#2 안녕하세요.
"From D To D" 강의를 진행하게 된 양승준이라고 합니다.
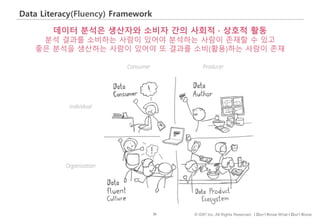
Data Literacy가 데이터를 해석하는 소양이라면 Data Fluency는 Data Literacy를 활용하여 데이터에 좋은 질문을 하고, 유용한 패턴을 발견하여 분석결과를 실용적으로 본인 업무에 활용하는 능력이라고 할 수 있겠습니다.
본 강의를 통해 데이터 분석이 막상 해보면 그닥 어렵지 않다는 것, 그리고 Data Literacy를 본인이 하는 일에 유용하게 사용할 수 있다.는 두가지 메세지를 전달해 드리려고 합니다.
#5 파도타기를 즐기려면
마음: 서핑하고 싶은 마음이 있어야 함. (동경. 호기심, 강요 등등) – 어렵지 않다(할 수 있다). 재밌다(유용하다) -> 자기 효능감
파도가 있어야 함. (이건 주어지는 것이지만 작은 파도는 또 작은 파도대로 즐길 수 있음)
도구가 있어야 함. (파도의 특성과 자기 실력에게 맞는 도구가 있음. 초보자용 롱보드부터 쇼트보드 등. 심지어 Bodysurf라는 것도 있음)
도메인 지식: 데이터에 담기지 않는 것들. 데이터가 수집되고 활용되는 맥락. 바닥에 암초는 없는지 바닥의 지형; 저기서 왜 파도가 솟구치는지;, 뛰어들어도 되는지
파도 타기 기술을 익혀야 함. (파도를 읽는 법 + 자기에게 맞는 서프보드를 선택하고 사용하는 법 등)
#6 Top-Down 방식은 강의의 방법이기도 하지만 데이터 분석에 대해 여러분들이 공부하는 효과적인 방법이기도 합니다.
이론적인 지식부터 시작하기보다는 본인이 지속적인 동기를 유지할 수 있는 주변의 흥미로운 주제를 발굴해서 실제 문제를 – 제한적 지식으로 – 해결하면서 부족한 부분을 채워나가는 게 바람직
참고: https://machinelearningmastery.com/youre-wrong-machine-learning-not-hard/
#7 [시작]
이번 강의에서는 데이터에 좋은 질문을 하는 방법에 대해 이야기 나누어 보겠습니다.
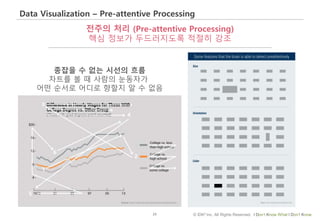
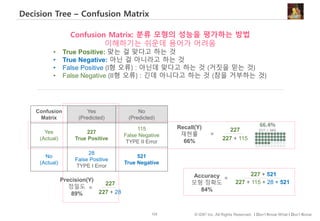
#23 효과적인 데이터 시각화와 관련된 이론 중에 전주의 처리라는 개념이 있습니다.
곰 – 강력한 대비를 통해 곰의 존재가 두드러짐
이빨만 보임 – 손가락은 주의깊게 봐야 인식됨
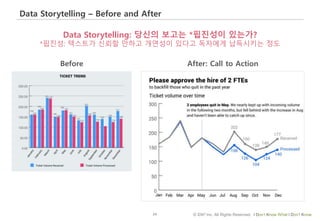
#25 시각화는 종종 Storytelling의 새로운 형식으로 거론되기도 한다.
데이터 스토리텔링이 전통적(서사적) 스토리텔링과 비교해서 더 큰 의미를 가질 수 있는 경우는 전통적 스토리텔링의 주된 소재가 되는 일화(anecdotal storytelling)의 일회성/우발성을 극복하고 데이터를 통해서 발견한 뻔하지 않고 유용한 패턴과 구조를 이야기할 때이다.
http://blog.visme.co/data-storytelling-tips/
#26 [마지막]
이번 강의에서는 데이터 분서의 과정과 좋은 질문을 하는 일의 주요성에 대해 알아봤습니다.
다음 강의에서는 Data Literacy에 대해 좀 더 깊은 이야기를 나누어 보겠습니다.
감사합니다.
#27 [강의 시작]
이번 강의에서는 Data Literacy가 무엇이고 현업들에게 Data Literacy가 왜 필요한지에 대해 이야기를 나누어 보겠습니다.
#28 Around 3000 BC, the cuneiform script was developed by the Sumerians, who lived in what is now Iraq. This script was a series of pictographs inscribed on clay tablets using a stylus – a sharpened tip of a reed.
One site, the city of Uruk, surpassed all others as an urban center surrounded by a group of secondary settlements. It covered approximately 250 hectares, or .96 square miles, and has been called “the first city in world history.” The site was dominated by large temple estates whose need for accounting and disbursing of revenues led to the recording of economic data on these clay tablets.
Initially, these pictographs were laid out in vertical columns, but later they were read from left to right.
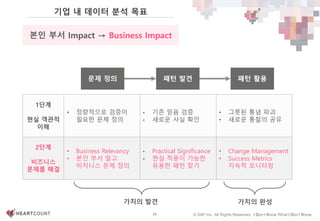
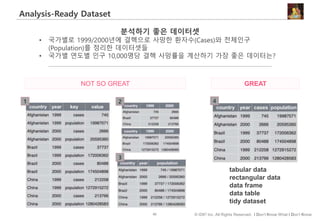
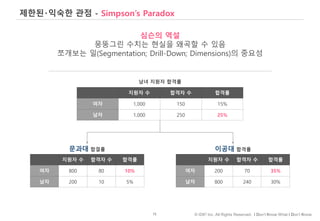
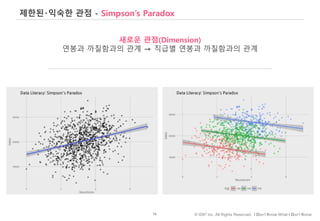
#29 데이터 분석가와 데이터 소비자의 분리
소통의 문제
데이터 마트, 파이프는 표준화 가능.
The Last Mile은 personal and organization-specific.
Personal and Organizational Data Literacy.
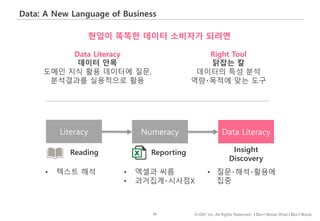
#31 데이터로 읽고 쓰고 듣고 말하고
http://www.juiceanalytics.com/writing/4-components-of-the-data-fluency-framework
#34 [강의 끝]
이것으로 Data Literacy에 대한 강의을 마치겠습니다.
다음 강의는 Data Understanding이라는 주제로 주어진 Data를 요모조모 살펴보고 요약하고 데이터의 모양과 변수 간 관계 대해 이야기하는 내용을 다루어 보겠습니다.
감사합니다.
#35 현실: we can never say what it is…we can only say things about reality
통찰력: 남들은 눈치 채지 못하는 평범한 단서에서 더 큰 무언가를 이끌어내는 능력
https://medium.com/towards-data-science/i-have-data-i-need-insights-where-do-i-start-7ddc935ab365
#36 [시작]
이번 강의는 Data Understanding 주제의 첫번째 소강의입니다.
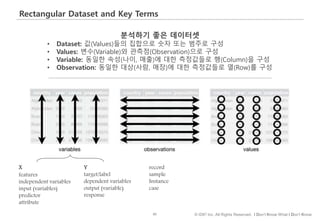
분석하기 좋은 데이터셋, 데이터의 종류, 변수 가공에 대해 이야기를 나누어 보겠습니다.
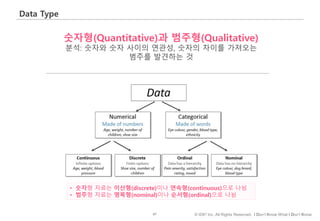
#48 플라토나이징 platonizing…사물을 분류하는 인간의 강박적 행동 (Nassim Taleb: 블랙 스완)
data (명목 자료): nominal data는 여러 categories(예, 청팀, 백팀, 홍팀)들 중 하나의 이름에 데이터를 분류할 수 있을 때 사용된다. 평균을 계산하는 것이 의미 없고 (백팀과 홍팀의 평균은 연분홍팀?) 비율로는 표현해도 된다. (청팀: 33%, 백팀 33%, 홍팀 34%)
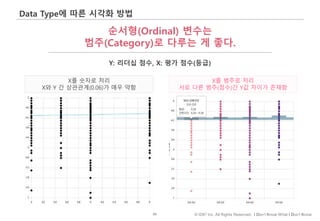
ordinal data (순서 자료): category에 순서가 있는 경우 ordinal data라고 한다. 청팀이 이길 가능성을 묻는 경우 그 답변을 “A. 매우 높다. B. 높다. C. 중립, D. 낮다. E. 매우 낮다."로 설계할 수 있다. nominal data와 마찬가지로 counting을 하고 비율로 표현해도 좋다. (매우 높다: 33%, 높다: 19%…)
#54 The decision to examine averages or to measure variation is rooted in philosophical ideologies that governed the thinking of statisticians, natural philosophers and scientists throughout the 19th century. The emphasis on statistical averages was underpinned by the philosophical tenets of determinism and typological ideas of biological species, which helped to perpetuate the idea of an idealized mean. Determinism implies that there is order and perfection in the universe …
The typological concept of species, which was the dominant thinking of taxonomists,* typologists and morphologists until the end of the 19th century, gave rise to the morphological concept of species. Species were thought to have represented an ideal type.Magnello, Eileen. Introducing Statistics: A Graphic Guide (Introducing...) (Kindle Locations 155-157). Icon Books Ltd. Kindle Edition.
The presence of an ideal type was inferred from some sort of morphological similarity, which became the species criterion for typologists. This could have had the effect of creating a proliferation of species since any deviation from the type would have led to the classification of a new species.Magnello, Eileen. Introducing Statistics: A Graphic Guide (Introducing...) (Kindle Locations 158-160). Icon Books Ltd. Kindle Edition.
