Simultaneous multithreading (SMT) allows multiple independent threads to issue and execute instructions simultaneously each clock cycle by sharing the functional units of a superscalar processor. This improves performance over conventional multithreading approaches like coarse-grained and fine-grained multithreading. SMT provides good performance across a wide range of workloads by utilizing instruction issue slots and execution resources that would otherwise go unused when a single thread is limited by dependencies or cache misses. Implementing SMT requires minimal additional hardware like multiple program counters and per-thread scheduling structures.
![What is Simultaneous Multithreading?
Generally speaking there are two types of parallelism that can be exploited by modern computing
machinery to achieve higher performance. The Instruction Level Parallelism (ILP) approach
attempts to reduce program runtime by overlapping the execution time of as many instructions as
possible, to as great a degree as possible. The EV8 will have higher performance than earlier Alpha
designs through the enhanced exploitation of ILP made possible by its eight-instruction issue width.
But gains from higher ILP come at a high and ever increasing price. Building wider machines runs
into the problem of geometrically increasing complexity in control logic while data and control
dependencies within the program code limit performance increases. John Hennessy of Stanford
University has likened the difficulty of increasing exploitation of ILP for greater performance to the
task of pushing a boulder up a mountain whose slopes grow ever steeper the further processor
architects progress [1].
Figure 1. Multithreaded Execution with Increasing Levels of TLP Hardware Support
The second form of parallelism is called Thread Level Parallelism or TLP. This simply means the
ability to execute independent programs, or independent parts of a single program, simultaneously
using different flows of execution, called threads. The illusion of multiple thread execution is often](https://image.slidesharecdn.com/xleygdkqqsklepgmekvw-signature-4b2bfabf29a67521ae81dada6f3c48b5e812df618f19f7f525760ced6c00c484-poli-160512174544/75/What-is-simultaneous-multithreading-1-2048.jpg)

![For example, a four-way fine grained multithreaded processor might provide single cycle latency
floating point (FP) addition while conventional processors typically require three or four cycles of
latency. That is possible because the FP adder has four physical processor clock cycles to advance a
thread’s FP add instruction through what is one logical execution pipeline stage from the thread’s
viewpoint. In a similar fashion, memory latency appears to be 1/Nth the number of processor clock
cycles from the viewpoint of individual threads. The hardware cost of fine grained multithreading is
relatively modest: N thread contexts, and control logic and multiplexors to cyclically commutate
instructions and data from N different threads into and out of the execution units. The drawback of
this approach is that its performance running any single thread is still appreciably less than for a
conventional processor although the system throughput is increased. An example of a fine-grained
multithreaded processor is the five-threaded MicroUnity MediaProcessor [2].
The EV8 uses a more powerful mechanism than either coarse or fine grained multithreading to
exploit TLP. Called Simultaneous Multithreading (SMT), it allows the instructions from two or
more threads to be issued to execution units each cycle. This process is illustrated conceptually in
Figure 1D. The advantage of SMT is that it permits TLP to be exploited all the way down to the
most fundamental level of hardware operation - instruction issue slots in a given clock period. This
allows instructions from alternate threads to take advantage of individual instruction execution
opportunities presented by the normal ILP inefficiencies of single thread program execution. SMT
can be thought of as equivalent to the airline practice of using standby passengers to fill seats that
would have otherwise flown empty.
Consider a single thread executing on a superscalar processor. Conventional superscalar processors
such as the Alpha EV6 fall well short of utilizing all the available instruction issue slots. This is
caused by execution inefficiencies including data dependency stalls, cycle by cycle shortfall
between thread ILP and the processor resources given limited re-ordering capability, and memory
accesses that miss in cache. The big advantage of SMT over other approaches is its inherent
flexibility in providing good performance over a wide spectrum of workloads. Programs that have a
lot of extractable ILP can get nearly all the benefit of the wide issue capability of the processor.
And programs with poor ILP can share with other threads instruction issue slots and execution
resources that otherwise would have gone unused.
Hardware Requirements for SMT
Compared to a conventional out-of-order execution superscalar processor like the EV6, the
following hardware changes are necessary to support SMT operation:
1. Multiple program counters (PCs), and the capacity to select one or more of them to direct
instruction fetch each clock cycle.
2. Association of a thread identifier with each instruction fetched to distinguish different
threads for the purpose of branch prediction, branch target buffering, and register renaming.
