
Download to read offline
































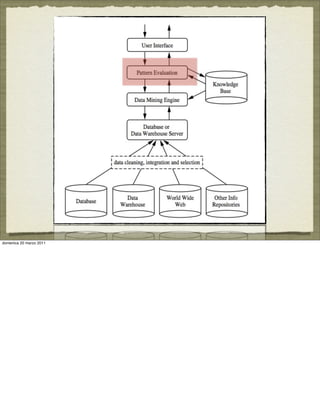

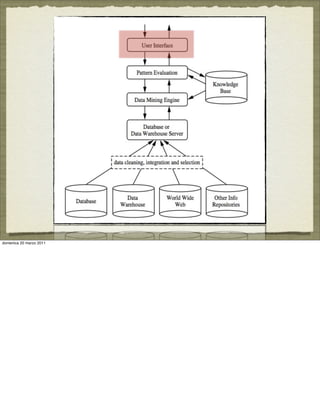






![ASSOCIATION ANALYSIS
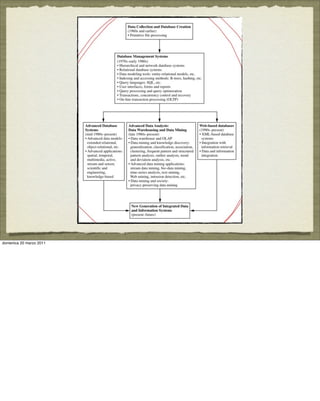
Frequent itemset mining is the simplest form of frequent
pattern mining
Example: determine which items are frequently purchased
together within the same transactions
age(X , “20...29”) ∧ income(X , “20K...29K”) buys(X , “CD player”)
[support = 2%, confidence = 60%]
domenica 20 marzo 2011](https://image.slidesharecdn.com/datamining-150731152839-lva1-app6891/85/Datamining-49-320.jpg)




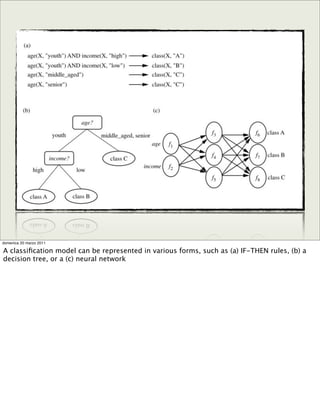










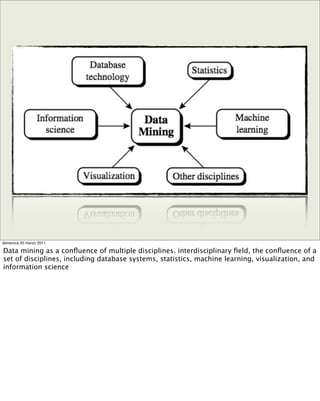







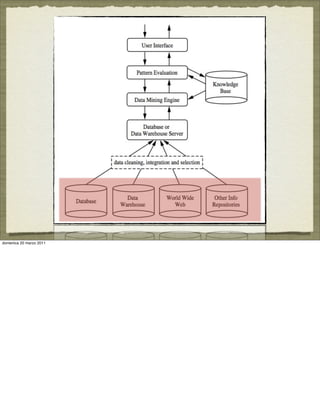
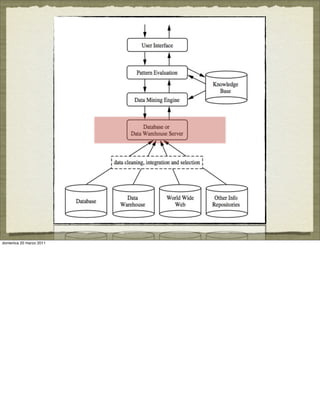
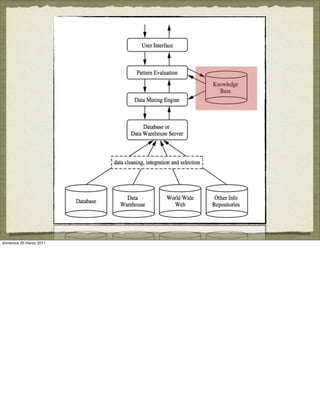
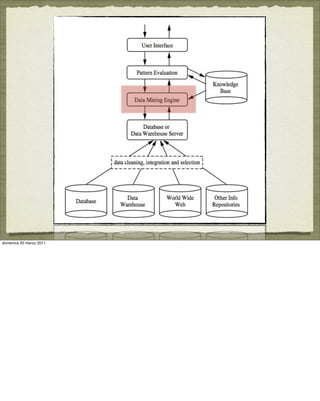
The document discusses concepts and techniques in data mining. It covers topics such as the evolution of data mining from database systems, different types of data that can be mined including relational databases, data warehouses, and the World Wide Web. It also discusses the architecture of a typical data mining system and the types of patterns that can be mined, including descriptive patterns like characterization and predictive patterns like classification and prediction. Key points made are that not all patterns are interesting and that data mining systems focus the search based on user-provided constraints and measures of interestingness.




























































































