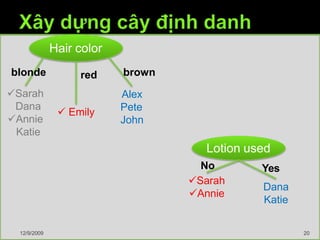
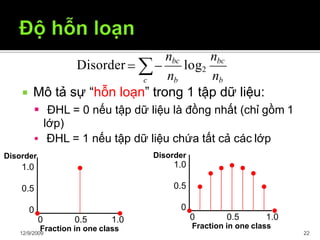
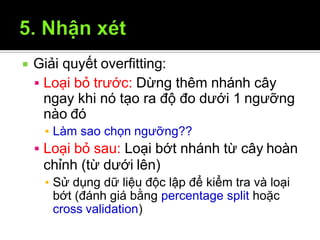
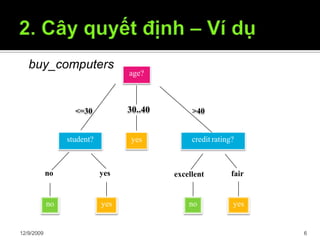
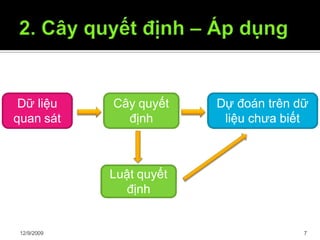
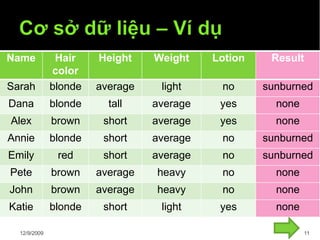
Tài liệu trình bày về cây quyết định trong máy học, bao gồm các thuật toán và quy trình xây dựng cây dựa trên tập dữ liệu. Cây quyết định giúp phân lớp và dự đoán dữ liệu chưa biết thông qua việc phân chia các tập mẫu dựa trên thuộc tính. Bên cạnh đó, tài liệu cũng đề cập đến các vấn đề như overfitting và phương pháp giải quyết chúng.









![ Thế giới vốn dĩ là đơn giản [*].
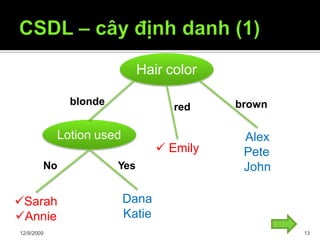
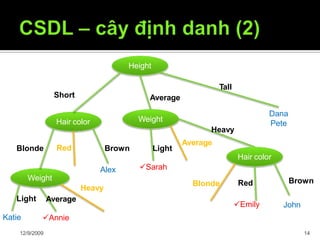
Cây định danh nhỏ nhất mà nhất quán với
các mẫu cây có khả năng nhất trong
việc phân lớp chính xác các đối tượng
chưa biết
Cây định danh (1) tốt hơn (2)
[*] William Ockham (1285–1349): "Entities should not be multiplied unnecessarily."
Làm sao xây dựng cây
12/9/2009 15
định danh nhỏ nhất?](https://image.slidesharecdn.com/onkwph0vtawamaymmtyh-signature-909ca2a66e4ae94c8e75b0976384b8da40b7deebde0c61347a6e443939a0fe82-poli-160427171034/85/Decision-tree-15-320.jpg)