3. A per-thread capacity to retire, flush, and trap instructions.
4. A per-thread stack for prediction of subroutine return addresses.
One of the most remarkable aspect of SMT is it takes relatively little extra logic to add the
capability to the execution portion of an out-of-order execution superscalar processor that employs
register renaming and issue queues. Register renaming is a scheme in which the logical registers in
an instruction set architecture (ISA) are mapped to a subset of a larger pool of physical hardware
registers. Each time an instruction is decoded the logical register specified to be overwritten with
the instruction result (i.e. the destination register) is assigned a mapping to a new physical register,
i.e. it is renamed. When the instruction completes execution and retires, its physical destination](https://image.slidesharecdn.com/xleygdkqqsklepgmekvw-signature-4b2bfabf29a67521ae81dada6f3c48b5e812df618f19f7f525760ced6c00c484-poli-160512174544/75/What-is-simultaneous-multithreading-3-2048.jpg)
![register becomes officially bound to the logical destination register within the processor state, i.e.
the result is committed. Register renaming permits out-of-order execution of instructions to proceed
even in the presence of false dependencies as shown in Figure 2.
Figure 2 Data Dependencies and Register Renaming
Register renaming is also done to permit speculative execution beyond conditional branches since it
allows the results of speculated instructions to be discarded and earlier processor state restored if
the branch turns out to be mispredicted. In this case it is only necessary to restore an older mapping
of logical to physical registers.
The beauty of register renaming is that it allows an SMT processor to contain multiple thread
contexts without the need for multiple physical register sets or additional complicated tracking logic
to ensure execution results from instructions from different threads are written to the appropriate
thread context. For example, the Alpha EV6 has 80 physical integer registers (there are actually 160
integer registers in the EV6 device but these are really two duplicate sets of 80 for reasons I won’t
go into) and 72 physical FP registers. At any given time, 31 of the 80 physical integer registers
contain the contents of the 31 logical general purpose registers that appear to the programmer in the
Alpha ISA (there are actually 32 logical integer registers but one of them always reads as zero, as is
customary for RISC architectures). The remaining physical registers are available for renaming. The
EV6 uses two separate twelve-port register mappers for integer and FP register renaming, and each
can rename up to four instructions per clock [3]. Content addressable memory (CAM)-based tables](https://image.slidesharecdn.com/xleygdkqqsklepgmekvw-signature-4b2bfabf29a67521ae81dada6f3c48b5e812df618f19f7f525760ced6c00c484-poli-160512174544/75/What-is-simultaneous-multithreading-4-2048.jpg)
![are used to hold the register mapping state. The map tables are also buffered so that an older state
can be saved and later restored, if necessary to recover from branch mispredictions and exceptions.
At first glance, implementing a four-way SMT like the EV8 would seem to require four separate
and independent register mapping tables, one for each thread. This could be physically realized with
a single map table if the size of logical register specifiers used by the mapper is expanded to 7 bits
by appending a two-bit thread identifier associated with a fetched instruction to the 5 bit logical
register specifiers extracted from the instruction itself. So thread context 0 would use mapper
logical registers 0 through 31, thread 1 would use mapper logical registers 32 through 63 and so on.
In this scheme each quadrant of the mapper CAM would have the capability to be independently
backed up in buffers and restored as needed to maintain the illusion of serial, in-order execution of
each thread.
Early research into 8-issue wide superscalar out-of-order processors suggests that with a 64 entry
dispatch queue at least 96, and preferably 128, physical registers are needed to limit the fraction of
time the processor is out of free registers to 15% and 10% respectively [4]. It is known that the EV8
supports four thread contexts in hardware [5]. This suggests that the EV8 needs an additional 96
integer physical registers above and beyond a conventional 8-issue wide superscalar. That places
the number of integer physical renaming registers in the EV8 in the range of 192 to 224 for optimal
performance. It should be noted that this exceeds even the 128 logical/physical integer registers
required in implementations of Intel/HP's IA-64 instruction set architecture. Such a large, highly
ported register file has the potential to seriously limit EV8's clock rate even with the use of an
advanced 0.13 um process. The best solution to this problem is to spread register read and write
access across two pipe stages instead of one. This has the effect of lengthening the basic execution
pipeline from EV6's seven stages to nine stages as shown in Figure 3. One study suggests the extra
two pipeline stages in the hypothetical EV8 will degrade single thread performance by less than 2%
[6].