#55 The decision to examine averages or to measure variation is rooted in philosophical ideologies that governed the thinking of statisticians, natural philosophers and scientists throughout the 19th century. The emphasis on statistical averages was underpinned by the philosophical tenets of determinism and typological ideas of biological species, which helped to perpetuate the idea of an idealized mean. Determinism implies that there is order and perfection in the universe …
The typological concept of species, which was the dominant thinking of taxonomists,* typologists and morphologists until the end of the 19th century, gave rise to the morphological concept of species. Species were thought to have represented an ideal type.Magnello, Eileen. Introducing Statistics: A Graphic Guide (Introducing...) (Kindle Locations 155-157). Icon Books Ltd. Kindle Edition.
The presence of an ideal type was inferred from some sort of morphological similarity, which became the species criterion for typologists. This could have had the effect of creating a proliferation of species since any deviation from the type would have led to the classification of a new species.Magnello, Eileen. Introducing Statistics: A Graphic Guide (Introducing...) (Kindle Locations 158-160). Icon Books Ltd. Kindle Edition.
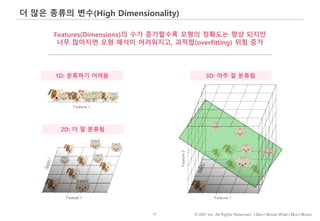
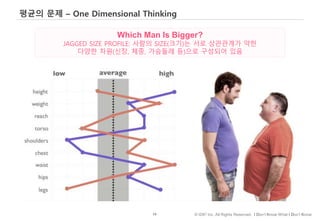
#58 Our minds have a natural tendency to use a one-dimensional scale to think about complex human traits, such as size, intelligence, character, or talent. If we are asked to assess a person’s size, for example, we instinctively judge an individual as large, small, or an Average Joe. If we hear a man described as big, we imagine someone with big arms and big legs and a big body—someone who is large all over. If a woman is described as smart, we assume she is likely good at solving problems across a wide range of domains, and is probably well educated, too. During the Age of Average, our social institutions, particularly our businesses and schools, have reinforced our mind’s natural predilection for one-dimensional thinking by encouraging us to compare people’s merit on simple scales, such as grades, IQ scores, and salaries.18 But one-dimensional thinking fails when applied to just about any individual quality that actually matters—and the easiest way to understand why is to take a closer look at the true nature of human size. The previous image portrays the measurements of two men on nine dimensions of physical size, the same dimensions analyzed by Gilbert Daniels in his breakthrough study of pilots.
#59 Our minds have a natural tendency to use a one-dimensional scale to think about complex human traits, such as size, intelligence, character, or talent. If we are asked to assess a person’s size, for example, we instinctively judge an individual as large, small, or an Average Joe. If we hear a man described as big, we imagine someone with big arms and big legs and a big body—someone who is large all over. If a woman is described as smart, we assume she is likely good at solving problems across a wide range of domains, and is probably well educated, too. During the Age of Average, our social institutions, particularly our businesses and schools, have reinforced our mind’s natural predilection for one-dimensional thinking by encouraging us to compare people’s merit on simple scales, such as grades, IQ scores, and salaries.18 But one-dimensional thinking fails when applied to just about any individual quality that actually matters—and the easiest way to understand why is to take a closer look at the true nature of human size. The previous image portrays the measurements of two men on nine dimensions of physical size, the same dimensions analyzed by Gilbert Daniels in his breakthrough study of pilots.
#60
통계학자이고 우생학자 였던 프란시스 겔톤
여러 사장을 겹쳐서 한장으로 표현하는 합성하는 초상화 기법의 전문가…
해당 기법을 통해 범죄자 얼굴의 공통적 특성
http://galton.org/composite.htm
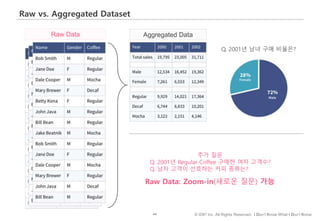
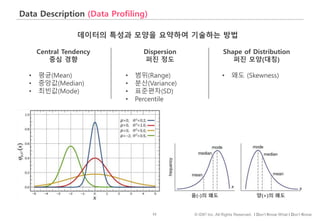
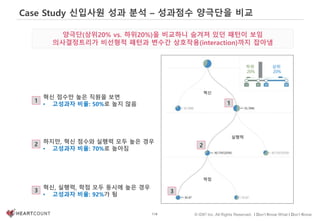
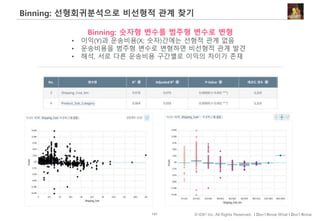
#61 평균점수를 다룰 때 주의할 점을 하나 더 살펴보겠습니다.
고객의 응답점수와 실제 구매로 이어질 확률 간 선형적 관계가 있다면 A 세그먼트가 더 좋은 타겟 세그먼트일수도 있겠습니다.
하지만, 둘 간에 분홍색처럼 비선형적인 관계가 있다면 평균이 높은 세그먼트가 아니라 확률을 최대화할 수 있도록 5점으로 답변한 사람이 많은 세그먼트를 고르는 것이 효과적
이럴때는 5점 응답한 사람에게 가중치를 부여해서 가중평균을 계산할 수도 있습니다.
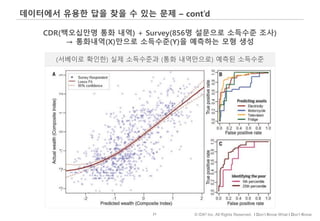
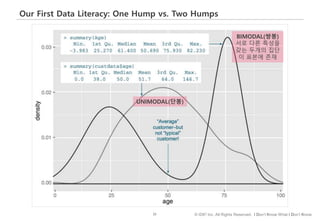
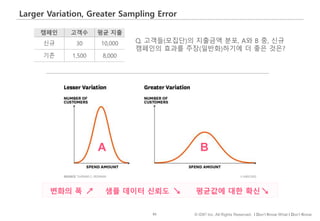
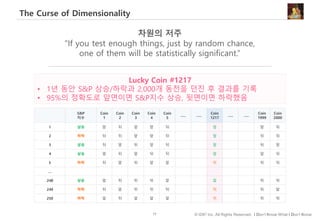
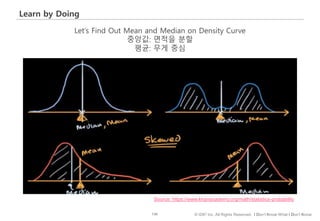
#66 이번에는 데이터가 퍼져있는 정도, 즉 분산에 따라 평균의 해석이 어떻게 달라질 수 있나 살펴보겠습니다.
왼쪽 표는 신규캠페인과 기존캠페인에 노출된 고객수와 일인당 평균 지출액입니다.
신규 캠페인에 노출된 고객이 기존 캠페인보다 2,000원 더 지출한 걸로 나오고요.
다만, 신규 캠페인에 노출된 고객의 수가 30명으로 크지는 않아 신규캠페인이 정말 효과적인지, 아니면 운이 좋아 지출금액 평균이 높게 나온 건지 판단하기 애매합니다.
주어진 상황에서 기존 고객들 전체(즉, 모집단)의 지출금액 분포가 아래 A와 B 두가지 형태로 존재할 수 있다 가정했을 때,
