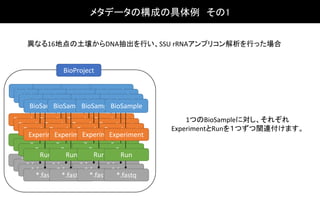
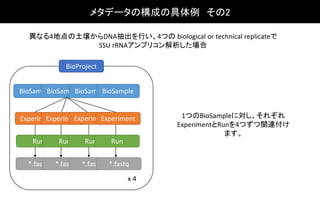
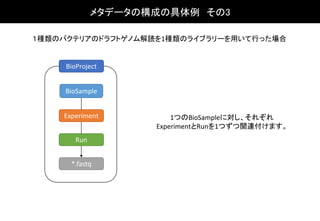
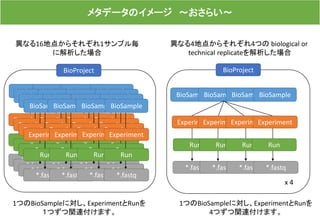
異なる4地点の土壌からDNA抽出を行い、4つの biological ortechnical replicateで
SSU rRNAアンプリコン解析した場合
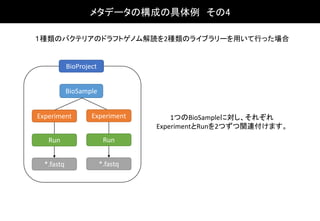
BioSampleBioSampleBioSampleBioSample
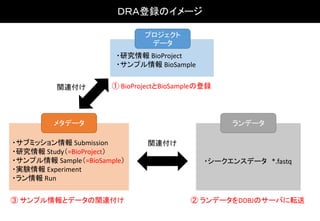
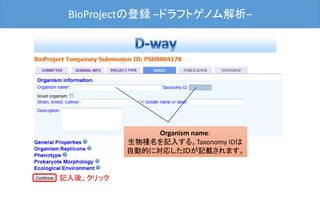
BioProject
ExperimentExperimentExperimentExperiment
Run Run Run Run
*.fastq *.fastq *.fastq *.fastq
x 4
1つのBioSampleに対し、それぞれ
ExperimentとRunを4つずつ関連付け
ます。
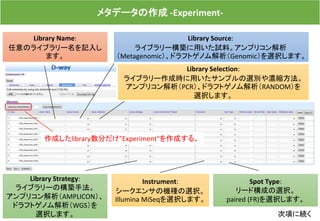
メタデータの構成の具体例 その2




![所属と公開鍵の登録
Center Full Name:
組織名を入力し,提示される候補
から選択します。
組織名を記入後、"Updata"をクリック
Center Nameが登録されると、下部に "Public
Key" が表示されます。公開鍵ファイルを参照し、
[Register public key] で公開鍵を登録します。
公開鍵の作成方法は、DDBJの"公開鍵/秘密鍵
ペアの生成"や京都大学学術情報メディアセン
ターをご覧ください。](https://image.slidesharecdn.com/ddbjallver2-150402032653-conversion-gate01/85/Ddbj-all-ver3-5-320.jpg)


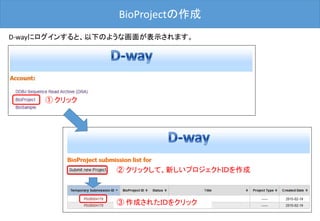
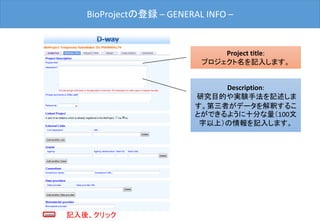


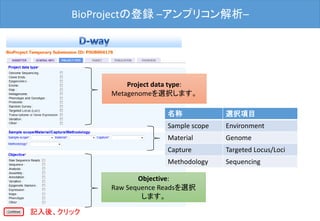
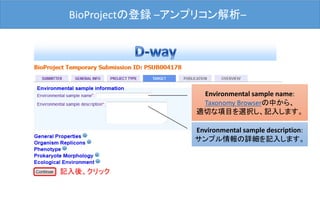

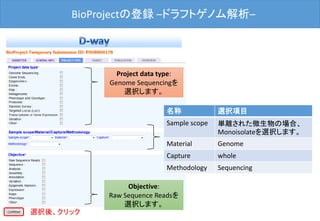

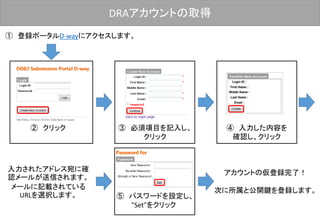
![BioProjectの登録 –OVERVIEW–
最後に[Submit]ボタンをクリックした後、D-way上で修正は出来ません。
修正される場合は、メール(bioproject@ddbj.nig.ac.jp) で申請する必
要があります。アノテータが査定を行ってから、BioProject ID を発行す
るため、少しお時間がかかります。
内容確認後、クリック](https://image.slidesharecdn.com/ddbjallver2-150402032653-conversion-gate01/85/Ddbj-all-ver3-24-320.jpg)