Figure 3. Comparison of EV6 and Hypothetical EV8 Execution Pipeline
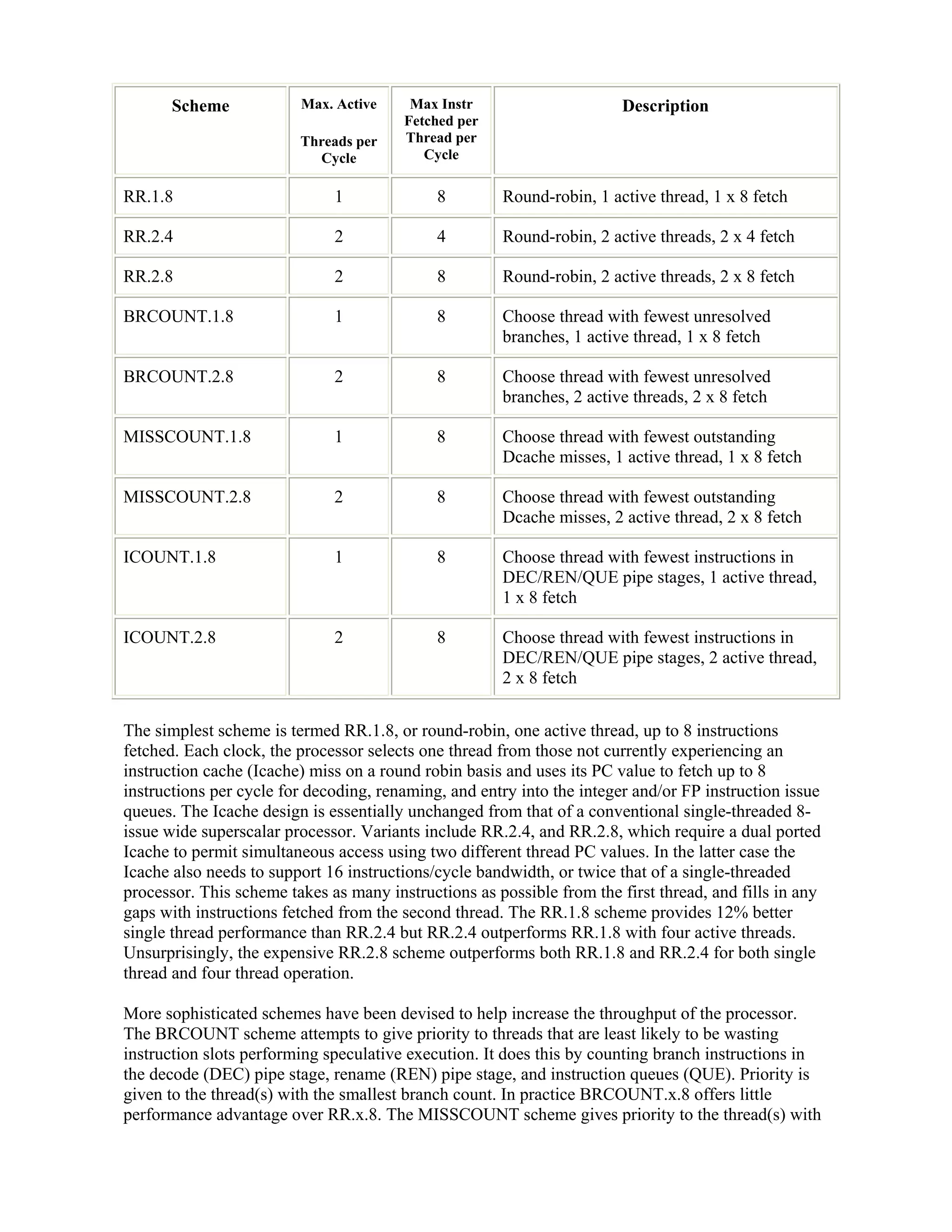
Instruction Selection Strategies For SMT
I have described how the execution engine portion of an out-of-order superscalar processor
implementing register renaming can be modified to support SMT operation. The big design issue
with SMT is the algorithm that chooses between threads for the fetch and issue of instructions to
that execution engine. A number of different schemes associated with 8 issue wide SMT RISC
processor designs have been investigated and reported in the literature [7]. Some of these schemes
are listed in Table 1.](https://image.slidesharecdn.com/xleygdkqqsklepgmekvw-signature-4b2bfabf29a67521ae81dada6f3c48b5e812df618f19f7f525760ced6c00c484-poli-160512174544/75/What-is-simultaneous-multithreading-5-2048.jpg)
![the fewest number of outstanding data cache (Dcache) misses. Like BRCOUNT, MISSCOUNT.x.8
offers little advantage over RR.x.8.
