
Download as PDF, PPTX









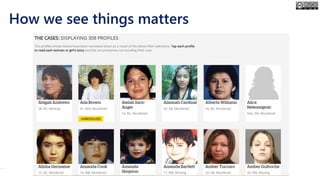
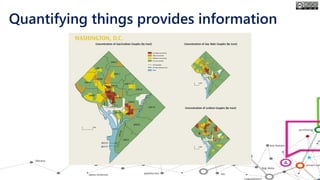



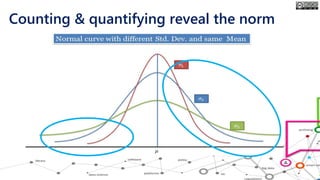

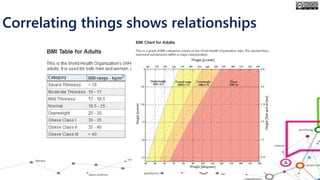
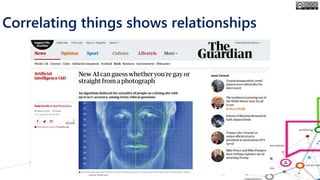

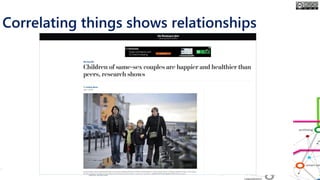
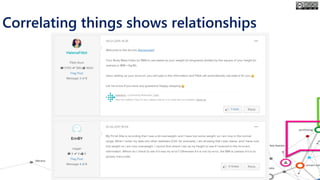






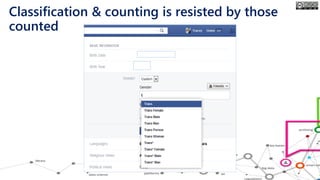


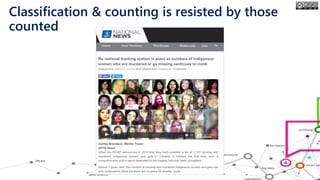

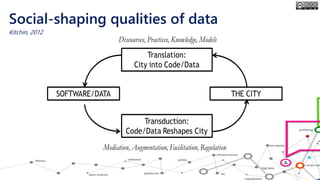
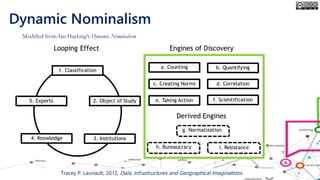
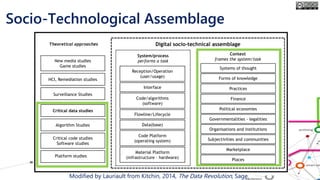

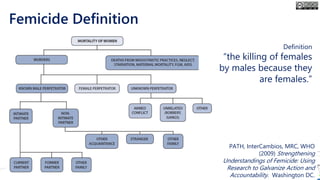







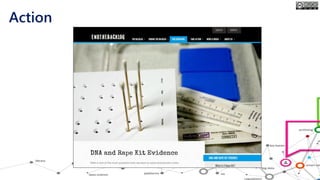
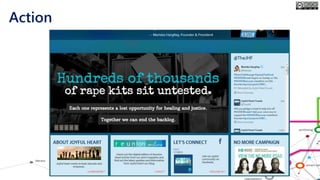

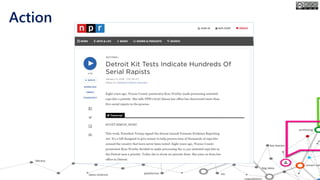


The document outlines the course structure for 'Media, Gender, and Sexuality' at Carleton University, focusing on the importance of counting and quantifying social issues like femicide and domestic violence. It emphasizes how data influences perceptions and actions regarding societal norms, specifically in the context of demographics and violence against women. Additionally, it addresses the challenges and methodologies in accurately collecting and interpreting data to inform advocacy and policy.

















































