A, B중 어떤 분포가 신규캠페인의 효과를 주장하기에 더 좋은 모양일까요?
여기서는, 통계적 유의성 검사를 수행하지 않고 모양만 보고 판단을 해보도록 하겠습니다.
정답은 A인데요. 그 이유는 B 분포의 경우, 지출금액 변화의 폭이 넓고, 이 경우 극단적인 값이 샘플에 포함될 확률이 높아지고, 따라서 샘플데이터의 대표성이 떨어지게 됩니다.
달리 표현하면, 극단적인 값들이 많이 존재하는 경우 – 즉, 데이터가 넓게 퍼져있는 경우 - 평균의 대표성을 주장하기 어렵다는 걸 기억하면 좋겠습니다.
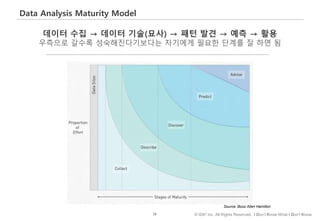
#69 이번에는 우리가 영향학자라고 잠시 상상해 봅시다. 음식의 종류를 구분하는 최선의 방법이 무엇일까요?
음식에 포함된 비타민 함유량으로 음식을 구분할 수 있을까요? 아니면 단백질 성분을 사용하는 것이 효과적일까요?
만약 주어진 변수를 사용하여 데이터를 효과적으로 구분할 수 있다면, 데이터에 숨어있는 클러스터나 범주를 발견하게 됩니다.
예를 들어 육류와 채소를 분류하는 최선의 방법을 알게될 수도 있고, 채소류 내에서 더 정교하게 채소의 하위 종류를 구분할 수도 있습니다.
문제는 아이템들을 분류하기 위해 주어진 변수를 어떻게 가공하고 활용하느냐가 되겠습니다.
우선, 비타민 C 성분을 활용할 수 있겠습니다. 비타민 C는 야채에는 있지만 고기에는 없으니 첫번째 칼럼과 같이 채소와 고기를 구분할 수 있습니다. 다만, 고기는 한점에 겹쳐서 나타나게 되겠죠.
고기류 아이템들이 퍼지도록 지방성분 함량을 사용하면 될 거 같은데요. 비타민과 지방은 서로 다른 단위로 측정되기 때문에 두 변수를 결합하기 전에 표준화해야 합니다.
표준화하는 여러가지 방법이 있지만 Percentile Rank을 사용하면 표준화하는 효과, 즉 변수들이 동일한 단위를 같게 되서, 변수간 연산이 가능해집니다.
#70 경마는 정확한 예측이 어려운 시장, 예측이 잘 되면 큰 돈을 벌 수 있는 시장
메이저 경주 3곳에서 모두 우승한 삼관마 - Kentucky Derby, the Preakness, and the Belmont Stakes
Jeff Seder: 평생을 경주마를 연구한 경마 경매 컨설턴트 – 이 말을 팔려거든 차라리 집을 팔아라
말의 온갖 특성 - 배변 특성, 콧구멍 크기, gait analysis(걷고 달리는 특성) - 과 경마에서 우승할 확률 간의 관계를 연구
우승을 점칠 수 있는 하나의 특성을 발견…좌심실의 크기
좋은 변수란 궁금한 변수를 잘 설명하고 예측할 수 있어야 하고, 여기에 더해 해당 변수로 큰 돈을 벌려면, 해당 변수를 자기 혼자만 알아야 하겠습니다.
The traditional way of predicting horse success, the data tells us, leaves plenty of room for improvement.’
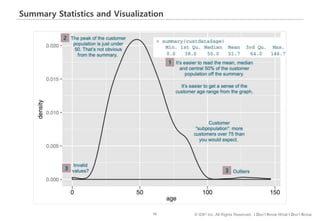
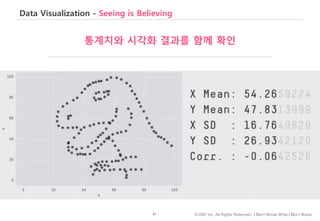
#71 이번에는 고객의 나이를, 통계적 요약값과 분포를 시각화한 차트를 함께 살펴보겠습니다.
레코드 전체의 평균이나 중앙값을 확인하는 것은 요약된 통계값을 직접 보면 바로 확인할 수 있습니다.
반면, 빈도가 가장 높은 나이값, 즉 꼭지점이 50세 바로 아래에 있다든지, 100세가 넘는 데이터 값이 존재한다는 것은 시각화한 차트를 통해서만 확인할 수 있습니다.
물론, 100세가 넘거나 아주 작은 나이가 잘못 측정되거나 기록된 값 – 이상치 – 인지 아니면 실제로 존재하는 하위그룹인지는 해당 업무 담당자에게 확인을 하거나 별도의 방법으로 확인을 해야 알 수 있겠습니다.
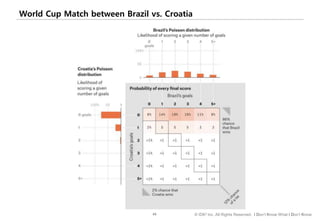
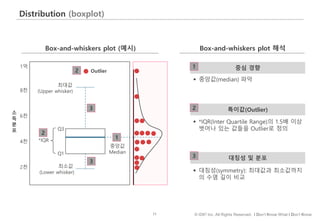
#72 이번에는 분포를 나타내는 가장 대표적인 방법인 박스플롯에 대해 살펴보겠습니다.
박스플롯은 데이터의 분포를 상자와 수염으로 표현한다고 해서 박스 & 위스커 플롯이라고도 하는데요.
화면의 박스플롯은 우측 핑크 박스 안의 소득분포를 표현한 것인데 함께 살펴보겠습니다.
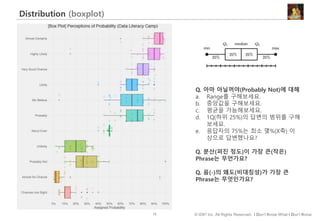
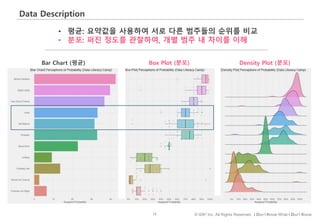
#74 이번에는 확률을 나타내는 다양한 영어표현들에 대해 사람들이 부여한 0~100 사이의 확률에 대한 데이터를 바차트와 박스플롯으로 표현할 내용을 살펴보겠습니다.
[끝]
이것으로 Data Understanding 주제의 두번째 소강의를 마치겠습니다.
다음 강의에서는 평균을 활용할 때 주의할 점, 데이터 시각화, 상관관계에 대해 이야기를 나누도록 하겠습니다.
#75 [시작]
Data Understanding 주제의 세번째이자 마지막 소강의를 시작하겠습니다.
이번 강의에서는 평균을 활용할 때 주의할 점, 데이터 시각화와 데이터 스토리텔링, 상관관계, 인과관계 등에 대해 이야기를 나누도록 하겠습니다.
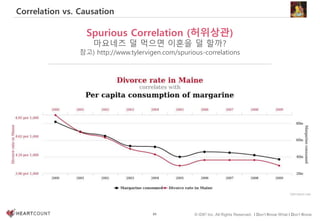
#77 http://ftp.cs.ucla.edu/pub/stat_ser/r414.pdf
http://vudlab.com/simpsons/
n 1973, the University of California-Berkeley was sued for sex discrimination. The numbers looked pretty incriminating: the graduate schools had just accepted 44% of male applicants but only 35% of female applicants. When researchers looked at the evidence, though, they uncovered something surprising:
If the data are properly pooled...there is a small but statistically significant bias in favor of women.
(p. 403)It was a textbook case of Simpson's paradox.
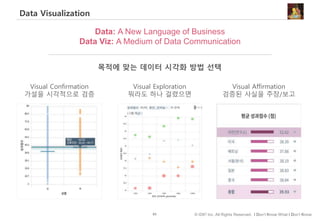
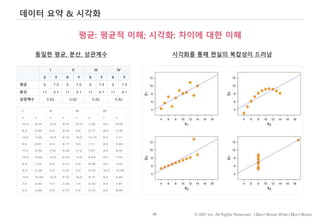
#82 데이터 수집은 현실 세계를 sampling(추상화)하는 것이고, 데이터 시각화는 이런 추상화된 데이터에 대한 추가적인 추상화(abstraction)이다. 추상화의 과정에서 정보는 필연적으로 삭제/압축될 수밖에 없다.
사용자(audience)가 시각화에 사용된 시각적 신호(visual cues)를 해석할 수 없다면 시각화가 아무리 예쁘게 표현되었다 한들 실패한 Data Viz.이다.
달리 말하자면 데이터 시각화는 의미를 전달하기 위한 도구이고, 그렇기 때문에, 매체입니다..
Data Visualization이 데이터의 의미를 전달하는 매체로서 기능하기 위해서는 기본적인 시각화 문법을 숙지하는 것이 중요하다.
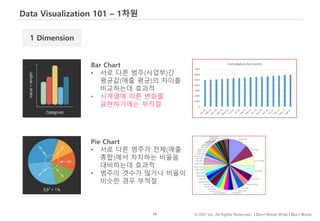
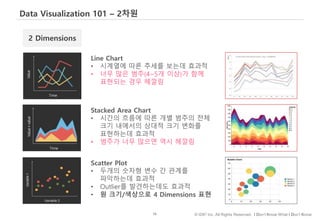
평균을 비교할 땐 바차트
관계를 나타낼 땐 스캐터플롯
그외 분포나 구성을 나타내는데 효과적이라 오랜 연구를 통해 입증된 방법이 있습니다.
이런 기본적인 시각화 문법에 대한 지식에 더해 시각화할 때 항상 아래 질문을 염두에 두자.
- 데이터를 통해 알고 싶은 게 무엇인가?
- 알고 싶은 걸 잘 알기 위해 어떤 시각화 방법이 효과적인가?
- 알고 싶은 것이 잘 표현되었나? 시각화 방법이 적절했나?
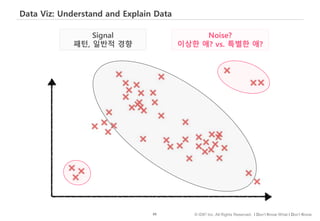
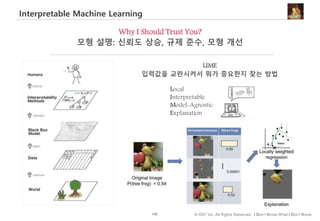
#84 스스로 다양한 가설을 검증하는 경우 – 남 녀 간 성과점수에 차이의 존재하냐는 가설의 경우, 평균과 함께, 분포, 평균의 신뢰구간 등을 비교
목적없이 탐험하고, 데이터에 대한 전체적 감을 잡는 게 목적이라면 생각의 속도로 데이터를 시각화할 수 있는 자유도가 높은 도구를 사용하는 게 좋고
발견한 패턴을 보고할 때는 메세지가 선명하게 들어나는, 그리고 수용자의 차트 해석 능력이나 조직의 보고 양식을 고려한 시각화 방법
#94 [시작]
안녕하세요, . 이번 강의에서는 기계학습과 기업 내 의사결정이라는 주제를 가지고 이야기를 나누어 보겠습니다.
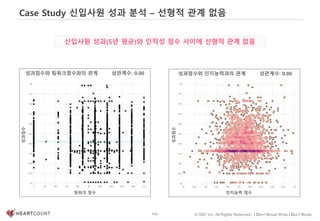
#95 지금까지의 강의는 데이터 분석의 주요기술 중 데이터의 특성과 모양을 요약하거나, 시각적 분석을 통해 변수 간 관계를 확인하는 것에 관한 내용이었습니다.
이번 강의에서는 데이터에서 발견한 질서를 통계적 또는 기계학습 알고리즘을 사용하여 일반화하여 모형에 담는 내욜을 다루겠습니다.
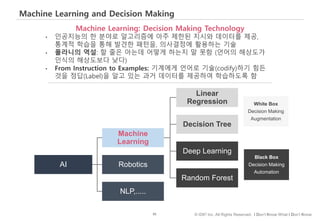
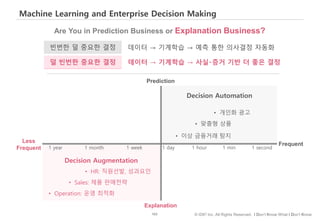
#96 기계학습은 의사결정 기술입니다.
계통학적으로 이야기하자면 기계학습은 인공지능의 한 분야로 알고리즘에 아주 제한된 지시와 데이터를 제공, 통계적 학습을 통해 발견한 패턴을, 의사결정에 활용하는 기술
여기서 제한된 지시라는 것은, 과거의 programing이 우리가 문제 해결 과정, 또는 작업 절차를 언어적 형태로 기술하고 정의할 수 있는 것을 – 즉, codify가능한 것을, 기계가 지치고 않고 빠르게하도록 했다면
지금은, 언어로 기술할 줄 모르는 것을 충분한 예제를 제시한 후 기계가 귀납적 추론을 통해 학습하도록 함.
폴라니의 역설: 할 줄은 아는데 어떻게 하는지 말 못하는 상황을 지칭. 인간의 - 인식 능력 (사진속에서 내얼굴을 찾고, 음성을 인식하고 하는 것들이 – 우리가 어려움 없이 곧잘 하지만 어떻게 하는지는 말로 잘 설명 못하는 대표적인 것들이라 할 수 있겠습니다.
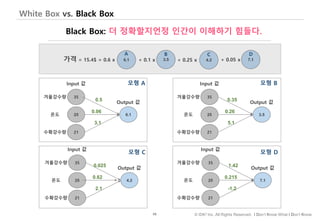
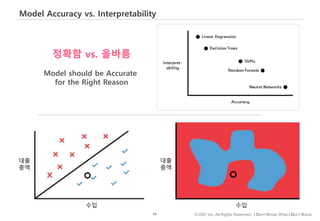
기계학습 알고리즘은, 모형의 내부 작동방식 – 즉, 학습한 패턴이 – 사람의 직관적 해석이 가능한지 여부에 따라 화이트박스, 블랙박스로 구분하고 있습니다.