The ICOUNT scheme takes a more general approach to prevent the 'clogging' of the instruction
execution queues. Priority is given to the thread(s) with the fewest instructions in the DEC, REN,
and QUE pipe stages. ICOUNT has the effect of keeping one thread from filling the instruction
queue and favors threads that are moving instructions through the issue queues most efficiently. It
turns out the ICOUNT scheme is also highly effective at improving processor throughput. It
outperforms the best round-robin scheme by 23% and increases throughput to as much as 5.3 IPC
compared to 2.5 for a non-SMT superscalar with similar resources (in this study: 32 KB direct
mapped Icache and Dcache, 256 KB 4-way L2 cache, 2 MB direct mapped off-chip cache). In fact,
ICOUNT.1.8 consistently outperforms RR.2.8.
The performance difference between ICOUNT.1.8 and ICOUNT.2.8 doesn’t appear to be
significant. Given the choice between them, the EV8 designers would likely choose ICOUNT.1.8 to
halve Icache fetch bandwidth requirements and reduce associated power consumption. Interestingly,
in a more recent paper [6], Alpha architect Joel Emer and his collaborators seem to favor an
ICOUNT.2.4 scheme (2 active threads, up to 4 instructions fetched per thread per cycle). At first
glance this choice, to the extent that it foretells the actual EV8 fetch heuristic, seems contrary to
previous claims by Compaq that the SMT capabilities of EV8 would not hurt its single thread
performance compared to a single-threaded processor. One possible explanation for this apparent
contradiction may be that the ICOUNT.2.4 scheme as hypothetically implemented in EV8 is
capable of using a single thread PC value to access both Icache ports to permit 8 instruction wide
fetch capability for a single thread when appropriate. The processor organization of this
hypothetical ICOUNT.2.4 based EV8 design is shown in Figure 4.](https://image.slidesharecdn.com/xleygdkqqsklepgmekvw-signature-4b2bfabf29a67521ae81dada6f3c48b5e812df618f19f7f525760ced6c00c484-poli-160512174544/75/What-is-simultaneous-multithreading-7-2048.jpg)
![Figure 4 Hypothetical EV8 CPU Organization
Compaq claims the overall impact of adding SMT capability will be to increase the die area of the
processor portion of the EV8 device by less than 10% [8]. It is harder to gauge the extra burden
SMT imposes on the already considerable design and verification effort for an eight issue wide
superscalar processor, even one implementing a streamlined and prescient RISC architecture like
the Alpha ISA. The potential for EV6-like schedule slips in the EV8 project seems ominously
tangible if Compaq’s Alpha managers and engineers haven’t taken to heart the lessons of that
unfortunate period.
Software Implications of SMT
An obvious question to ask is how does an SMT processor offer up its multithreading capabilities to
software. In the case of the EV8, it is with an abstraction called a thread processing unit or TPU. A
TPU is essentially a single-threaded virtual processor that is presented to the lowest level of the
operating system hardware abstraction layer (HAL). The EV8’s four way SMT capabilities are
represented with four separate TPUs as shown in Figure 5.](https://image.slidesharecdn.com/xleygdkqqsklepgmekvw-signature-4b2bfabf29a67521ae81dada6f3c48b5e812df618f19f7f525760ced6c00c484-poli-160512174544/75/What-is-simultaneous-multithreading-8-2048.jpg)
![Figure 5. Software View of the EV8
Essentially the EV8 appears to software as consisting of four separate processors that share a single
set of translation lookaside buffers (TLBs) and caches. The advantages of SMT over a real four-way
chip level multiprocessor (CMP) are there is only one physical processor occupying die area and
cache coherency occurs without extra logic or overhead.
Can the EV8 execute threads from different processes simultaneously? (i.e. threads with different
address spaces). That hasn’t been disclosed but the simple answer is, it would probably be easy to
permit but it wouldn’t be desirable in practice because it could thrash the TLBs. It is easy to permit
with a mechanism called an address space number (ASN) or address space identifier (ASID). In
conventional processors an ASN is a small hardware register (typically 6 to 8 bits in size)
containing a unique value that is appended to virtual addresses prior to translation. The purpose of
doing this is to speed up context switches in a multitasking operating system by avoiding flushing
and reloading the TLB state, and flushing and/or invalidating the caches. By simply changing the
value in the ASN register during a context switch, the OS can prevent a virtual address from one
process from accidentally matching the same virtual address from a previous process in the TLB
and/or cache. In the case of an SMT it would seem natural that a separate ASN register be provided
within each thread hardware context.