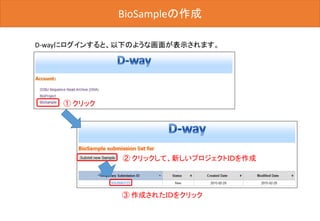

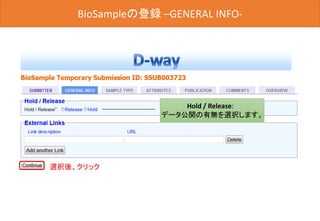





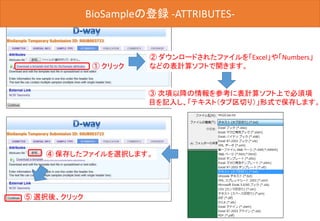




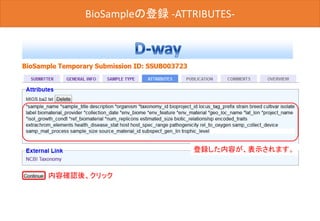
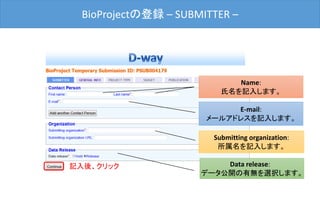
![BioSampleの登録 -OVERVIEW-
最後に[Submit]ボタンをクリックした後、D-way上で修正は出来ません。
内容を変更する場合は、メール(biosample@ddbj.nig.ac.jp) にて、お知
らせてください。アノテータが査定を行ってから、BioSample IDが発行さ
れるため、少しお時間がかかります。
内容確認後、クリック](https://image.slidesharecdn.com/ddbjallver2-150402032653-conversion-gate01/85/Ddbj-all-ver3-42-320.jpg)

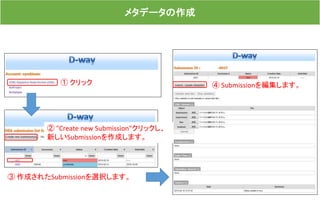




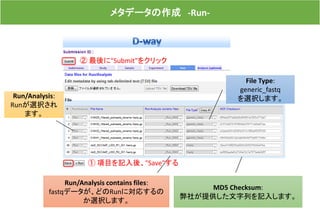
![メタデータの作成
"Validate data files"をクリックすると、登録したメタデータの
内容とランデータが一致しているか確認作業が始まります。
しばらく経った後、"data_error"が発生した場合は、[Stop validation] をクリックして、Validation 処
理を停止します。メタデータのエラー箇所を修正後、再アップロードし、再度validationを開始しま
す。エラーの原因がわからない方は、DRAチーム(trace@ddbj.nig.ac.jp)へご連絡ください。
Statusの内容
new :メタデータの投稿前
metadata_submitted :メタデータが投稿された
data_validating :データファイルのValidation中
data_error :データファイルのValidation エラー
submission_validated :メタデータとデータファイルのValidationが完了
completed :アクセッション番号が発行された
confidential :非公開
public :公開](https://image.slidesharecdn.com/ddbjallver2-150402032653-conversion-gate01/85/Ddbj-all-ver3-54-320.jpg)























![[db analytics showcase Sapporo 2018] B13 Cloud Spanner の裏側〜解析からベストプラクティスへ〜](https://cdn.slidesharecdn.com/ss_thumbnails/dbassapporo2018b13-180626013006-thumbnail.jpg?width=640&height=640&fit=bounds)




![M19_設計解析業務におけるクラウドエンジニアリングソリューションの活用と効果 [Microsoft Japan Digital Days]](https://cdn.slidesharecdn.com/ss_thumbnails/m19-211027133148-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DDBJ Challenge 2016] 機械学習コンペティションにおける予測モデリング手法の傾向](https://cdn.slidesharecdn.com/ss_thumbnails/ddbj-challenge2016baba-160713074144-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DDBJ Challenge 2016] DDBJデータ解析事例「ChIP-Atlasデータベース」の紹介](https://cdn.slidesharecdn.com/ss_thumbnails/ddbj-challenge2016oki-160715012042-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DDBJ Challenge 2016] 機械学習と予測モデルコンペティション](https://cdn.slidesharecdn.com/ss_thumbnails/ddbj-challenge2016kashima-160713073323-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DDBJ Challenge 2016] 遺伝研スーパーコンピュータのビッグデータ解析環境](https://cdn.slidesharecdn.com/ss_thumbnails/ddbj-challenge2016ishikawa-160713074628-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWSマイスターシリーズ] AWS CLI / AWS Tools for Windows PowerShell](https://cdn.slidesharecdn.com/ss_thumbnails/20140115aws-meister-regenerate-awsclipowershell-140130055421-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DDBJing34] BioProject, BioSample の紹介](https://cdn.slidesharecdn.com/ss_thumbnails/34ddbjingmukaida2-171228012818-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DDBJing29]DDBJ Sequence Read Archive (DRA) の紹介](https://cdn.slidesharecdn.com/ss_thumbnails/ddbjing29dra-140616024459-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DDBJjing34] DRA(DDBJ Read Sequence Archive) の紹介](https://cdn.slidesharecdn.com/ss_thumbnails/34ddbjingfukuda-171228013306-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DDBJing31] BioProject, BioSample, DDBJ Sequence Read Archive の紹介](https://cdn.slidesharecdn.com/ss_thumbnails/31ddbjingdrabpbs-150626071413-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