Polanyi’s Paradox: We can know more than we can tell, i.e. many of the tasks we perform rely on tacit, intuitive knowledge that is difficult to codify and automate.
우리는 말할 수 있는 것보다 많이 않다. (인식. 물체를 인식하고 바둑에서 전체 판을 읽고 다음 수를 두는 전략을 짜고)
we humans know more than we can tell: We can’t explain exactly how we’re able to do a lot of things — from recognizing a face to making a smart move in the ancient Asian strategy game of Go. Prior to ML, this inability to articulate our own knowledge meant that we couldn’t automate many tasks. Now we can.
인식/Perception의 영역에서 발전 (dictation, image인식)
두번째, 과거의 사례에서 배운다.
The machine learns from examples, rather than being explicitly programmed for a particular outcome. This is an important break from previous practice. For most of the past 50 years, advances in information technology and its applications have focused on codifying existing knowledge and procedures and embedding them in machines. Indeed, the term “coding” denotes the painstaking process of transferring knowledge from developers’ heads into a form that machines can understand and execute. This approach has a fundamental weakness: Much of the knowledge we all have is tacit, meaning that we can’t fully explain it. It’s nearly impossible for us to write down instructions that would enable another person to learn how to ride a bike or to recognize a friend’s face.
Second, ML systems are often excellent learners. They can achieve superhuman performance in a wide range of activities, including detecting fraud and diagnosing disease. Excellent digital learners are being deployed across the economy, and their impact will be profound.
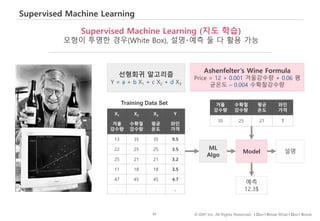
#97 he machine is given lots of examples of the correct answer to a particular problem
#98 ‘Ashenfelter, an economist at Princeton
‘He downloaded thirty years of weather data on the Bordeaux region. He also collected auction prices of wines. The auctions, which occur many years after the wine was originally sold, would tell you how the wine turned out.’
https://www.forbes.com/sites/sap/2014/04/30/how-big-data-can-predict-the-wine-of-the-century/1
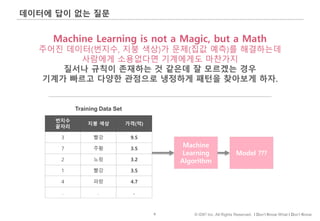
#104 풀어야 하는 문제가 예측이냐 설명이냐에 따라 기계학습 알고리즘이 달라집니다.
의사결정 빈도가 너무 빈번해서 비용 상의 이유로 의사결정을 할 수 없었던 영역이 예측비용의 하락으로 가능해졌다..
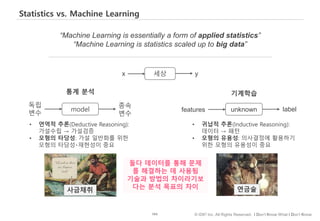
#105 데이터 분석이 x->y 로 가는 mapping 과정을 발견하는 일이라면
통계분석은…
기계학습은…
사금채취: 실험과 반복을 통해 반복가능한 방법을 통해 금을 얻는데 만족이 있다면
연금술: 금 채취의 과정이나 어떻게 금이 나왔냐에 대한 납득할만한 설명보다는, 금이 신기하게도 나온다는 결과에서 만족을 찾는 작업이라고 할 수 있습니다.
[끝]
그럼, 이것으로 기계학습과 기업 내 의사결정에 대한 강의를 마치도록 하겠습니다.
다음 강의에서는 회귀분석의 개념과 원리에 대해 이야기를 나누어 보겠습니다.
감사합니다.
참고: https://svds.com/machine-learning-vs-statistics/
사회과학 증명의 게임
#108 지도기계학습을 분리하는 또다른 방법은
Y값이 숫자인 경우 Y값을 예츳하는 Regression 모델
Y값이 Yes/No와 같이 범주인 경우 Y값을 예측하는 Classification으로 나눌 수 있고
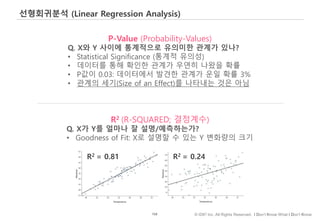
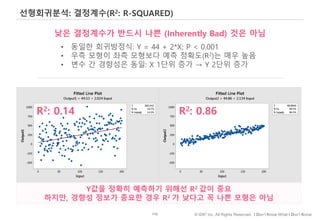
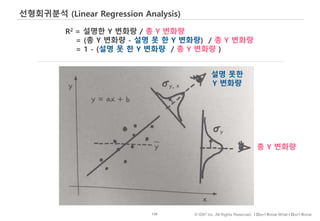
선형회귀분석은 가장 역사가 깊고, 결과를 이해하기 쉬운, 고전과도 같은,Regression 모델입니다.
그래서, 일부 학자들은 50년 후에도 살아남을 ML 알고리즘을 하나 꼽으라면 선형회귀분석을 꼽기도 합니다.
아래 그림과 같이
몸무게를 가지고 키를 예측/설명하고자 하는 경우
선형회귀방정식은 직선과 실제 관측점 사이의 차이가 최소화 되도록 최선의 직선을 귿는 일이라고 할 수 있습니다.
수많은 직선 중, Fit이 가장 좋은 직선을 내부 수학공식을 통해 찾게 되는 것이고
계산의 결과 회귀방정식은 아래와 같이 나오게 됩니다.
b0은 절편,
b1 기울기...
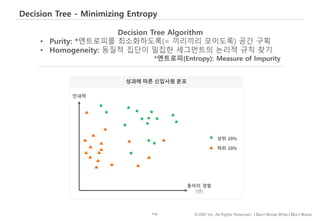
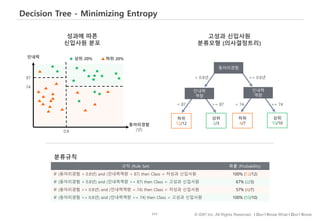
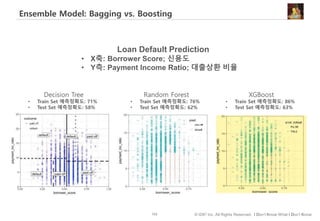
#121 Decision tree와 random forest 통해 화이트, 블랙 차이점
의사결정트리는 스무고개처럼…연속된 질문을 통해 정답을 찾아가는 방법입니다.
군인여부 Yes/No
남자 입니까? 예
20세 이상~25세 이하입니까? 예
머리가 짧습니까? 예
군인
랜덤포리스트는 개별 트리의 정확성을 높이기 위해…여러개의 트리 실제는 수백개의 트리를 만든 후…결과를 취합하여 투표…
#122 the bootstrap method refers to random sampling with replacement
https://medium.com/@SeattleDataGuy/how-to-develop-a-robust-algorithm-c38e08f32201
#123 Decision tree와 random forest 통해 화이트, 블랙 차이점
의사결정트리는 스무고개처럼…연속된 질문을 통해 정답을 찾아가는 방법입니다.
군인여부 Yes/No
남자 입니까? 예
20세 이상~25세 이하입니까? 예
머리가 짧습니까? 예
군인
랜덤포리스트는 개별 트리의 정확성을 높이기 위해…여러개의 트리 실제는 수백개의 트리를 만든 후…결과를 취합하여 투표…
#135
글자크기
[아침햇살] 산불 나면, 보험회사 돈번다
반기성 조선대 대학원 겸임교수
에너지경제ekn@ekn.kr 2016.09.26 19:08:23
▲반기성 조선대 대학원 겸임교수
[아침햇살] 산불 나면, 보험회사 돈번다 일본 속담에 ‘바람이 많이 불면 나무통 가게가 돈을 번다’는 속담이 있다. 왜 그럴까? 꼭 기차놀이 같은 답이 이어진다. 바람이 불면 먼지가 많이 발생한다. 먼지가 많아지면 눈병이 많이 생긴다. 눈병이 많아지면 실명하는 사람이 많아진다. 맹인은 삼미선을 연주하면서 다닌다. 삼미선은 고양이 가죽으로 만든다. 고양이를 많이 잡으면 쥐가 많아진다. 쥐가 늘어나면 나무통을 갉아먹는다. 결국 통이 많이 팔린다는 이야기다.
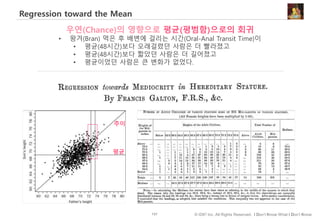
#138 https://www.farnamstreetblog.com/2015/07/regression-to-the-mean/
why it is that highly intelligent women tend to marry men who are less intelligent than they are?
The rule goes that, in any series with complex phenomena that are dependent on many variables, where chance is involved, extreme outcomes tend to be followed by more moderate ones.
In statistics, regression toward (or to) the mean is the phenomenon that if a variable is extreme on its first measurement, it will tend to be closer to the average on its second measurement—and if it is extreme on its second measurement, it will tend to have been closer to the average on its first
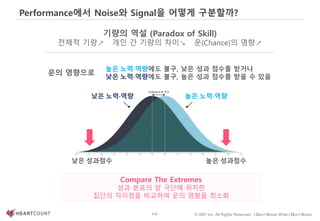
기량의 역설??? 운의 영향






