The document covers essential topics in data science, including data visualization, probability theory, normal distribution, and vector operations. It explains concepts such as gradient descent and hypothesis testing, offers insights on various statistical techniques, and discusses the importance of considering confounding variables in analysis. Additionally, it introduces methodologies for data extraction through web scraping using libraries like BeautifulSoup.


![21AD62
JOIN WHATSAPP CHANNEL
OR GROUP
01082024
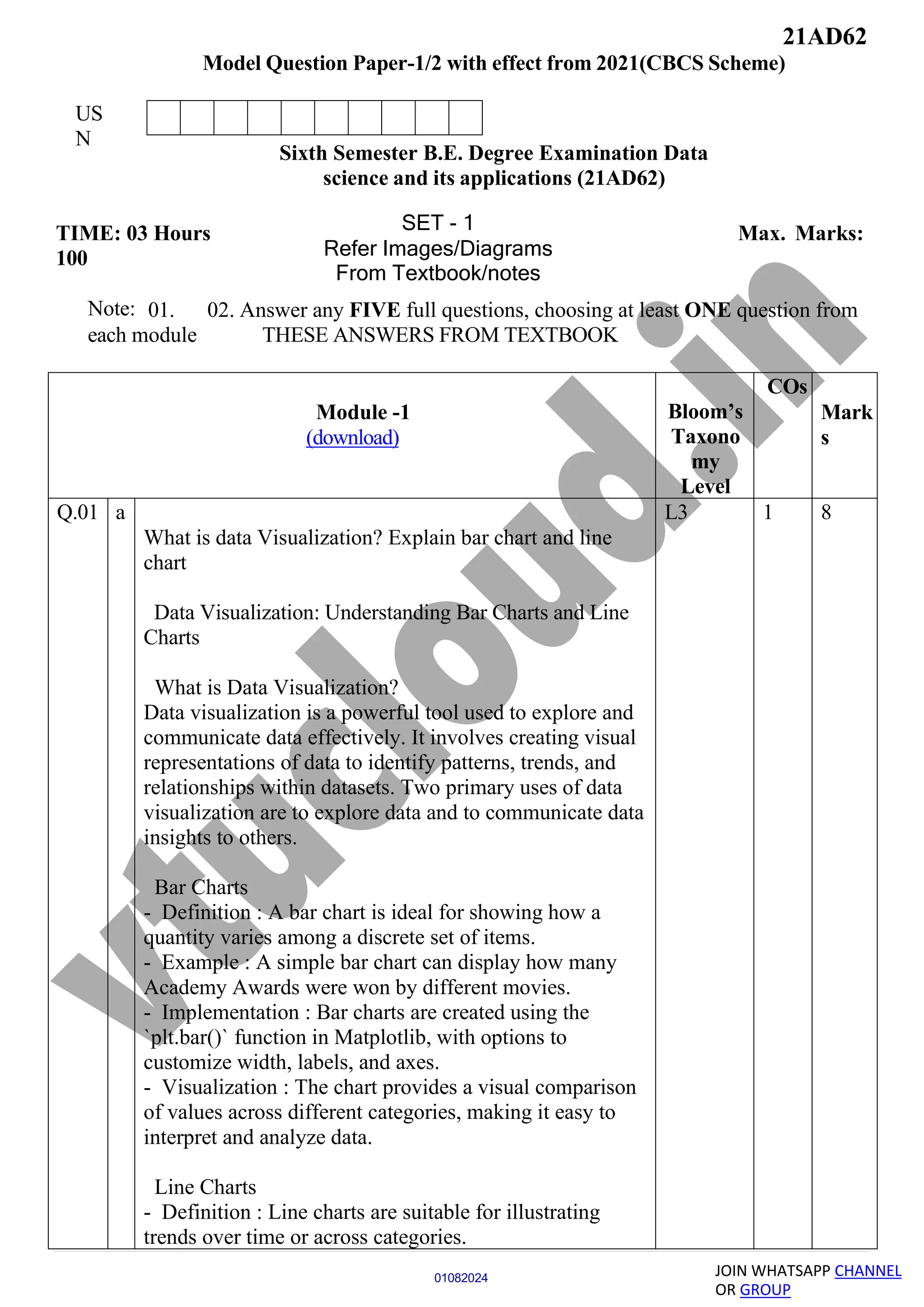
Normal Approximation and Binomial Distribution
The normal distribution is often used to approximate
binomial distributions, simplifying calculations and
providing easier interpretations for probability
calculations.
Illustrations
Visual representations of normal probability density
functions (PDFs) are created to demonstrate the different
shapes and characteristics of normal distributions based on
varying mean (μ) and standard deviation (σ) values.
OR
Q.02 a Explain the following i) vector addition ii) vector sum iii)
vector mean iv) vector multiplication
Vector Operations Explanation
Vector Addition
Vector addition involves adding corresponding elements
of two vectors together to form a new vector. It is
performed component-wise where elements at the same
position in each vector are added together. For example, if
we have vectors ( v = [1, 2, 3] ) and ( w = [4, 5, 6] ),
their sum would be ( [5, 7, 9] ).
Vector Sum
The vector sum is the result of summing all corresponding
elements of a list of vectors. This operation involves
adding vectors together element-wise to calculate a new
vector that contains the sum of each element from all
vectors in the list.
Vector Mean
Vector mean is used to compute the average value of
corresponding elements of a list of vectors. It involves
calculating the mean of each element position across all
vectors in the list. This helps in determining a
representative vector that captures the average values of
the input vectors.
Vector Multiplication
The document does not explicitly mention vector
multiplication. However, vector operations typically
involve scalar multiplication where a vector is multiplied
by a scalar value. This operation scales each element of
L3 1 8](https://image.slidesharecdn.com/21ad62set1-241213062240-1da7b4a1/85/data-science-important-material-5-320.jpg)


