Download to read offline















![{ #quarantine, #quarantine, #brexit, #brexit, #alyonalyona, #quarantine, #tesla, #tesla, #quarantine,
#brexit, #oscar, #quarantine -> }
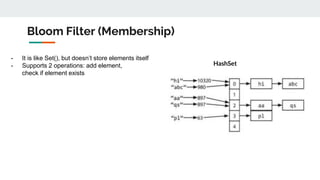
Count-Min Sketch (Frequency)
0 1 2 3 4 5 6 7 8 9
h1 0 0 0 0 6 0 1 0 5 0
h2 0 0 3 0 0 1 0 6 0 2
How many times #tesla?
h1(x) = MurmurHash3(tesla) % 10 = 8
h2(x) = FNV1(tesla) % 10 = 9
Final answer = min(h1[8], h2[9]) = min(5, 2) = 2](https://image.slidesharecdn.com/datamonstersprobablisticdatastructures-200430091550/85/Data-monsters-probablistic-data-structures-27-320.jpg)



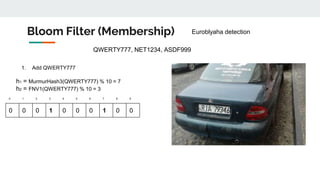
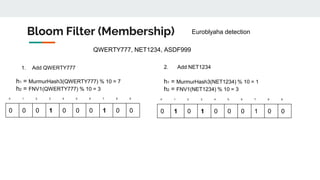
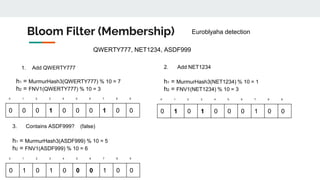
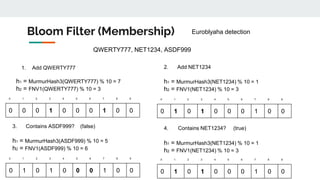
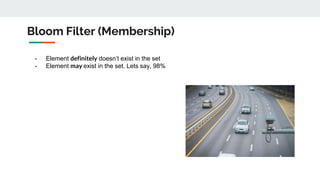
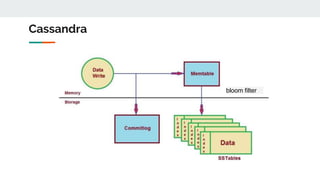
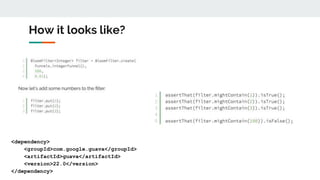
The document discusses various probabilistic data structures, including Bloom filters, count-min sketches, and hashing techniques, highlighting their use cases in data engineering. It outlines their applications in membership checking, frequency counting, cardinality estimation, and similarity detection, showing how they optimize performance and resource usage. The document serves as an introduction to these structures, emphasizing their importance in managing large datasets effectively.






















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