![12 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
큰 데이터
Smaller Data
[Asset; 독점]
Bigger Data
[Liability]
개별 레코드에 담긴 패턴(효과/시그널)이 클수록
패턴 발견을 위해 적은 데이터가 필요](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-12-320.jpg)


![15 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
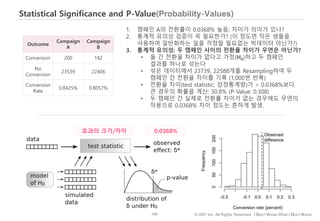
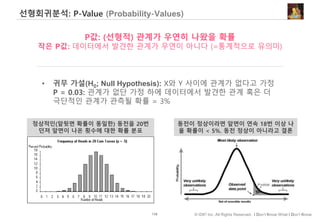
P-Value (Probability-Values)
P값: (선형적) 관계가 우연히 나왔을 확률
작은 P값: 데이터에서 발견한 관계가 우연이 아니다 (=통계적으로 유의미)
• 귀무 가설(H0; Null Hypothesis): [공직에 있는 민주당 정
치인의 숫자]와 [경기지표] 사이에 선형적 관계가 없다.
• P = 0.05: 관계가 없단 가정 하에 데이터에서 발견한 관계
혹은 더 강한 관계가 관측될 확률 = 5%
• 관계가 없을 때 해당 관계가 우연히 관찰될 확률
• 확률이 5%보다 작으면 관계가 있다고 결론](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-15-320.jpg)