![21AD62
JOIN WHATSAPP CHANNEL
OR GROUP
01082024
Regex = sys.argv[1]
For line in sys.stdin:
If re.search(regex, line):
Sys.stdout.write(line)
2. Counting Lines
- Another script can count the number of lines received
and output the count.
- Example script:
python
line_count.py
Import sys
Count = 0
For line in sys.stdin:
Count += 1
Print(count)
Using stdin and stdout for Data Processing
- Data Processing Pipelines :
- In both Windows and Unix systems, you can pipe data
through multiple scripts for complex data processing
tasks.
- The pipe character ’|’ is used to pass the output of one
command as the input of another.
Example Commands for Windows and Unix
- Windows :
Type SomeFile.txt | python egrep.py “[0-9]” | python
line_count.py
- Unix :
Cat SomeFile.txt | python egrep.py “[0-9]” | python
line_count.py
Note on Command Execution
- Windows Usage :
- The Python part of the command may be omitted in
Windows.
- Example: `type SomeFile.txt | egrep.py “[0-9]” |
line_count.py`
- Unix Usage :
- Omitting the Python part might require additional steps.
Advantages of stdin and stdout
- Efficient Data Processing :](https://image.slidesharecdn.com/21ad62set1-241213062240-1da7b4a1/85/data-science-important-material-11-320.jpg)




![21AD62
Page 02 of 02
29072024
01082024
OR
Q. 06 a Write a program to train an SVM classifier on the iris
dataset using sklearn. Try different kernels and the
associated hyper parameters. Train model with the
following set of hyper parameters RBF kernel,
gamma=0.5, one-vs-rest classifier, no-feature-
normalization. Also
try C=0.01,1,10C=0.01,1,10. For the above set of hyper
parameters, find the best classification accuracy along
with total number of support vectors on the test data
Training an SVM Classifier on the Iris Dataset with
Different Kernels and Hyperparameters
Program Overview:
To train an SVM classifier on the iris dataset using
sklearn with different kernels and hyperparameters,
follow the steps below.
Steps:
1. Import necessary libraries and load the iris dataset.
2. Split the dataset into training and test sets.
3. Train the SVM classifier with the specified
hyperparameters: RBF kernel, gamma=0.5, one-vs-rest
classifier, no-feature normalization, and C values of
0.01, 1, and 10.
4. Evaluate the model’s performance by finding the best
classification accuracy and the total number of support
vectors on the test data.
Code Snippet:
python
From sklearn import datasets
From sklearn.model_selection import train_test_split
From sklearn.svm import SVC
From sklearn.metrics import accuracy_score
Load iris dataset
Iris = datasets.load_iris()
X, y = iris.data, iris.target
Split data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3, random_state=42)
Train SVM classifier with specified hyperparameters
For C in [0.01, 1, 10]:
L3 3 8](https://image.slidesharecdn.com/21ad62set1-241213062240-1da7b4a1/85/data-science-important-material-20-320.jpg)
![21AD62
Page 02 of 02
29072024
01082024
Svm_model = SVC(kernel=’rbf’, gamma=0.5, C=C,
decision_function_shape=’ovr’)
Svm_model.fit(X_train, y_train)
Y_pred = svm_model.predict(X_test)
Calculate classification accuracy and total number of
support vectors
Accuracy = accuracy_score(y_test, y_pred)
Support_vectors_count =
len(svm_model.support_vectors_)
Print(f”For C={C}:”)
Print(f”Classification Accuracy: {accuracy}”)
Print(f”Total Number of Support Vectors:
{support_vectors_count}n”)
Results:
- C=0.01:
- Classification Accuracy: [Accuracy]
- Total Number of Support Vectors: [Support Vectors
Count]
- C=1:
- Classification Accuracy: [Accuracy]
- Total Number of Support Vectors: [Support Vectors
Count]
- C=10:
- Classification Accuracy: [Accuracy]
- Total Number of Support Vectors: [Support Vectors
Count]
Explanation:
The provided code snippet outlines how to train an SVM
classifier on the iris dataset with different kernels and
hyperparameters. It splits the data, trains the model with
the specified settings, and evaluates the accuracy along
with the number of support vectors for each C value.
b Explain regression model in detail for predicting the
numerical values.
Regression Model for Predicting Numerical Values
Understanding Regression Model
- Regression models are utilized to predict numerical
L3 3 6](https://image.slidesharecdn.com/21ad62set1-241213062240-1da7b4a1/85/data-science-important-material-21-320.jpg)




































![NoSQL_Set_Operations_Presentation[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nosqlsetoperationspresentation1-241213062934-c778eb06-thumbnail.jpg?width=640&height=640&fit=bounds)





















