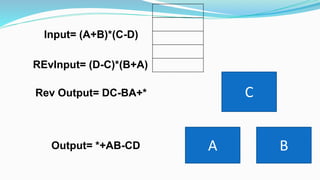
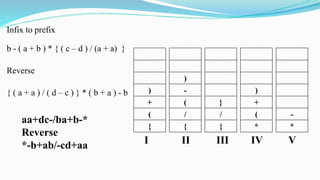
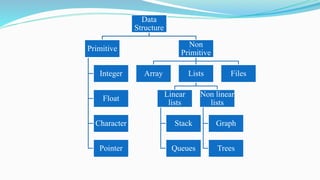
This document provides an introduction to data structures and algorithms. It discusses arrays, stacks, queues and their applications. It also covers time and space complexity analysis of algorithms. Arrays are introduced as a linear data structure for storing similar data elements. Array elements can be accessed using an index or subscript. Multi-dimensional arrays can also be implemented for storing data in rows and columns.


















![Arrays
Definition: A contiguous storage structure having same type
of elements.
a[1] a[2] ………………………………………………..a[n]
• Name of an array represents the address of the array called base address.
•There may be more than ONE Dimensional array, such as TWO Dimensional,
Three Dimensional etc.
•Two dimension array is an example of Matrices. They are represented as a[m][n],
where m is number of rows and n is number of column.](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-22-320.jpg)
![Array
⚫ Address Calculation of an Array:
->Single Dimension:
Address of first element is Base address which is also name of the array.
Address of kth element i.e a[k]
:=base address+(k-1)=addr(a)+(k-1)
->Two Dimension:Multi Dimesions array are also stored sequentially in memory,i.e in a linear fashion not like
matrices as we assume.
There are two ways to store them depending on the programming Language:
1)Row Major:In this way first all the elements of first row is stored ,then elements of second row and so on in a
linear fashion.
Eg : a[m][n]
Address of a[ j ][ k ]=addrs(a)+((j-i)n+(k-1))
2)Column Major:
Address of a[ j ][ k ]=addrs(a)+((k-1)m + (j-1))](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-23-320.jpg)



![Array Declaration
⚫ Syntax in c:
<type> <arrayName>[<array_size>]
Ex. int Ar[10];
⚫ The array elements are all values of the type <type>.
⚫ The size of the array is indicated by <array_size>, the
number of elements in the array.
⚫ <array_size> must be an int constant or a constant
expression. Note that an array can have multiple dimensions.](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-27-320.jpg)
![Array Declaration
// array of 10 uninitialized ints
int Ar[10];
-- -- --
--
Ar -- -- --
-- -- --
4 5 6
3
0 2 8 9
7
1
0 1 2 3 4 5](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-28-320.jpg)
![Subscripting
⚫ Declare an array of 10 integers:
int Ar[10]; // array of 10 ints
⚫ To access an individual element we must apply a subscript to array
named Ar.
⚫ A subscript is a bracketed expression.
⚫ The expression in the brackets is known as the index.
⚫ First element of array has index 0.
Ar[0]
⚫ Second element of array has index 1, and so on.
Ar[1], Ar[2], Ar[3],…
⚫ Last element has an index one less than the size of the array.
Ar[9]
⚫ Incorrect indexing is a common error.](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-29-320.jpg)
![Subscripting
// array of 10 uninitialized ints
int Ar[10];
Ar[3] = 1;
int x = Ar[3];
-- -- 1
--
Ar -- -- --
-- -- --
4 5 6
3
0 2 8 9
7
1
Ar[4] Ar[5] Ar[6]
Ar[3]
Ar[0] Ar[2] Ar[8] Ar[9]
Ar[7]
Ar[1]
1
-- -- --
--
--](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-30-320.jpg)
![Array Element Manipulation Ex. 3
⚫ Consider
int Ar[10], i = 7, j = 2;
Ar[0] = 1;
Ar[i] = 5;
Ar[j] = Ar[i] + 3;
Ar[j+1] = Ar[i] + Ar[0];
Ar[Ar[j]] = 12;
-- 8 6
1
Ar -- 5 12 --
4 5 6
3
0 2 8 9
7
1
Ar[4] Ar[5] Ar[6]
Ar[3]
Ar[0] Ar[2] Ar[8] Ar[9]
Ar[7]
Ar[1]
--
--
--](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-31-320.jpg)
![Array Initialization Ex. 4
int Ar[10] = {9, 8, 7, 6, 5, 4, 3, 2, 1, 0};
Ar[3] = -1;
8 7 6
9
Ar 4 3 2
5 1 0
4 5 6
3
0 2 8 9
7
1
8 7 -1
9
Ar 4 3 2
5 1 0
4 5 6
3
0 2 8 9
7
1
6 -1](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-32-320.jpg)
![Initializing arrays with random values
The following loop initializes the array myList with random values
between 0 and 99:
for (int i = 0; i < ARRAY_SIZE; i++)
{
myList[i] = rand() % 100;
}](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-33-320.jpg)
![Program with Arrays
int main()
{
int values[5]= {0,1,3,6,10};
for (int i = 1; i < 5; i++)
{
values[i] = values[i] + values[i-1];
}
values[0] = values[1] + values[4];
}](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-34-320.jpg)
![Printing arrays
To print an array, you have to print each element in the array using a
loop like the following:
for (int i = 0; i < ARRAY_SIZE; i++)
{
printf(“%d”,myList[i]);
}](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-35-320.jpg)
![Copying Arrays
for (int i = 0; i < ARRAY_SIZE; i++)
{
list[i] = myList[i];
}](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-36-320.jpg)
![Summing All Elements
Use a variable named total to store the sum. Initially total is 0. Add
each element in the array to total using a loop like this:
double total = 0;
for (int i = 0; i < ARRAY_SIZE; i++)
{
total += myList[i];
}](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-37-320.jpg)
![Finding the Largest Element
Use a variable named max to store the largest element. Initially max
is myList[0]. To find the largest element in the array myList,
compare each element in myList with max, update max if the
element is greater than max.
double max = myList[0];
for (int i = 1; i < ARRAY_SIZE; i++)
{
if (myList[i] > max) max = myList[i];
}](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-38-320.jpg)
![Finding the smallest index of the largest
element
double max = myList[0];
int indexOfMax = 0;
for (int i = 1; i < ARRAY_SIZE; i++)
{
if (myList[i] > max)
{
max = myList[i];
indexOfMax = i;
}
}](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-39-320.jpg)
![Shifting Elements
double temp = myList[0]; // Retain the first element
// Shift elements left
for (int i = 1; i < myList.length; i++)
{
myList[i - 1] = myList[i];
}
// Move the first element to fill in the last position
myList[myList.length - 1] = temp;](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-40-320.jpg)