![28 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
Data Literacy: Fixing Last Mile Problem
Last Mile Problem
기업이 데이터에서 쓸모있는 패턴을 발견하여
더 좋은 의사결정에 활용하지 못하는 문제
Last Mile
원인
• 분석 부재: 엑셀보고; 대쉬보드
• 분석 분리: 현업과 분석가의 분리;
[질문→분석→활용] 선순환 X
해결책
• 현업 스스로 데이터에 질문,
패턴 발견‧해석‧활용
• Data Literacy + Right Tool
질문 데이터 분석 활용해석](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-28-320.jpg)

![33 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
Data → It’s Funny → Data Literacy -> Insight
1962년과 1979년에 태어난 남자들은 왜 Mets구단 팬이 되었나?
Hint: 1969년과 1986년에 모두 8세가 되었음
1969년
8세
출생년도에 따른 NY Mets 팬들 비율
[대상: 뉴욕 거주하는 남자 야구 팬들]
1986년
8세](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-33-320.jpg)
![34 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
Data → It’s Funny → Data Literacy -> Insight
Reality
• Reality: 복잡계; 실제 작동방식 100% 알 수 없음
• Belief: 세상의 작동방식에 대한 최선의(만족스러운) 설명
• Data: 세상의 작동방식에 대한 기록; 세상의 샘플링
• Insight: 세상에 대한 더 나은 설명, 새로운 해석
Belief Data
Insight
[or Inspiration?]
희한하네… 보따리 장수
매출 매출 매출
데이터를 읽을 수 있어야 새로운 해석도 가능](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-34-320.jpg)