Another important issue is software’s ability to synchronize threads. The Alpha uses a
synchronization mechanism based on the load-locked/store-conditional model [9]. This scheme,
commonly used by RISC architectures, uses a software based spin loop to set or wait on a
semaphore. In a conventional single or multiprocessor system this works well. But on an SMT a
spin loop is horrendously wasteful of processing resources. To solve this problem Compaq invented
a spin loop quiescing feature that allows the TPU associated with a thread executing a spin loop to
be put sleep until the associated semaphore memory location is modified. While asleep the
associated thread does not consume any processor resources. This feature adds relatively little extra
logic to EV8 because it piggybacks on existing cache coherency mechanisms.
Summary
Simultaneous Multithreading technology seems to be a match complement to the modern out-of-
order execution superscalar RISC processor. The difficult task of tracking computational results for
instructions from separate threads issuing and executing simultaneously is a natural fit with register
renaming schemes currently used to work around false register based data dependencies between
instructions and support recovery from speculated instruction execution. The problem of selecting
instructions from a group of active hardware threads for SMT issue and execution has a relatively
simple heuristic solution that provides robust performance over a wide range of workloads with
varying degrees of ILP and TLP.](https://image.slidesharecdn.com/xleygdkqqsklepgmekvw-signature-4b2bfabf29a67521ae81dada6f3c48b5e812df618f19f7f525760ced6c00c484-poli-160512174544/75/What-is-simultaneous-multithreading-9-2048.jpg)
![Research to date suggests SMT can approximately double the throughput performance of an 8
instruction-issue wide processor like EV8 for a cost in extra processor complexity equivalent to less
than 10% increased die area for the processor core. The multithreading capabilities of an SMT
processor can be accessed by software through a virtual CMP model that uses abstracted TPUs in
place of multiple physical CPUs. Existing thread synchronization mechanisms can be retained with
little impact on SMT processor performance if appropriate measures are taken to ensure threads
waiting for a semaphore do not consume a share of execution resources.
In the third and final part of this article I will examine how the performance characteristics of SMT
potentially impact EV8’s competitive posture relative to alternative design approaches like EPIC
and CMP and the implications for the future of MPU design.
Footnotes
[1] Hennessy, J., 'Processor Design and Other Challenges in the Post-PC Era', Proceedings of
Microprocessor Forum 1999, October 5, 1999, Cahners MicroDesign Resources.
[2] Slater, M., 'MicroUnity Lifts Veil on MediaProcessor', Microprocessor Report, Vol. 9, No. 14,
October 23, 1995, p. 11.
[3] Gieseke, B., 'A 600 MHz Superscalar RISC Microprocessor with Out-Of-Order Execution',
Digest of Technical Papers, ISSCC 1997, February 7, 1997, p. 176.
[4] Farkas, K. et al, 'Register File Design Considerations in Dynamically Scheduled Processors',
DECWRL Report, November 1995.
[5] Emer, J., 'Simultaneous Multithreading: Multiplying Alpha Performance', Proceedings of
Microprocessor Forum 1999, October 5, 1999, Cahners MicroDesign Resources.
[6] Lo, J. et al, 'Converting Thread-Level Parallelism to Instruction Level Parallelism via
Simultaneous Multithreading', ACM Transactions on Computer Systems, Vol. 15, No. 3, August
1997, p. 322.
[7] Tullsen, D. et al, 'Exploiting Choice: Instruction Fetch and Issue on an Implementable
Simultaneous Multithreading Processor', Proceedings of the 23rd
Annual International Symposium
on Computer Architecture, May 1996.
[8] Diefendorff, K., 'Compaq Chooses SMT for Alpha', Microprocessor Report, Vol. 13, No. 16,
December 6, 1999, p. 1.
[9] Sites, R., 'Alpha Architecture Reference Manual', Digital Press, 1992. Fundamentals of
Multithreading: http://www.slcentral.com/articles/01/6/multithreading/](https://image.slidesharecdn.com/xleygdkqqsklepgmekvw-signature-4b2bfabf29a67521ae81dada6f3c48b5e812df618f19f7f525760ced6c00c484-poli-160512174544/75/What-is-simultaneous-multithreading-10-2048.jpg)























































