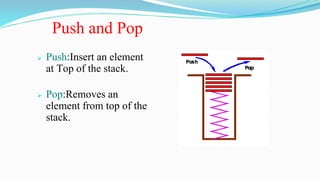



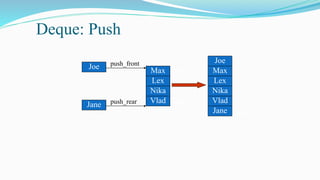
![Push and Pop
Push(Algo);
Step1:If top=Max-1,then print
Overflow and return.
Step 2:Top=Top+1
Step 3;Stack[Top]=item
Pop(Algo):
Step1:If Top=-1 then print
underflow and return
Step 2:item=stack[Top]
Step 3:Top=Top-1](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-50-320.jpg)




![⚫The data structure queue can be considered as the processing by
FIRST IN FIRST OUT technique, commonly known as FIFO.
⚫Insertion Algo:
if(rear==max-1)
then print(“Overflow)
else
rear=rear+1;
queue[rear]=item;
Queue](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-56-320.jpg)
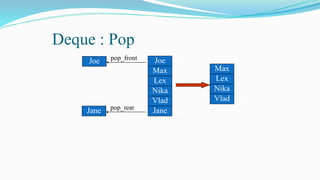
![⚫Deletion(Algo):
if front>rear print(“Underflow”)
endif
else
item=queue[front];
front=front+1;
end else
if(front==rear) then
front=0;
rear=-1;
endif
Queue](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-57-320.jpg)


![⚫CQInsert(Algo)
if((front=0 and rear=N-1)OR(front=rear+1))
then print(“FULL”)
else
//find new value of rear
if(rear=N-1)
then rear=0;
else
rear=rear+1
//insert
queue[rear]=item;](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-60-320.jpg)
![⚫CQDelete(Algo)
//CQEmpty
if(rear=-1) then print(“EMPTY”);
// Delete
item=queue[front];
//Find new value of front
//Q had only 1 element
if (front=rear) then front=0 and rear=-1
else if (front=N-1) then front=0
else
front=front+1](https://image.slidesharecdn.com/datastructuresunit1-221115164747-e929040c/85/DATA-STRUCTURES-unit-1-pptx-61-320.jpg)