






















![Programming Languages
Variables a = 10, b = 20
c = a + b
Types
if condition:
Operators do_this()
for i in range(10):
Conditionals
do_this()
Looping
urllib.urlopen('http://yahoo.com
/').read()
Libraries
[str.lower() for str in
list_of_strings]
http://jnaapti.com/](https://image.slidesharecdn.com/dealing-with-web-scale-data-120305091902-phpapp02/85/Dealing-with-web-scale-data-23-320.jpg)











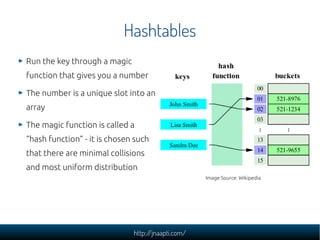


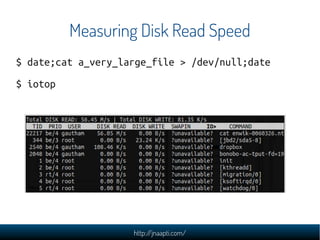













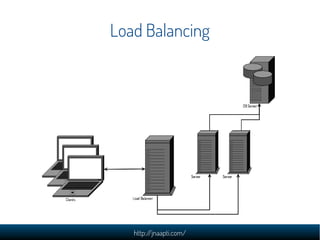


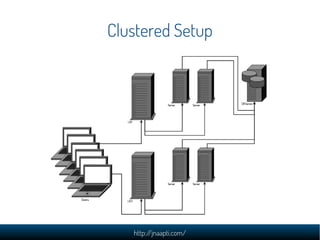
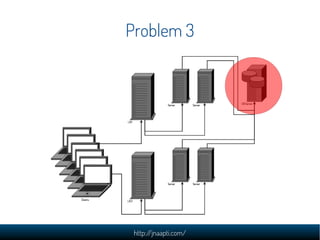


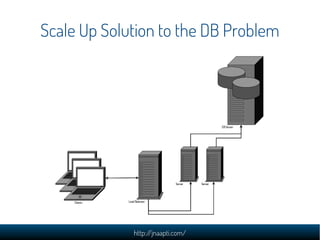































The document discusses the challenges and solutions in managing web-scale data, emphasizing the importance of understanding data storage and technology concepts. It highlights the rapid growth of data generation, the significance of programming languages, data structures, and databases, and introduces relational and NoSQL databases. The document also explores various web application design issues, such as load balancing and scalability, along with different approaches to analyzing large datasets.






































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








