Downloaded 28 times



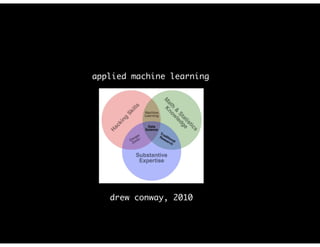
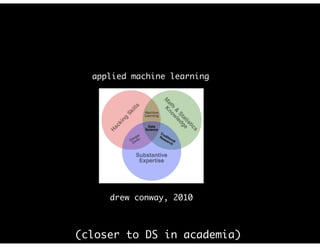









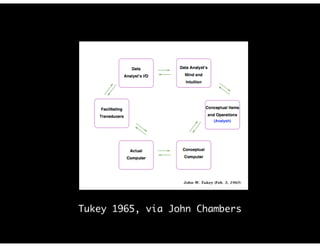











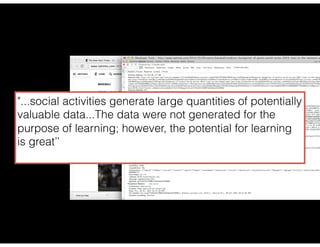
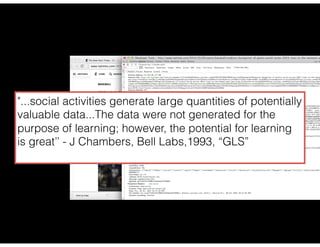
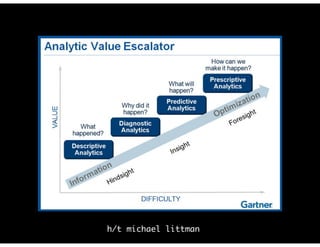
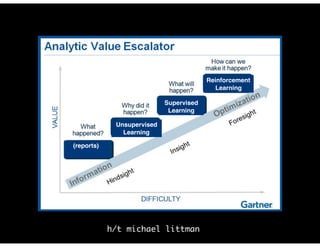


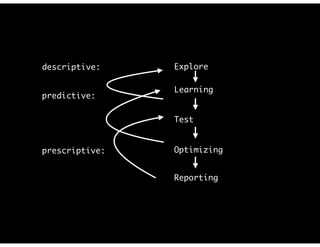

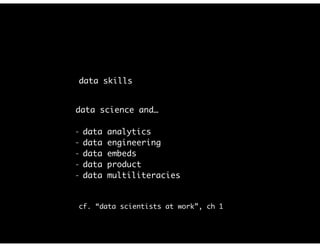
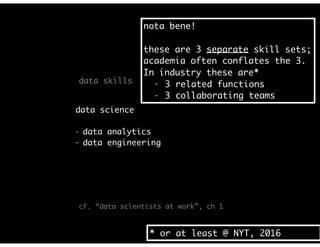



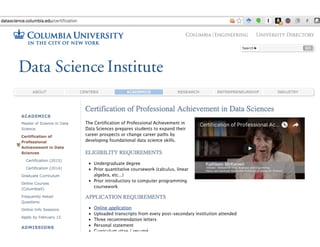



The document discusses the evolution and definitions of data science, highlighting its distinctions in academia and industry since 2009. It emphasizes the increasing relevance of data analysis and machine learning, referencing historical contributions and contemporary developments at organizations like The New York Times. Additionally, it outlines the interconnected skill sets necessary for data science, including data analytics, data engineering, and related fields.













![[데이터야 놀자 2018] 뉴욕에서 만난 데이터 사이언스](https://cdn.slidesharecdn.com/ss_thumbnails/dn2018hansjangdssnyreview-181019085619-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Introduction to Datascience [R20DS501].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontodatasciencer20ds501-251019152941-d61074d9-thumbnail.jpg?width=640&height=640&fit=bounds)










