![53 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
The Philosophy of Statistics [19th Century]
초기의 통계학 - 결정론적 세계관에 바탕을 둔 이데아/본질의 추구
평균값이 대상이 보유한 이상적인 속성이고(Idealized Mean)
Variation(차이)은 제거해야 할 오류라는 생각이 지배적이었음
Species(종; 種): An Ideal Type](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-53-320.jpg)
![54 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
Darwin and Statistical Population [Late 19th~Early 20th Century]
다윈의 등장: Type/Essence(본질) → Variation(차이)
차이(변이)의 점진적 누적에 의해 진화가 이루어진다는 발견
개별 개체에 존재하는 의미있는 차이(변이)에 관심을 갖기 시작](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-54-320.jpg)




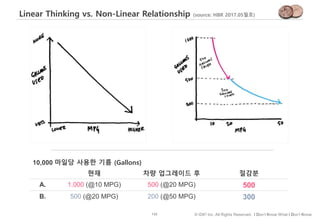
![60 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
평균의 문제 - Linear Thinking vs. Non-Linear Relationship
잠재 고객
세그먼트
환경 관심도
평균 점수
A 4
B 3
A = [4, 4, 4, 4, 4, 4, 4, 4]
B = [1, 1, 1, 1, 5, 5, 5, 5]
친환경 제품을 출시하려 한다.
어떤 세그먼트에 프로모션할까?
잠재 고객
세그먼트
환경 관심도
가중 평균 점수
A 4
B 5.5
A = [4, 4, 4, 4, 4, 4, 4, 4]
B = [1, 1, 1, 1, 5, 5, 5, 5, 5, 5, 5, 5]
5점에 가중치 2를 부여](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-60-320.jpg)

