Download to read offline





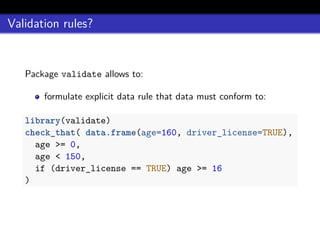


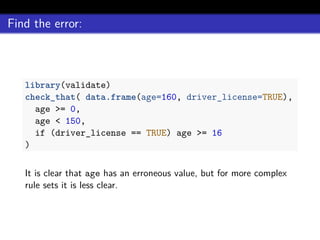


![errorlocate::locate_errors
locate_errors( data.frame( age = 3
, married = TRUE
, attends = "kindergarten"
)
, validator( if (married == TRUE) age >= 16
, if (attends == "kindergarten") age <= 6
)
)$errors
## age married attends
## [1,] FALSE TRUE FALSE](https://image.slidesharecdn.com/lightning-170707092748/85/Data-error-But-where-11-320.jpg)
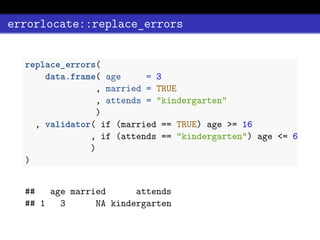

This document discusses using validation rules to check data and locate errors. It introduces the errorlocate package, which can formulate validation rules using validate and then locate errors in data that violate those rules. Errorlocate uses an algorithm based on Feligi Holt formalism to identify the minimal number of variable changes needed to satisfy all validation rules. It provides functions to both locate errors and replace errors in data. The package aims to automate the error localization process for large datasets with complex validation rule sets.







![[Tho Quan] Fault Localization - Where is the root cause of a bug?](https://cdn.slidesharecdn.com/ss_thumbnails/thoquanfaultlocalization-whereistherootcause-140717230902-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






















