![62 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
Histogram vs. Frequency Distribution Table
계급 (0,3] (3,6] (6,9] (9,12] (12,15] (15,18] (18,21] (21,24] (24,27] (27,30] (30,33] (33,36] (36,39] (39,42] (42,45] (45,48]
빈도 26.0 17.0 15.0 32.0 34.0 51.0 55.0 56.0 55.0 60.0 58.0 43.0 18.0 14.0 5.0 2.0
누적
빈도
26.0 43.0 58.0 90.0 124.0 175.0 230.0 286.0 341.0 401.0 459.0 502.0 520.0 534.0 539.0 541.0
비율 4.8 3.1 2.8 5.9 6.3 9.4 10.2 10.4 10.2 11.1 10.7 7.9 3.3 2.6 0.9 0.4
누적
비율
4.8 7.9 10.7 16.6 22.9 32.3 42.5 52.9 63.1 74.2 84.9 92.8 96.1 98.7 99.6 100.0
히스토그램과 도수분포표](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-62-320.jpg)
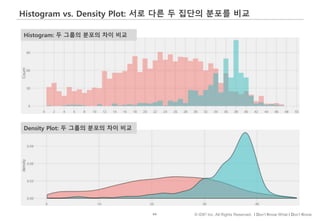
![63 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
Histogram vs. Density Plot
Probability Density Curve
Histogram – Bin Size: 1시간
Histogram – Bin Size: 4시간1
2
3
1
2
3
히스토그램: 도수(빈도)의 분포[도수분포표]
를 차트로 표현한 것
계급: X축에 표현된 변수의 구간[4시간]
X축 변수 구간의 크기(Bin Size)를 4시간에
서 1시간으로 조정하였음
확률밀도: X가 연속형 변수일 경우 X값과
이에 대응하는 확률을 나타낸 그래프
좌측에서 X가 10~20시간 사이의 값을 가
질 확률은 해당 구간의 면적과 동일함](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-63-320.jpg)
![67 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
Percentile
Score
[정렬된 점수]
Percentile
Rank
Quartile
[사분위]
29 8th
Q1, 1사분위
(최하위 25%)
32 17th
38 25th
41 33th
Q2, 2사분위
(차하위 25%)
53 42th
54 50th
55 58th
Q3, 3사분위
(차상위 25%)
74 67th
93 75th
99 83th
Q4, 4사분위
(최상위 25%)
134 92th
209 100th
Percentile: 전체 관측값들의 분포를 고려했을 때 특정값의 상대적 위치
내 키가 185cm로 20명 중
네번째로 키가 크다면
185cm = 80th Percentile
내 밑으로 80%가 있다!](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-67-320.jpg)
















![112 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
Multiple Linear Regression Analysis – Advertisement
이번에는 변수 2개[TV, Radio]를 사용하여 Sales와의 관계를
설명‧예측하는 회귀모형을 만들어 봅시다.
Y = b0 + b1X1 + b2X2
Sales = 2.9 + 0.045 x TV + 0.187 x Radio
강의 보조자료 참고](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-112-320.jpg)







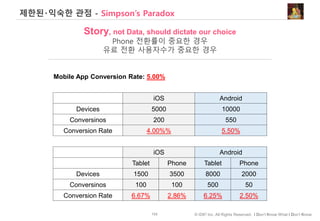

![135 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
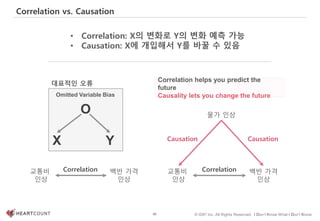
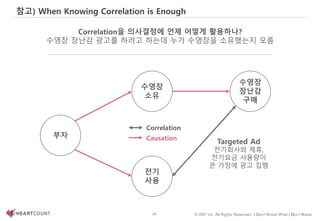
Correlation을 언제 의사결정에 활용해야 하나?
관계에 대한
높은 확신
(인과관계)
데이터를 통해 [소고기와 우유]를 구매한 고객들의 자동차 사고 발생률이
[라면과 소주]를 구매한 고객보다 높은 걸 확인했다. 보험회사가 취할 행동은?
관계에 대한
낮은 확신
실>득 실<득
가. 구매패턴에 따른
보험료 차등 적용
나. 저위험군 고객들
타겟 마켓팅
Act
Don’t Act](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-135-320.jpg)
![136 © IDK2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
Correlation을 언제 의사결정에 활용해야 하나?
관계에 대한
높은 확신
(인과관계)
관계에 대한
낮은 확신
실>득 실<득
가. 구매패턴에 따른
보험료 차등 적용
나. 저위험군 고객들
타겟 마켓팅
Act
Don’t Act
가. 구매패턴에 따른
보험료 차등 적용
나. 저위험군 고객들
타겟 마켓팅
데이터를 통해 [소고기와 우유]를 구매한 고객들의 자동차 사고 발생률이
[라면과 소주]를 구매한 고객보다 높은 걸 확인했다. 보험회사가 취할 행동은?
X O](https://image.slidesharecdn.com/dataliteracy-180626125547/85/Data-Literacy-136-320.jpg)







![[정보 디자인 교과서] 2-1 정보의 조직화](https://cdn.slidesharecdn.com/ss_thumbnails/informationdesignchapter2-1-111108093609-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DevGround] 린하게 구축하는 스타트업 데이터파이프라인](https://cdn.slidesharecdn.com/ss_thumbnails/devgroundkmongrevisedcraig190627finalscriptformatted-190828020444-thumbnail.jpg?width=640&height=640&fit=bounds)






![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)






![[도서 리뷰] 헤드 퍼스트 데이터 분석 ( Head First Data Analysis )](https://cdn.slidesharecdn.com/ss_thumbnails/headfirstdataanalysis-181125114351-thumbnail.jpg?width=640&height=640&fit=bounds)







![[통계페스티발] 무덤에서 요람까지 통계와 함께](https://cdn.slidesharecdn.com/ss_thumbnails/20151217-151221153120-thumbnail.jpg?width=640&height=640&fit=bounds)






![[팝콘 시즌1] 윤석진 : 조직의 데이터 드리븐 문화를 위해 극복해야하는 문제들](https://cdn.slidesharecdn.com/ss_thumbnails/papcondatadriveculture-220221140458-thumbnail.jpg?width=640&height=640&fit=bounds)



![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [OnLog]: Real-time Edge-to-Cloud Data Pipeline fo...](https://cdn.slidesharecdn.com/ss_thumbnails/3-4boaz23rdconferenceonlog-260204093729-11983ba7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [F4] : 시켜줘, 금잔디 명예 플로리스트](https://cdn.slidesharecdn.com/ss_thumbnails/3-3boaz23rdconferencef4-260204011323-1cb48ec9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)